Download

1 / 57
570 likes | 589 Views
Explore the concepts of data mining and web mining in the context of business system analysis and decision making. Learn how to construct decision trees using SAS Enterprise Miner and discover meaningful patterns in large amounts of data.

E N D
Business System Analysis & Decision Making – Data Mining andWeb Mining Zhangxi Lin ISQS 5340 Summer II 2006
Outline • Introduction to data mining & text mining • Constructing a decision tree using SAS Enterprise Miner • Web mining
Review - Decision Tree (1) Total: 2 Accept: 2 Reject: 0 Accuracy: 100% Coverage: 50% Yes Total: 5 Accept: 3 Reject: 2 Accuracy: 60% Coverage: 75% Credit Card Insurance Female Total: 3 Accept: 1 Reject: 2 Accuracy: 33.3% Coverage: 25% Total: 10 Accept: 4 Reject: 6 Accuracy: 40% Coverage: 100% No Gender Total: 5 Accept: 1 Reject: 4 Accuracy: 20% Coverage: 25% Male
Review - Decision Tree (2) Total: 2 Accept: 2 Reject: 0 Accuracy: 100% Coverage: 50% Female Total: 4 Accept: 3 Reject: 1 Accuracy: 75% Coverage: 75% Gender Yes Total: 2 Accept: 1 Reject: 1 Accuracy: 50% Coverage: 25% Total: 10 Accept: 4 Reject: 6 Accuracy: 40% Coverage: 100% Male Credit Card Insurance Total: 6 Accept: 1 Reject: 5 Accuracy: 16.7% Coverage: 25% No What are the differences of this decision tree from the last one?
Confusion Matrix (Rule: “Gender=Female”) Computed Accept Computed Reject Coverage = 3 / (3 + 1) = 0.75 Actual Accept 1 3 Actual Reject 2 4 5 Accuracy = 3 / (2+3) =0.6 5
Confusion Matrix (Rule: “Credit Promotion = Yes”) Computed Accept Computed Reject Coverage = 3 / (3 + 1) = 0.75 Actual Accept 1 3 Actual Reject 1 5 4 Accuracy = 3 / (1+3) =0.75 6
Generalizing data analysis ideas • Question: How to useful rule from a large amount of data generated in business operations? • Answer: Applying data mining techniques/tools
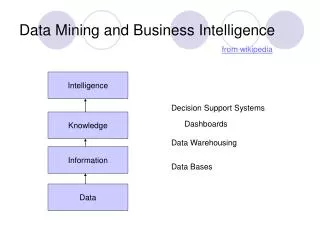
What is Data Mining? (See Wikipedia data mining) • Many Definitions • Non-trivial extraction of implicit, previously unknown and potentially useful information from data • Exploration & analysis, by automatic or semi-automatic means, of large quantities of data in order to discover meaningful patterns
Origins of Data Mining • Draws ideas from machine learning/AI, pattern recognition, statistics, and database systems • Traditional Techniquesmay be unsuitable due to • Enormity of data • High dimensionality of data • Heterogeneous, distributed nature of data Statistics/AI Machine Learning/ Pattern Recognition Data Mining Database systems
Why Mine Data? Commercial Viewpoint • Lots of data is being collected and warehoused • Web data, e-commerce • purchases at department/grocery stores • Bank/Credit Card transactions • Computers have become cheaper and more powerful • Competitive Pressure is Strong • Provide better, customized services for an edge (e.g. in Customer Relationship Management)
Why Mine Data? Scientific Viewpoint • Data collected and stored at enormous speeds (GB/hour) • remote sensors on a satellite • telescopes scanning the skies • microarray s generating gene expression data • scientific simulations generating terabytes of data • Traditional techniques infeasible for raw data • Data mining may help scientists • in classifying and segmenting data • in Hypothesis Formation
Data Mining Tasks • Prediction Methods • Use some variables to predict unknown or future values of other variables. • Description Methods • Find human-interpretable patterns that describe the data. From [Fayyad, et.al.] Advances in Knowledge Discovery and Data Mining, 1996
Data Mining Tasks... • Classification [Predictive] • Clustering [Descriptive] • Association Rule Discovery [Descriptive] • Sequential Pattern Discovery [Descriptive] • Regression [Predictive] • Deviation Detection [Predictive]
What Text Mining Is (See Wikipedia text mining) • Text mining is a process that employs a set of algorithms for converting unstructured text into structured data objects and the quantitative methods used to analyze these data objects. • “SAS defines text mining as the process of investigating a large collection of free-form documents in order to discover and use the knowledge that exists in the collection as a whole.” (SAS Text Miner: Distilling Textual Data for Competitive Business Advantage)
A simple text mining example • A tiny case - 9 documents • deposit the cash and check in the bank - Fin • the river boat is on the bank - Riv • borrow based on credit - Fin • river boat floats up the river - Riv • boat is by the dock near the bank - Riv • with credit, I can borrow cash from the bank - Fin • boat floats by dock near the river bank - Riv • check the parade route to see the floats - Par • along the parade route - Par
Text Mining Strengths • Clustering documents in a corpus • Investigating word (token) distribution across documents within a corpus • Identifying words with the highest discriminatory power • Classifying documents into predefined categories • Integrating text data with structured data to enrich predictive modeling endeavors
Text Mining Deficiencies • Text mining algorithms perform poorly in distinguishing negations, for example: • Herman was involved in a motor vehicle accident. • Herman was NOT involved in a motor vehicle accident • Text mining cannot generally make value judgments, for example, classifying an article as positive or negative with respect to any tokens it contains. • Text mining algorithms do not work well with large documents. • Performance is slow. • Increased term occurrence across documents decreases separation of documents.
Using Data Mining Tools • Statistics Analysis System (http://www.sas.org) “SAS®9 is the most recent release of SAS. It delivers analytical, data manipulation and reporting capabilities within a completely new framework. ” • SPSS (http://www.spss.com) “SPSS customers include telecommunications, banking, finance, insurance, healthcare, manufacturing, retail, consumer packaged goods, higher education, government, and market research. ” • Weka, an open source software product (http://www.cs.waikato.ac.nz/ml/weka/ ) • Microsoft SQL Server comes with major data mining utilities • There are more…
SAS Enterprise Miner 4.3 • Basic • How to use the application main menu • Using the pop-up menus • Enterprise Miner documentation • Project – Diagram • The SEMMA methodology • Sample • Explore • Modify • Model • Assess
Exercise 5.0 • Explore SAS and SAS Enterprise Miner
Decision Tree Example • Life Insurance Promotion • Dataset CreditProm
Tree Algorithm: Find Best Split for Input Consider that the consumers in the life insurance promotion dataset have two attributes: credit card promotion, gender. Best Split x1 0.7 x1 X1 (Credit Prom) Missing in left branch Training Data Missing in right branch
Tree Algorithm: Repeat for Other Inputs X2 (Gender) Kass Adjusted Logworth 0.7 x2 Missing in left branch Training Data Missing in right branch
Tree Algorithm: Compare Best Splits x2 Best Split x1 Best Split x2 0.7 x1 Missing in left branch Training Data Missing in right branch
Tree Algorithm: Partition with Best Split Best Split x2 x1 Training Data
Tree Algorithm: Repeat within Partitions x2 x1 Training Data
Tree Algorithm: Partition with Best Split x2 x1 Training Data
Tree Algorithm: Construct Maximal Tree x2 x1 Training Data
Overfitting Overfitting We use training dataset to find the decision rules. These must be applicable to other datasets. In order to test the validity of the rules, a test dataset is used. Compare the outcomes between these two datasets, we can identify any inconsistency and create a good decision tree. Overfitting: The tree is split too much and the classification error rate is getting higher
Overfitting due to Insufficient Examples Lack of data points in the lower half of the diagram makes it difficult to predict correctly the class labels of that region - Insufficient number of training records in the region causes the decision tree to predict the test examples using other training records that are irrelevant to the classification task
How to Address Overfitting • Pre-Pruning (Early Stopping Rule) • Stop the algorithm before it becomes a fully-grown tree • We typically use two datasets: • Training dataset for growing the decision tree and obtaining rules • Test dataset for testing if the rules are good enough with regard to the errors rate when applying the rules from training dataset to the test dataset. • If there is no test dataset, the original dataset will be partitioned into two subsets for the above purpose.
Exercise 5 • Download the Life Insurance Promotion dataset (CreditProm) • Import the data to SAS • Try out SAS Decision Tree modeling
SAS Data Mining Example • A German Bank’s Credit Data • Online SAS materials (View PDF (2.24MB)) • P70, dataset description • P71, decision matrix
Case study: CarPort.com • CarPort.com is • a fictitious Web site that is used to illustrate components of Web site design and Web log analysis • a services Web site.
CarPort.com • Visitor profile could be any of the following: • 1. buyer looking for a car • 2. seller looking to sell a used car • 3. curious information seeker • 4. competitor • 5. robot or spider • 6. lost Web surfer • 7. SAS course developer.
CarPort.com • Services: • car locator (want ads) • car ownership information • Sources of revenue: • banner ads • used car ads • partnership agreements (fee for referral)
How Did You Get Here? • Followed a link from another site • Clicked on a banner ad • Did a Google search • Saw an advertisement on television, or heard one on radio • Received a direct mail solicitation • Received a phone solicitation • Heard the site mentioned or recommended on a news or specialty program, or read about it in the printed media
Title URL Images Links Banner Ad= Link+Image
Click on this link to find out more or e-mail the seller. Link to dealer’s Web site.
Web Mining for Profitability • Increase viewing, navigation, and transaction efficiency. • Improve the customer experience. • Add services and features that promote cross-selling and up-selling opportunities. • Identify problem areas. • Improve security. • Attract more high quality customers.
Michael Berry’s Internet Business Taxonomy • Classification is based on an Internet company’s business model, which may include: • selling things that get delivered in a truck • selling things that get delivered through the ether • selling eyes to advertisers • connecting sellers and buyers • empowering communities and collecting donations.
Some Business Questions • Who is visiting my Web site? • Who is buying my product(s)? • Who are my repeat buyers? • Which customers are churning? • Which Web design produces the most purchases? • What campaign strategies are most effective in increasing Web site visits?
More Questions • What factors influence product purchases? • Time-of-day effects • Gender, Age, Income, and so forth • Latent factors: e-shopper, Web expert, and so forth • Which sales channels produce the most profitable customers? • Do any site-visit patterns correlate with outcomes that can be exploited for business advantage?
Web Log Fields • User’s IP address, also called • Remote host name • Client IP address • User name, also called • Remote user log name (may be different) • Authenticated user name • Date and time of request, with or without a UTC offset • Request type, also called “method” • HTTP request with (CLF) or without (IIS) argument • Status: HTTP three digit status code • Number of bytes sent to client continued...
Web Log Fields • The URL path requested, if request type has no argument • The port to which the request was served • The name of the server • The IP address of the server • The time taken to serve the request • Number of bytes in the request received from the client • User agent, which is usually a text string with the name and version number of Web browser used by the client and the operating system of the client machine • The domain name or IP address of the referring URL • Query information in a text string • Cookie information in a text string
Common Log Format Value Example Remote Host Name 111.22.333.44 Remote User Log Name - Username IRVINE/terry Date 15/Apr/2000 Time and UTC Offset 11:28:14 -0700 Request Type GET /index.html HTTP/1.1 Service Status Code 200 Bytes Sent 2792