Download
1 / 23
230 likes | 317 Views
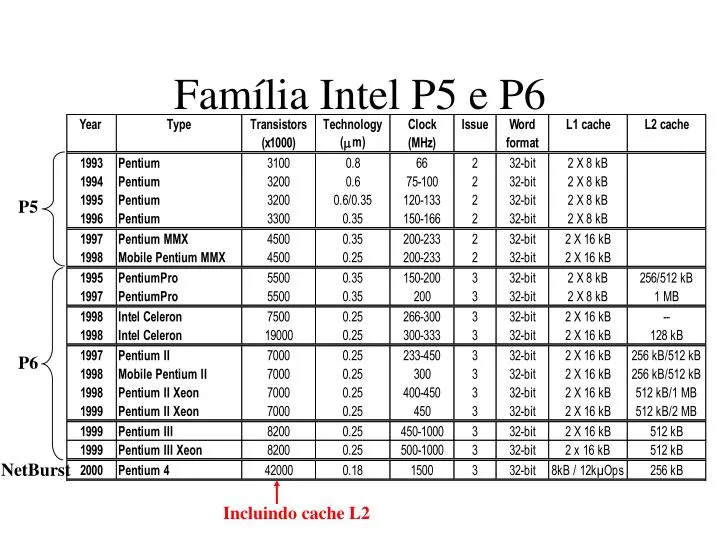
Família Intel P5 e P6. P5. P6. NetBurst. Incluindo cache L2. Floating point registers. Branch target buffer. C o n u t n r i o t l. Control ROM. 8kb instruction cache. P b I d r u n e e f s c f f t o

E N D
Família Intel P5 e P6 P5 P6 NetBurst Incluindo cache L2
Floating point registers Branch target buffer C o n u t n r i o t l Control ROM 8kb instruction cache P b I d r u n e e f s c f f t o e e r d t r u e c t. h 8kb data cache 256 TLB TLB Page Unit Bus Unit Arquitetura do Pentium Floating point unit Instruction pointer Branch target address 32 Prefetch address Add. generate V pipe ALU V pipe Integer register file Add. generate U pipe ALU U pipe Shifter 32 Address bus - 32 bits Data bus - 64 bits Data Add. Data bus - 64 bits Add. Bus 32 bits Control bus
Arquitetura do Pentium • Dois pipelines de 5 estágios: U e V • Estágios • PF - prefetch • D1 - instruction decode • D2 - address generate • EX - execute, cache, ALU access • WB - writeback
Prefet. Buffer V 64 bytes Decod. D1 V P b I d r u n e e f s c f f t o e e r d t r u e c t. h 256 bits 256 bits Prefet. Buffer U 64 bytes Decod. D1 U Arquitetura do Pentium
Decod. D2 V Decod. D1 V Decod. D2 U Decod. D1 U Arquitetura do Pentium Para o BTB Ger. End. V Ger. End. U Para o BTB
Decod. D1 V Decod. D1 U Arquitetura do Pentium ALU V REG ALU U Decod. D2 V Decod. D2 U Unidade de Microcódigo
Decod. D1 V Decod. D1 U Arquitetura do Pentium FPU Decod. D2 V Conrole Reg. File ADD DIV MUL Decod. D2 U Unidade de Microcódigo Dados
Não requerem micro-código para serem executadas. Normalmente levam 1 ciclo de clock para serem executadas. ADD AX,BX (não podem ser executadas ADD AX,CX em paralelo) MOV TABLE[SI],7 MOV ES:[DI],AL Arquitetura do Pentium • Execução Super-Escalar • Ambas as instruções devem ser simples. • Sem dependência de dados. • As instruções não podem ter modos de endereçamento imediato e indireto. • Instruções com prefixo só podem ser executadas no pipelin U.
I1 I2 I3 I4 I5 I6 I7 I8 I9 I10 I5 I6 I7 I8 I1 I2 I3 I4 I1 I2 I3 I4 I5 I6 I3 I4 I1 I2 I1 I2 Arquitetura do Pentium • Execução Super-Escalar Ciclos 1 2 3 4 5 de clock PF D1 D2 EX WB
H:11 P:T H:10 P:T Branch target buffer H:01 P:T H:00 P:NT 8kb instruction cache P b I d r u n e e f s c f f t o e e r d t r u e c t. h 256 TLB Previsão Dinâmica de Desvio NT T T Instruction pointer NT T Branch target address T Prefetch address NT NT Address Instruction Targ. Add. History Prediction . . .
X2 - segundo estágio de execução. WF - arrendonda o resultado e escreve nos registradores de ponto flutuante. ER - sinalização de erro e atualização da palavra de status. Unidade de Ponto Flutuante • PF - pré-busca • D1 - decodificação de instrução • D2 - geração de endereço • EX - leitura de memória e registradores. Conversão do formato de ponto flutuante em formato de memória. Escrita em memória. • X1 - primeiro estágio de execução. Dados da memória são convertidos no formato ponto flutuante. Escreve o operando para os registradores de ponto flutuante.
PF D1 D2 EX ER WF X2 X1 Unidade de Ponto Flutuante Pipeline U Fluxo de instruções e de dados Bypass Fluxo de dados ST(0) ST(1) ST(2) ST(3) ST(4) ST(5) ST(6) ST(7) Registradores de Ponto Flutuante 80 bits
64 bits 80 bits Registradores MMX Registradores de Ponto Flutuante • Acesso direto • Mudança automática • ao se executar uma • instrução MMX • Executar instrução EMMS • pararetorno ao acesso dos • reg. de ponto flutuante. 79 63 0 1 1 1 1 ST(0) ST(1) ST(2) ST(3) ST(4) ST(5) ST(6) ST(7) MM7 MM6 MM5 MM4 MM3 MM2 MM1 MM0 Registradores MMX
Barramento de Dados Pentium A31:A3 . Add. Trans A2,BE3: BE0 A2,A1 BHE,BLE BE7:BE0 A2,A1,A0 64 Bit Dev. 32 Bit Dev. 16 Bit Dev. 8 BitDev.
Shared - linha corrente pertence a mais de uma cache. Ao escrever-se nesta linha, um writethrough é gerado e invalia-se as outras cópias em outras caches. Invalid- a linha corrente está vazia. Uma leitura desta linha gera um miss. Coerência de Cache em Sistemas Multiprocessadores • Protocolo de coerência de Cache MESI • Modified - a linha corrente foi modificada (diferente da informação na memória principal) e pertence a uma única cache. • Exclusive- linha não modificada e exclusiva de uma única cache. Escrevendo-se nesta linha, esta passa para o estado Modified.
I cache D cache I cache D cache Barramento D cache I cache D cache I cache Coerência de Cache em Sistemas Multiprocessadores p3 P1 X=7 p4 P2 X=10 X=30
Bus externo Cache L2 Memory Reorder Buffer Bus Interface Unit D-cache Unit Memory Interface Unit Instruction Fetch Unit (com I-cache) Branch Target Buffer Functional Units Reservation Station Unit Microcode Instruction Sequencer Instruction Decode Unit Reorder Buffer & Retirement Register File Register Alias Table Pentium II/III
Pentium II/III • A instruction fetch unit (IFU) lê a I-cache, baseado no IP, no BTB, e interrupção. • Branch prediction: • BTB contêm 512 entradas com informações sobre a “história” e endereços destino (previstos). • Penalidades devido a Branch misprediction: pelo menos 11 cíclos, em média 15 cíclos • A instruction decoder unit (IDU) é formada por três decodificadores.
Pentium II/III • As instruções IA-32 são “quebradas” em micro-operações (ops). Cada ops possui dois operandos fonte e um operando destino. As ops têm comprimento fixo. • A maioria das IA-32 são convertidas em uma única ops (por qualquer um dos decodificadores). • Algumas instruções são transformadas (decodificadas) em até 4 ops (1,2,3 e 4) pelo general decoder. • Instruções mais complexas apontam para micro-códigos no microcode instruction sequencer (MIS) que gerará o fluxo apropriado de ops. • As ops são enviadas para register alias table (RAT), onde ocorre a renomeação de registradores. As referências aos registradores lógicos (IA-32) são convertidas em referências aos registradores físicos. • As ops prosseguem para reorder buffer (ROB, 40 entradas) e para reservation station unit (RSU, 20 entradas).
Unidade de Busca e decodificação - Fetch/Decode Unit IA-32 instructions Instruction Fetch Unit Next_IP Alignment I-cache Branch Target Buffer General Decoder Simple Decoder Simple Decoder Microcode Instruction Sequencer Instruction Decode Unit Register Alias Table op1 op2 op3 instruction decoder unit (IDU) in-order section
Seção de Execução for a de ordem • O envio das ops ao ROB é feito na ordem do programa. • As ops são enviadas para RSU que possui 20 reservation stations (RS), cada uma capaz de executar uma op. • As ops são enviadas às unidades funcionais de acordo com a dependência de dados e de recursos, sem observar a ordem do programa. • A RSU tem cinco portas e pode enviar até cinco ops por cíclo.
MMX Functional Unit Floating-point Functional Unit Integer Functional Unit Port 0 MMX Functional Unit Jump Functional Unit to/from Reorder Buffer Integer Functional Unit Reservation Station Unit Port 1 Load Functional Unit Port 2 Store Functional Unit Port 3 Store Functional Unit Port 4 Issue/Execute Unit





















