Download

1 / 34
340 likes | 503 Views
Eigenvalue Problems in Nanoscale Materials Modeling. Hong Zhang Computer Science, Illinois Institute of Technology Mathematics and Computer Science, Argonne National Laboratory. Collaborators:. Barry Smith Mathematics and Computer Science, Argonne National Laboratory

E N D
Eigenvalue Problems in Nanoscale Materials Modeling Hong Zhang Computer Science, Illinois Institute of Technology Mathematics and Computer Science, Argonne National Laboratory
Collaborators: Barry Smith Mathematics and Computer Science, Argonne National Laboratory Michael Sternberg, Peter Zapol Materials Science, Argonne National Laboratory
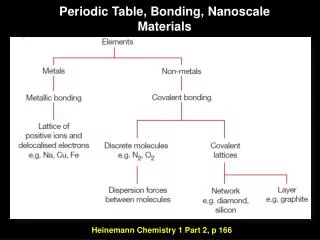
Modeling of Nanostructured Materials System size Accuracy *
Matrices are • large: ultimate goal 50,000 atoms with electronic structure ~ N=200,000 • sparse: non-zero density -> 0 as N increases • dense solutions are requested: 60% eigenvalues and eigenvectors Dense solutions of large sparse problems!
Two classes of methods: • Direct methods (dense matrix storage): - compute all or almost all eigensolutions out of dense matrices of small to medium size - Tridiagonal reduction + QR or Bisection - Time = O(N3), Memory = O(N2) - LAPACK, ScaLAPACK • Iterative methods (sparse matrix storage): - compute a selected small set of eigensolutions out of sparse matrices of large size - Lanczos - Time =O(nnz*N) <= O(N3), Memory = O(nnz) <= O(N2) - ARPACK, BLZPACK,…
DFTB-eigenvalue problem is distinguished by • (A, B) is large and sparse Iterative method • A large number of eigensolutions (60%) are requested Iterative method +multipleshift-and-invert • The spectrum has - poor average eigenvalue separation O(1/N), - cluster with hundreds of tightly packed eigenvalues - gap >> O(1/N) Iterative method + multiple shift-and-invert+robusness • The matrix factorization of (A-B)=LDLT : not-very-sparse(7%) <= nonzero density <= dense(50%) Iterative method + multiple shift-and-invert + robusness+efficiency • Ax=Bx is solved many times (possibly 1000’s) Iterative method + multiple shift-and-invert + robusness+ efficiency + initial approximation of eigensolutions
Lanczos shift-and-invert method for Ax = Bx: • Cost: - one matrix factorization: - many triangular matrix solves: • Gain: - fast convergence - clustering eigenvalues are transformed to well-separated eigenvalues - preferred in most practical cases
Idea: distributed spectral slicing compute eigensolutions in distributed subintervalsExample: Proc[1]Assigned Spectrum: ([0], [2]) shrink Computed Spectrum: { [1] } expand Proc[2] Proc[1] Proc[0] min imin [0] max imax [1] [2]
Software Structure • Shift-and-Invert Parallel Spectral Transforms (SIPs) • Select shifts • Bookkeep and validate eigensolutions • Balance parallel jobs • Ensure global orthogonality of eigenvectors • Subgroup of communicators ARPACK SLEPc PETSc MUMPS MPI
Software Structure • ARPACK www.caam.rice.edu/software/ARPACK/ • SLEPc Scalable Library for Eigenvalue Problem Computations www.grycap.upv.es/slepc/ • MUMPS MUltifrontal Massively Parallel sparse direct Solver www.enseeiht.fr/lima/apo/MUMPS/ • PETSc Portable, Extensible Toolkit for Scientific Computation www.mcs.anl.gov/petsc/ • MPI Message Passing Interface www.mcs.anl.gov/mpi/
Select shifts: - robustness: be able to compute all the desired eigenpairs under extreme pathological conditions - efficiency: reduce the total computation cost (matrix factorization and Lanczos runs)
Select shifts: mid 1 k i+1 i max e.g., extension to the right side of i: = k + 0.45( k – 1 ) mid = ( i +max )/2 i+1 = min( , mid )
Eigenvalue clusters and gaps • Gap detection • Move shift • outside of a gap
Bookkeep eigensolutions DONE COMPUT COMPUT COMPUT COMPUT UNCOMPUT UNCOMPUT 1 0 Overlap & Match • Multiple eigenvalues aross processors: proc[0] proc[1]
SIPs Proc[2] Proc[1] Proc[0] min imin [0] max imax [1] [2]
d) pick next shift ; update computed spectrum [min, max ] and send to neighboring processese) receive messages from neighbors update its assigned spectrum (min, max ) Proc[2] Proc[1] Proc[0] min [0] [0]1 max [1] [2] [1]1
Accuracy of the Eigensolutions • Residual normof all computed eigenvalues is inherited from ARPACK • Orthogonalityof the eigenvectors computed from the same shift is inherited from ARPACK • Orthogonality between the eigenvectors computed from different shifts? • Each eigenvalue singleton is computed through a single shift • Eigenvalue separation between two singletons satisfying eigenvector orthogonality
Subgroups of communicators: • when a single process cannot store matrix factor or distributed eigenvectors commEps commMat max min
Numerical Experiments on Jazz • Jazz, Argonne National Laboratory: • Compute – • 350 nodes, each with a 2.4 GHz Pentium Xeon • Memory – • 175 nodes with 2 GB of RAM, • 175 nodes with 1 GB of RAM • Storage – • 20 TB of clusterwide disk: • 10 TB GFS and 10 TB PVFS • Network – • Myrinet 2000, Ethernet
Tests • Diamond (a diamond crystal) • Grainboundary-s13, Grainboundary-s29, • Graphene, • MixedSi, MixedSiO2, • Nanotube2 (a single-wall carbon nanotube) • Nanowire9 Nanowire25 (a diamond nanowire) • …
Numerical results: Nanotube2 (a single-wall carbon nanotube) Non-zero density of matrix factor: 7.6%, N=16k
Numerical results: Nanotube2 (a single-wall carbon nanotube) Myrinet Ethernet
Numerical results: Nanowire25 (a diamond nanowire) Non-zero density of matrix factor: 15%, N=16k
Numerical results: Nanowire25 (a diamond nanowire) Myrinet Ethernet
Numerical results: Diamond (a diamond crystal) Non-zero density of matrix factor: 51%, N=16k
Numerical results: Diamond (a diamond crystal) Myrinet Ethernet * * *npMat=4
Summary • SIPs: a new multiple Shift-and-Invert Parallel eigensolver. • Competitive computational speed: - matrices with sparse factorization: SIPs: (O(N2)); ScaLAPACK: (O(N3)) - matrices with dense factorization: SIPs outperforms ScaLAPCK on slower network (fast Ethernet) as the number of processors increases • Efficient memory usage: SIPs solves much larger eigenvalue problems than ScaLAPACK, e.g., nproc=64, SIPs: N>64k; ScaLAPACK: N=19k • Object-oriented design: - developed on top of PETSc and SLEPc. PETSc provides sequential and parallel data structure; SLEPc offers built-in support for eigensolver and spectral transformation. - through the interfaces of PETSc and SLEPc, SIPs easily uses external eigenvalue package ARPACK and parallel sparse direct solver MUMPS. The packages can be upgraded or replaced without extra programming effort.
Challenges ahead … Matrix Size 6k 32k 64k <- We are here 200k • Memory • Execution time • Numerical difficulties!!! eigenvalue spectrum (-1.5, 0.5)=O(1) -> huge eigenvalue clusters -> large eigenspace with extremely sensitive vectors • Increase or mix arithmetic precision? • Eigenspace replaces individual eigenvectors? • Use previously computed eigenvectors as initial guess? • Adaptive residual tol? • New model? • …