Download

1 / 43
430 likes | 536 Views
CISC3595 CPU Scheduling. Basic Concepts. Multiprogramming Load multiple program into memory, and run them simultaneously A process (or kernel-level thread) is executed until it must wait (for I/O completion, child exiting…), OS then switches to run another process (or thread)

E N D
Basic Concepts • Multiprogramming • Load multiple program into memory, and run them simultaneously • A process (or kernel-level thread) is executed until it must wait (for I/O completion, child exiting…), OS then switches to run another process (or thread) • Goal: improve CPU utilization
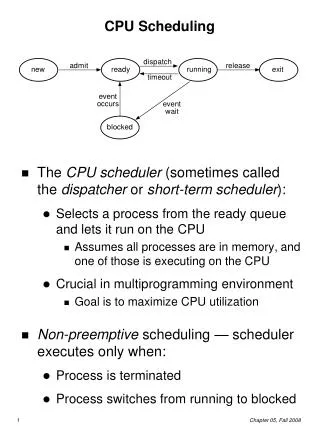
Process Scheduling • Short-term scheduling (CPU scheduling) • Select one process from ready queue to be executed • Medium-term scheduling, Long-term scheduling • What is ready queue ? • Contains PCB for all processes that lines up waiting for CPU • Not necessarily FIFO queue
Process Control Block (PCB): review 4 Information associated with each process • Process state • Program counter: • address of next instruction to be executed • CPU registers: • Contents of CPU registers • CPU scheduling information • Process priority, … • Memory-management information • Value of base and limit registers, page/segmentation tables (to be studied later) • Accounting information • Amount of CPU time used … • I/O status information • I/O device allocated, list of open files…
Context Switch: review P0, P1 are running concurrently, i.e., their executions are interleaved. 6
Process Scheduling Queues: review 7 • OS maintain multiple process queues for scheduling purpose: • Job queue – set of all processes in the system • Ready queue– set of all processes residing in main memory, ready and waiting to execute • Device queues– set of processes waiting for an I/O device • Processes migrate among the various queues
CPU and I/O Bursts • Process execution consists of a cycle of CPU execution and I/O wait • CPU burst: • Data processing, calculation • E.g. sorting, searching • I/O burst: • Read from I/O device • File system access • What about the myCopy program?
Histogram of CPU-burst Times A large number short CPU burst Small number of long CPU burst
CPU Scheduler • Selects one process from ready queue, and allocates CPU to execute it • When to make CPU scheduling : 1. a process switches from running to waiting state 2. a process switches from running to ready state 3. a Process switches from waiting to ready 4. a process terminates • Nonpreemptive scheme: only run CPU scheduling under 1 and 4 • i.e., current running process gives up CPU • Otherwise, preemptive scheduling scheme
Dispatcher module • Scheduler => Dispatcher • Dispatcher module: gives control of CPU to the process selected by short-term scheduler • switching context • switching to user mode • jumping to the proper location in the user program to restart that program • Dispatch latency – time it takes for the dispatcher to stop one process and start another running • Including context switching latency
CPU Scheduling Algorithms • First-come, First-Served Scheduling • Shortest-Job-First Scheduling • Priority Scheduling • Round-Robin Scheduling • Multilevel Queue Scheduling • Multilevel Feedback Queue Scheduling
CPU Scheduling Criteria • CPU utilization – percentage of time CPU is busy (not idle) • Throughput – # of processes that complete their execution per time unit • Turnaround time – amount of time to execute a particular process • From process submission to time of completion • Waiting time – amount of time a process has been waiting in ready queue • Response time – amount of time it takes from when a request was submitted until first response is produced (for time-sharing environment)
Optimization Criteria • Maximize CPU utilization • Maximize throughput • Minimize turnaround time • Minimize waiting time • Minimize response time • Achieved performance measure is random variable depending on the statistics of workload • Usually, optimize average measure (average case performance) • Sometimes, optimize minimum or maximum value (worst case performance) • Or sometimes, variance of the measure
P1 P2 P3 0 24 27 30 First-Come First-Served Scheduling Serve processes in the order of arrivals, non-preemptive ProcessBurst Time P1 24 P2 3 P3 3 • Suppose that processes arrive in the order: P1 , P2 , P3Gantt Chart for FCFS schedule is: • Waiting time for P1 = 0; P2 = 24; P3 = 27 • Average waiting time: (0 + 24 + 27)/3 = 17
P2 P3 P1 0 3 6 30 FCFS Scheduling (Cont.) ProcessBurst Time P1 24 P2 3 P3 3 Suppose that processes arrive in the order P2 , P3 , P1 • The Gantt chart for FCFS schedule is: • Waiting time for P1 = 6;P2 = 0; P3 = 3 • Average waiting time: (6 + 0 + 3)/3 = 3 • Much better than previous case • Short process behind long process
Exercise • Draw Gantt chart for FCFS schedule for the following set of processes arrived in the order of P1, P2, P3, P4. ProcessBurst Time P1 10 P2 4 P3 6 P4 5 • Average waiting time • What order of arrival of these processes will give smallest average waiting time ?
FCFS Scheduling • What will happen if the system has • one CPU-bound process • many I/O-bound processes • A Convoy effect happens when • a set of processes need to use a resource for a short time • one process holds the resource for a long time, blocking all of the other processes • Result: poor utilization of the other resources in the system. • Other problems of FCFS ? • Ill-suited for time-sharing systems (interactive environment)
Shortest-Job-First (SJF) Scheduling • Schedule process with shortest-next-CPU-burst (i.e., the length/duration of next CPU burst) • Two schemes: • nonpreemptive – once CPU given to the process it cannot be preempted until completes its CPU burst • preemptive – if a new process arrives with CPU burst length less than remaining time of current executing process, preempt. Also called Shortest-Remaining-Time-First (SRTF)
Shortest-Job-First (SJF) Scheduling 21 • Among non-preemptive scheduling algorithms, SJF achieves minimum average waiting time for a given set of processes that arrives at the same time. • Suppose the duration of CPU burst of n processes is l1,l2,…ln , li<lj for i<j, (it’s sorted in ascending order Assume the schedule that achieves minimum average waiting time is not SJF, it means that there exists at least a pair of processes, j and k, such that lj<lk, but process j is scheduled to run after process k The schedule: … lk … lj … We can switch lk and lj to decrease avg. waiting time. Assumption is wrong, and SJF achieves minimum avg. waiting time.
P1 P3 P2 P4 0 3 7 8 12 16 Example of Non-Preemptive SJF ProcessArrival TimeBurst Time P1 0.0 7 P2 2.0 4 P3 4.0 1 P4 5.0 4 • SJF (non-preemptive) • Average waiting time = (0 + 6 + 3 + 7)/4 = 4
P1 P2 P3 P2 P4 P1 11 16 0 2 4 5 7 Example of Preemptive SJF ProcessArrival TimeBurst Time P1 0.0 7 P2 2.0 4 P3 4.0 1 P4 5.0 4 • SJF (preemptive) • Average waiting time = (9 + 1 + 0 +2)/4 = 3
Length of Next CPU Burst ? • Predict next CPU burst length • Using length of previous CPU bursts, using exponential moving averaging
Examples of Exponential Averaging • =0 • n+1 = n,, recent history does not count • =1 • n+1 = tn, only previous CPU burst counts • Expand formula: • n+1 = tn+(1 - ) tn-1+ … +(1 - )j tn-j+ … +(1 - )n +1 0 • each successive term has less weight than its predecessor • Both and (1 - ) are less than or equal to 1
Priority Scheduling • CPU is allocated to process with the highest priority • A priority number (integer) is associated with each process • smallest integer highest priority • Can be Preemptive or Nonpreemptive • Preemptive: newly arrived higher priority process preempt current running process • Priority can be internal or external • Internal: decided based on some quantities of process • resource requirement, ratio of I/O burst and avg burst, next CPU bursts length • External: importance, funds paid,…
Priority Scheduling 28 • Problem of priority scheduling • Indefinite blocking, starvation: low priority processes may never execute • Solution • Aging – as time progresses increase the priority of the waiting process • E.g., increase the priority of a waiting process by 1 every 15 minutes…
Round Robin (RR) • So far, we see FCFS, SJF, Priority Scheduling • How they perform for time-sharing system ? • Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds. After this time has elapsed, the process is preempted and added to the end of the ready queue. • If there are n processes in ready queue and time quantum is q, then each process gets 1/n of CPU time in chunks of at most q time units at once. No process waits more than (n-1)qtime units.
P1 P2 P3 P4 P1 P3 P4 P1 P3 P3 0 20 37 57 77 97 117 121 134 154 162 Example of RR with Time Quantum = 20 ProcessBurst Time P1 53 P2 17 P3 68 P4 24 • The Gantt chart is: • Typically, higher average turnaround than SJF, but better response
Round Robin (RR) 31 • Choosing q, time quantum • q large FIFO • q small processor sharing • Downside of having very small q ? • q must be large with respect to context switch, otherwise overhead is too high
Multilevel Queue • Ready queue is partitioned into separate queues • Realtime process • foreground (interactive) process • background (batch) process • Each queue has its own scheduling algorithm • Realtime – Earliest Deadline First • foreground – RR • background – FCFS • Scheduling must be done between queues • Fixed priority scheduling; (i.e., serve all from realtime, then foreground, then from background). • Low priority process might experience starvation • Time slice – each queue gets a certain amount of CPU time • i.e., 80% to foreground in RR, 20% to background in FCFS
Multilevel Queue Scheduling How do we assign process to appropriate queue ?
Multilevel Feedback Queue Scheduling • Compared to multilevel queue scheduling • A process can move between various queues; aging can be implemented this way • To favor shorter jobs, or process with short CPU burst • Penalize process that have been run longer by moving it to lower priority queue … • Feed the process back to a different queue
Example of Multilevel Feedback Queue I/O, terminate Process becomes ready Timer goes off I/O, terminate I/O, terminate • Q0 – RR with quantum 8 milliseconds • Q1 – RR quantum 16 milliseconds • Q2 – FCFS • Strict priority among queues Q1>Q2>Q3
Multilevel Feedback Queue • Effect of multilevel feedback queue • I/O bound and interactive processes stay in highest priority queue • CPU bound process stays in low priority queue • Multilevel-feedback-queue scheduler defined by the following parameters: • number of queues • scheduling algorithms for each queue • method used to determine when to upgrade a process • method used to determine when to demote a process • method used to determine which queue a process will enter when that process needs service
Multiple-Processor Scheduling • CPU scheduling more complex when multiple CPUs are available • Homogeneous processors within a multiprocessor • Two appraches • Symmetric multiprocessing: each processor is self-scheduling • Share a common queue, or private queue • Asymmetric multiprocessing: one processor (master server) handles scheduling decision, I/O Processing, and other system activities • – only one processor accesses the system data structures, alleviating the need for data sharing
Multiple-Processor Scheduling: considerations • Recall L1 cache ? • To avoid cache invalidation and repopulation, scheduling taking into account processor affinity: a process has an affinity to the processor that it is currently running on • Avoid migrating a process to other processor • Load balancing: keep workload balanced among processors • Needed if each processor has its private queue • Push migration and pull migration
Real-Time Scheduling • Hard real-time systems – required to complete a critical task within a guaranteed amount of time • Soft real-time computing – requires that critical processes receive priority over less fortunate ones
Thread Scheduling • Local Scheduling – How the threads library decides which thread to put onto an available LWP • Global Scheduling – How the kernel decides which kernel thread to run next
Case studies: Windows XP and Linux • Homework: comparing CPU scheduling used by Windows XP and Linux • Details to come • Evaluation of different CPU scheduling algorithms • By hand • Through mathematical model • Through simulation studies • Actual Implementation and measurement