Download

1 / 24
260 likes | 453 Views
A Reconfigurable Low-power High-Performance Matrix Multiplier Architecture With Borrow Parallel Counters Counters :. Rong Lin SUNY at Geneseo (lin@cs.geneseo.edu). Main topics of the presentation:.

E N D
A Reconfigurable Low-power High-Performance Matrix Multiplier Architecture With Borrow Parallel Counters Counters : Rong Lin SUNY at Geneseo (lin@cs.geneseo.edu)
Main topics of the presentation: Overview of the Reconfigurable Matrix Multiplier Architecture And The Circuit-Level Reconfiguration Overview of the Implementation Circuits: Borrow Parallel Counters
1. The Reconfigurable Matrix Multiplier Architecture And The Circuit-Level Reconfiguration
The Partial Product Decomposition-Based Arithmetic Architecture (a) The 4x4 partial product matrix; (b) addition of the partial product bits; (c, d) multiplication of two 8-bit numbers using four 4x4 multipliers
The size-8 base-4 reconfigurable matrix multiplier architecture
The size-16 base-4 reconfigurable matrix multiplier architecture
The mapping of partial product matrix and the 64 8x8 multipliers The square recursive partial product bit matrix decomposition
The reconfiguration switch states The input duplication network
The two of 4 matrix products which are produced in parallel, each with 16 output elements
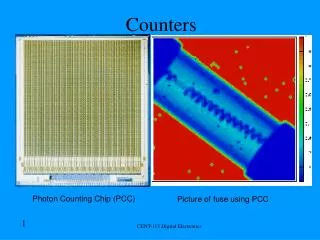
The building block circuits: borrow parallel counters 5_1 borrow parallel counter
About the large parallel counter 5_1 Receiving 5 binary Input bits with 1 of them being weighted 2 (called borrow bit), and others weighted 1. Producing 2 output bits and 3 In-stage carry in and out bits), so that the weighted sums of all in bits and all out bits are equal. CMOS pass-transistor circuit processing 4-b 1-hot encoded signals, each representing an integer of value ranging 0 to 3.
(1) Low switching activity(2) Fewer hot lines (data paths)(3) Low transistor count (78; equivalent to 3.3 FA’s; 23 per FA)
(4) A very compact layout due to good transistor distribution and regularity (processing four data paths of the same structure; binary logic does not have the advantage; layout-simulation: Cadence Analog Affirma tools with Spectre simulator 0.18 mm models )
The borrow bit Simplify the logic, reduce the number of transistors (2) Reduce the number of pass transistors cascaded (no more than 4 including 1 within the input inverter) (3) Rearrange and balance input bits for small multipliers (see Topic 2)
No type-conversion needed -- major improvement from the previous work:The embedded full adder adding two 4-b 1-hot encoded bits (s0-column j+1, s1-column j) and 1 binary bit (q-column j-1) directly ------ they have the same weight!
The typical simulation data Note: We use the best (3, 2) to the best of our knowledge; It’s meaningful to compare speeds in application
The 6 x 6-b borrow parallel multiplier ovals with the same color form an embedded FA (or HA or a binary bit) (3,2): 3 ovals (2,2): 2 ovals single bit: 1 oval Input: two 6-b numbers; output two numbers: p10 - p0 and q10 - q5 (note: first half (6 bits) is a single number) CSA style output, because it serves as an intermediate block) • An array of borrow parallel counters (virtually eliminating all area needed for inter-counter connections) • The height of the block is very small Inheriting all advantages of borrow parallel counters Delay = a single counter delay Height = a single counter height • A unique property: extra compact with a near zero area for inter-counterconnection
Concluding Remarks 1. A reconfigurable matrix multiplier architecture has been presented The processor can be run-time reconfigured to trade bitwidth for matrix size. (2)Efficiently reconfigured to compute the product of matrices X4x4 and Y4x4 for typical graphics and image applications (3) The hardware equivalent to one 64 x 64 bit high precision multiplier can provide four computation options (4) Minimized the common irregularity (5) Simplified the overall logic scheme and wiring structures
Concluding Remarks (cont’d) 2. New arithmetic circuits for implementation, which achieve low-power high-performance through a novel logic approach including: 4-b 1-hot data paths are dominated (lower switching activity in each logic stage) (2)Fewer hot lines generated in logic process (power & leakage power) (3) Lower transistor count (4) Higher circuit regularity, lower layout complexity (5) Lower complexity of component interconnection
Concluding Remarks (cont’d) (6) Utilizing borrow bits for simple circuit and high speed, more importantly, reducing pass-transistor path length (no more than 4) and rearranging and balancing input bits to each column of small multipliers (7) Utilizing partial product bit matrix decomposition for full self-testability, achieving high observability and controllability for component circuits (small multipliers are exhaustively testable)