Download

1 / 19
200 likes | 312 Views
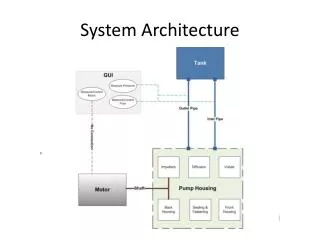
Nova System Architecture. Metadata Database. Modules are stateless Keep state externally Shared among multiple instances No sync instead round robin policy. Watchdog. Via Zookeeper Leader election Detects unresponsive server instances & kill them Start new replacements

E N D
Metadata Database • Modules are stateless • Keep state externally • Shared among multiple instances • No sync instead round robin policy
Watchdog • Via Zookeeper • Leader election • Detects unresponsive server instances & kill them • Start new replacements • Reconfigure load balancer’s routing table
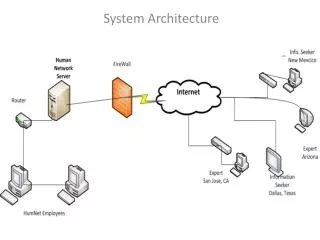
Clients Types • Human clients via command line interface • Web interface via SOAP • NOVA is part of larger environment • Data onboarding and data serving interact with NOVA
User Interface • Provides API for registering channels and workflowettes • Binds workflowettes to channels • (de)registers triggers and insertion of new blocks to channels • Monitors workflowettes execution status -Workflowetts are written in a variant XPDL to describe a directed graph of processing steps
Process manager • Keeps track of registered & bound workflowettes • Responds to trigger events by creating executable instance of workflowettes • Pass executable instance of workflowettesto process executor & has their execution status
Data manager • Maintains list of blocks associated with each channel & task input cursor. • When process manager prepare to execute workflowette, data manager does: • Create pig latin expressions • Reserve output block positions
Process optimizer • Currently implemented: • Merging pairs of workflowette executions that read the same input data and run in the same time • Future plan: • Pipelining workflowettes that form a “chain”
Process executor • Forward execution requests to Oozie(run pig jobs) • Track execution status • Report the execution status back to process manager
Trigger manager • Runs its own tread & fires triggers • Uses metadata DB to avoid conflicts with other concurrent Nova server instances • Triggers cause a workflowette to run via requests to process manager • Triggers garbage collection events that are performed by data manager
Data & metadata replicator • Cross-data-center replication is asynchronous & one way ( stand-by instance) for: • Fail-over • Migration • In Nova complicated, cause data is stored in two places with enormous links • Avoids creating dangling references by: • keep track of references & delaying the replay of transactions until all referenced HDFS files are copied
Scan sharing • Workflowettes scheduled independently, but often multiple workflowette executions that read same data are triggered almost in the same time. • “Load” operation is used once across different workflowettes. • Merging is governed in XML workflowette by : • “ Mergeable ” annotation • “ Maximam queue time “ • Only workflowettes that use ALL consumption mode are supported.
Experiments • Incremental Processing: • Merge overhead • Different block sizes • Incremental Vs. non-incremental Join • Scan Sharing
Merge overhead • Merge function that co-groups records by a key, then applies UDF to examine each record • Pig offers 2 alg. For physical co-group: • Map-side • Reduce-side
Merge overhead “we have not been able to pin down the source of this per-block overhead, i.e. whether it lies mostly in opening an HDFS file or in Pig's le handling code.” • Question: Given a data set with fixed size, how much difference does it make to divide it into large number of small blocks or small number of large blocks?? • Depends on the size of the data size • if large data set the difference is small , • If small data set the difference is large.
Incremental Vs. non-incremental Join • (old A JOIN new B) U (new A JOIN old B) U (new A JOIN new B), which emits a delta block of the join result VS. (All A JOIN All B) • this experiment sorts the data by the join key and bulk-loads it into Zebra (a sorted and sparsely-indexed Hadoopfile format) files and then runs a map-side join.