Download
1 / 1
60 likes | 228 Views
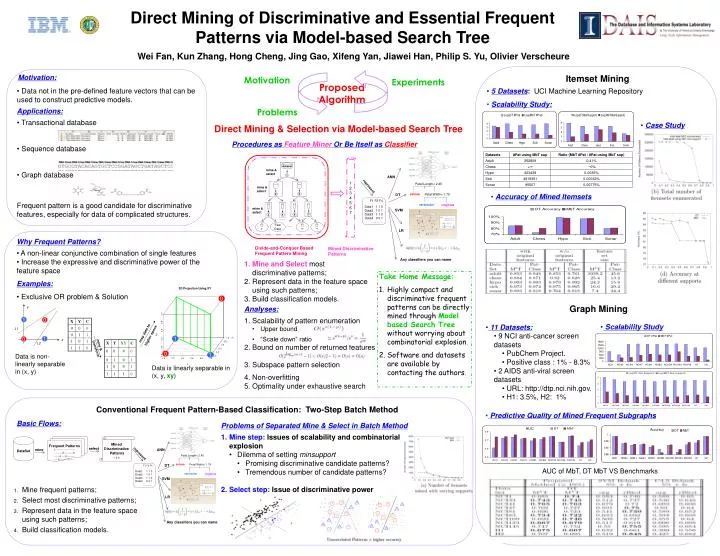
0. represent. ANN. Petal.Length< 2.45. |. F1 F2 F4 Data1 1 1 0 Data2 1 0 1 Data3 1 1 0 Data4 0 0 1 ………. 1. DT. setosa. Petal.Width< 1.75. versicolor. virginica. 0. 1. SVM. LR. ANN. Petal.Length< 2.45. |. represent. DT. setosa. Petal.Width< 1.75.

E N D
0 represent ANN Petal.Length< 2.45 | F1 F2 F4 Data1 1 1 0 Data2 1 0 1 Data3 1 1 0 Data4 0 0 1 ……… 1 DT setosa Petal.Width< 1.75 versicolor virginica 0 1 SVM LR ANN Petal.Length< 2.45 | represent DT setosa Petal.Width< 1.75 F1 F2 F4 Data1 1 1 0 Data2 1 0 1 Data3 1 1 0 Data4 0 0 1 ……… Any classifiers you can name versicolor virginica SVM LR Any classifiers you can name Direct Mining of Discriminative and Essential Frequent Patterns via Model-based Search Tree Wei Fan, Kun Zhang, Hong Cheng, Jing Gao, Xifeng Yan, Jiawei Han, Philip S. Yu, Olivier Verscheure Motivation: Itemset Mining Motivation Experiments Proposed Algorithm • Data not in the pre-defined feature vectors that can be used to construct predictive models. • Applications: • Transactional database • Sequence database • Graph database • Frequent pattern is a good candidate for discriminative features, especially for data of complicated structures. • 5 Datasets:UCI Machine Learning Repository • Scalability Study: Problems Direct Mining & Selection via Model-based Search Tree • Case Study Procedures asFeature MinerOr Be Itself asClassifier 1 2 3 4 5 6 7 dataset mine & select 1 mine & select • Accuracy of Mined Itemsets 5 2 mine & select 6 7 3 4 …….. Few Data + + …….. • Why Frequent Patterns? • A non-linear conjunctive combination of single features • Increase the expressive and discriminative power of the feature space • Examples: • Exclusive OR problem & Solution Divide-and-Conquer Based Frequent Pattern Mining Mined Discriminative Patterns • Mine and Select most discriminative patterns; • Represent data in the feature space using such patterns; • Build classification models. • Take Home Message: • Highly compact and discriminative frequent patterns can be directly mined throughModel based Search Treewithout worrying about combinatorial explosion. • Software and datasets are available by contacting the authors. Graph Mining y • Analyses: • Scalability of pattern enumeration • Upper bound • “Scale down” ratio • Bound on number of returned features • Subspace pattern selection • Non-overfitting • Optimality under exhaustive search map data to higher space 1 0 • Scalability Study • 11 Datasets: • 9 NCI anti-cancer screen datasets • PubChem Project. • Positive class : 1% - 8.3% • 2 AIDS anti-viral screen datasets • URL: http://dtp.nci.nih.gov. • H1: 3.5%, H2: 1% L1 1 0 x L2 mine & transform Data is non-linearly separable in (x, y) Data is linearly separable in (x, y, xy) Conventional Frequent Pattern-Based Classification: Two-Step Batch Method • Predictive Quality of Mined Frequent Subgraphs Basic Flows: • Problems of Separated Mine & Select in Batch Method • Mine step:Issues of scalability and combinatorial explosion • Dilemma of setting minsupport • Promising discriminative candidate patterns? • Tremendous number of candidate patterns? • Select step:Issue of discriminative power AUC DataSet Frequent Patterns 1---------------------- ---------2----------3 ----- 4 --- 5 -------- --- 6 ------- 7------ Mined Discriminative Patterns 1 2 4 select mine AUC of MbT, DT MbT VS Benchmarks Mine frequent patterns; Select most discriminative patterns; Represent data in the feature space using such patterns; Build classification models.