Download

1 / 19
190 likes | 374 Views
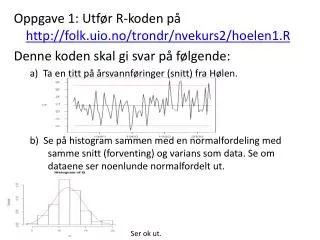
Oppgave 1: Utfør R-koden på http://folk.uio.no/trondr/nvekurs2/hoelen1.R Denne koden skal gi svar på følgende: Ta en titt på årsvannføringer (snitt) fra Hølen.

E N D
Oppgave 1: Utfør R-koden på http://folk.uio.no/trondr/nvekurs2/hoelen1.R Denne koden skal gi svar på følgende: • Ta en titt på årsvannføringer (snitt) fra Hølen. • Se på histogram sammen med en normalfordeling med samme snitt (forventing) og varians som data (momentestimat). Se om dataene ser noenlunde normalfordelt ut. • Gjør et QQ-plott for også å sjekke data mot normalfordelingen. • Gjør det samme som i b og c, men bruk lognormalfordelingen i stedet, der log-snitt og log-varians er den samme som i data (log-moment-estimat). • Gjenta b-d for døgnvannføring også (finnes på http://folk.uio.no/trondr/nvekurs2/TrendDognHoelen.txt). Hvis konklusjonene blir litt ulike, hva er grunnen?
Oppgave 2: Er forventingsverdien til årsvannføringer fra Hølen 10m3/s? http://folk.uio.no/trondr/nvekurs2/hoelen2.R • Estimer forventningsverdien. • Sjekk om forventingen er 10m3/s ved en t-test (tar hensyn til usikkerheten i estimert varians). Bruk gjerne 5% signifikansnivå (konfidens 95%). • Vis data sammen med konfidensintervallet. Er det en bekymring at såpass masse års-snitt ligger utenfor konfidensintervallet? Er det 95% sannsynlighet for at egentlig forventingsverdi ligger innefor det spesifikke konfidensintervallet? • Kunne vi gjort a-c for døgndata også? • Skal nå foreta samme analyse der vi bruker lognormal-fordelingen hellers enn normalfordelingen. Kjør en bootstrap-analyse som angir 95% konfidensintervall. Hva sier dette om antagelsen forventing=10m3/s?
Ekstraoppgave 1: Terningsutfall På en kubisk terning er det 1/6 sannsynlighet for hver type utfall fra 1 til 6. Ved to terninger, er utfallene antatt uavhengig. • Hva er sannsynligheten for å få et spesifikt utfall på to terninger, f.eks. sannsynligheten for å få 5 på første terning og 2 på andre? • Hva blir da sannsynligheten for å få sum=2 på de to terningene? Gjenta for sum=3, sum=4, sum=5, sum=6 , sum=7, sum=8. • Hva er sannsynligheten for å få sum<=4? • Hva er sannsynligheten for to like? • Hva er sannsynligheten for å få to like og sum<=4? • Hva er sannsynligheten for enten å få sum<=4 eller to like terninger? Du kan bruke svaret fra c, d og e. • Både fra regelen for betinget sannsynlighet og fra listen av utfall der sum<=4, hva blir sannsynligheten for to like gitt sum<=4? • Regn ut sannsynligheten for sum<=4 gitt to like, både fra liste av mulige utfall og fra Bayes formel.
Ekstraoppgave 2: På Blindern er det slik at det er 33.9% sjanse for at det regner en dag, hvis det regnet gårsdagen, og 12.9% sjanse for at det regner en dag hvis det ikke regnet gårsdagen. PS: Antar stasjonaritet, altså at alle sannsynligheter er de samme uavhengig av tidspunkt, under de samme forutsetningene. • Hva er sannsynligheten for at det regner en tilfeldig dag? (I.e. hva er marginalsannsynligheten for regn?) Tips: P(regn i dag)=P(regn i dag og regn i går)+P(regn i dag men ikke i går). • Hvorfor er sjansen for at det regnet i går gitt at det regner i dag også 33.9%? (Tips: Bayes formel)
Ekstraoppgave 3 – betingete sannsynligheter Hobbitun-rådet har avgjort at man skal ekspandere hobbit-landen vestover. Dessverre viser det seg at landene vestover er infisert av drager! Av de 10kmx10km arealene som er studert så langt, var 70% av dem drage-infisert. En standard-protokoll for område-undersøkelse ble lagt. Et standardisert testområde av mindre størrelse, inne i området man undersøker, blir finkjemmet av feltbiologer. Hobbitun biologiske avdeling har funnet at sannsynligheten for å finne drager i et testområde hvis området det er i er infisert av drager, er 50% Hvis det ikke er noen drage i området, blir det selvfølgelig ingen deteksjon i testområdet. Hobbit Dragon No dragons Here be dragons ? ?
Ekstraoppgave 3 forts. Modell: Områdets drage-status (L) Sanns. for drage detektert i testområde (D) Hva er (marginal) sannsynlighet for å finne en drage, hvis du ikke vet om området er infisert eller ikke? (Hint: Loven om total sannsynlighet) Vis med Bayes formel at sannsynligheten for å at et område er infisert av drager, gitt at du fant en drage i testområdet, er 100%. Finn sannsynligheten for at det er drager i området gitt at du ikke fant noen. Kunne du forvente at sannsynligheten minsket fra originalsannsynligheten (70%) selv uten å vite deteksjons-sannsynligheten? eller Drager i området Ingen drager Drager funnet Drager funnet og er i området Drager i området Drager i området Ingen drager Ingen drager Drager funnet
Oppgave 3: Uavhengighet, Markov-kjeder og nedbør på Blindern Skal sjekke om tersklet døgnnedbøren på Blindern er uavhengig eller ikke. Alternativet er at den er en Markov-kjede. Angir nedbørstilstanden (0 eller 1) med xi, der i angir dagen. Siden vi trenger å betinge på foregående tilstand setter vi til side den første tilstanden som x0. Antall dager bortsett fra dette betegnes n. Null-hypotese: Nedbørstilstanden (0 eller 1) er uavhengig fra dag til dag. Vi kan derfor spesifisere modellen med en parameter, p=sannsynligheten for regn en dag. Sannsynligheten for en gitt kombinasjon slike tilstander er da der k=antall dager med regn. Dette blir altså likelihood’en til denne modellen. ML-estimatet til p blir da (kan også tas direkte fra store talls lov): Alternativ hypotese: Nedbørstilstanden (0 eller 1) er en Markov-kjede. Har en overgangssannsynlighet fra ikke nedbør til nedbør på pNR og en sannsynlighet for å at det regner neste dag hvis det regner nå på pRR. (De to andre sannsynligheten er bare negasjonen av de foregående). Sannsynligheten for en gitt kombinasjon av tilstander er da: der kR og nRer antall regndager og dager totalt der det regnet foregående dag, og kN og nN er tilsvarende der det ikke regnet foregående dag. ML-estimatet på de to parametrene blir da pRR R 1-pRR pNR N 1-pNR
Oppgave 3: Uavhengighet, Markov-kjeder og nedbør på Blindern (forts). Skal sjekke om tersklet døgnnedbøren på Blindern er uavhengig eller ikke. Kode: http://folk.uio.no/trondr/nvekurs2/blindern.R. Data: http://folk.uio.no/trondr/nvekurs2/blindern_terkslet.txt. • For Blindern-data, hva blir estimatet på p (null-hypotese) og pNR og pRR (alternativ hypotese). Hvordan ser det ut til at sammenhengen mellom regn en dag og den neste er? • Fra ekstraoppgave 2a har man at marginalfordelingen for regn gitt pNR og pRR (alternativ hypotese) er p’=pNR/(1-pRR+pNR) (vis evt. det). Sammenlign dette med p fra null-hypotesen. • Likelihood-ratio testen sjekker opp en mer avansert modell mot en nullhypotese ved: der la og l0 er logaritmen av maksimal likelihood for alternativ og null-hypotese henholdsvis og er den såkalte kji-kvadratfordelingen (fordelingen til kvadratet av noe standard normalfordelt) og ker forskjellen i antall parametre. Beregn p-verdien og sjekk om man kan forkaste uavhengighet med 95% konfidens. I.e. er regntilstanden på Blindern uavhengig fra dag til dag? • Anta at ML-estimatorene for pNR og pRRer ca normalfordelt (asymptotisk teori) og og tilsvarende for pNR. Hva blir da 95% konfidensintervall for disse to parametrene? • Kjør parametrisk bootstrap for å se usikkerheten (95% konfidensintervall) i p (null-hypotese) og p’ (Markov-kjede). Sammenlign 95% konfidensintervall for p fra bootstrap og metodikken i d. pRR R 1-pRR pNR N 1-pNR
Oppgave 4: Medisinsk eksempel oversatt til språkbruken i Bayesiansk statistikk. (Her må man oversette sannsynlighetstettheter tilbake til sannsynligheter og integral til summer.) Det er 0.1% av befolkningen som har en gitt sykdom. En test gir alltid positivt utslag hvis du har sykdommen men kun 1% sannsynlighet for positivt utslag hvis du ikke har den. • Hva er a’ priori-fordelingen? • Hva er likelihood’en for ulike utfall? • Beskriv og beregn (via loven om total sannsynlighet) a’ priori prediksjonsfordeling (marginalfordeling). • Hva blir a’ posteriori-fordelingen, gitt positiv test eller negativ test? • Øvelse i avledet størrelse (risikoanalyse): Samfunnskostnaden (K) ved en helbredende operasjon er 10.000kr, mens nytte-effekten (N) er 100.000kr hvis man er syk, 0kr hvis man er frisk. Hvis man har testet positiv, er det da samfunnssnyttig å starte en operasjon med en gang? Beregn forventet samfunnsnytte, E(N-K|positiv test). • Den første testen var positiv. Hva blir a’ posteriori prediksjonsfordeling for en ny test nå? • En ny test foretas og gir også positivt utfall. Hva blir nå a’ posteriori sannsynlighet for at man er syk? Lønner det seg nå å foreta operasjonen?
Oppgave 5: Forventingsverdien til årsvannføringer fra Hølen – Bayesiansk analyse http://folk.uio.no/trondr/nvekurs2/hoelen3.R Antar at data er normalfordelt. Har en vag men informativ prior for vannførings-forventningen, 0==10, se slide 17-18. Antar vi kjenner =2.83. Minner om formlene når alt er normalt: • Likelihood: • A’ priorifordeling, velger: • A’ posteriori-fordeling: • Hvordan blir a’ posteriorifordelingen i dette tilfelle? Estimer vannførings-forventningen fra dette. Er dette veldig forskjellig fra det du fikk i oppgave 5a? • Lag et 95% troverdighetsintervall for vannførings-forventningen (Tips: 95% av sannsynlighetsmassen befinner seg innenfor +/-1.96 standardavvik fra forventningsverdien i en normalfordeling). Ble dette mye forskjellig fra 5b? Kan du fra dette konkludere noe angående antagelsen vannførings-forventning=10m3/s.
Oppgave 5 –forts: Forventingsverdien til årsvannføringer fra Hølen – Bayesiansk analyse http://folk.uio.no/trondr/nvekurs2/hoelen3.R Antar at data er normalfordelt. Har en vag men informativ prior for vannførings-forventningen, 0==10, se slide 17-18. Antar vi kjenner =2.83. Marginal sanns.-tetthet: c) Skal nå teste antagelsen vannførings-forventning=10m3/s Bayesiansk. Sammenlign marginalsannsynlighetstettheten for de data vi fikk vs sannsynlighetstettheten når =10. Hva antyder dette? d) Skal nå bruke resultatet fra c til å regne på modellsannsynligheter. Modell 0 har =10 mens modell 1 er slik som spesifisert ovenfor. Bruk og anta at a’ priori-sannsynligheten for hver modell er 50%. Hva blir konklusjonen? e) Lag et plott over marginalfordelingen gitt ulike utfall og sammenlign med sannsynlighetstettheten nå =10 (likelihood under modell 0). Hva sier dette om hvilke utfall som ville være evidens for modell 0 og 1?
Oppgave 6: Gjentaksanalyse for bestemt nivå i kontinuerlig tid. Skal se på faren for å overgå en spesifikkvannførings-verdi. Stasjonen Gryta har hatt vannføring>1.5m3/s y=27 ganger i løpet av t=44 år. Antar slike hendelser foregår uavhengig i tid. Altså at antall hendelser innefor en tidsperiode er Poisson-fordelt. Bruker gjentaks-intervall, T, som parameter i denne fordelingen. Når man har data over en tidsperiode t, vil sannsynligheten for y hendelser bli: Denne likelihood’en maksimeres med . (For de med analytisk optimerings-erfaring, vis dette). • Hva blir ML-estimatet? • Fra asymptotisk teori har man som nevnt at Bruk dette til å konstruere et 95% konfidensintervall når det opplyses at og at normalfordelingen har 95% av sannsynlighetsmassen innenfor +/-1.96 standardavvik (Sett in ML-estimatet for T).
Oppgave 7: Bayesiansk gjentaksanalyse for bestemt nivå i kontinuerlig tid. Skal se på faren for å overgå en spesifikkvannførings-verdi. Antar slike hendelser foregår uavhengig i tid. Altså at antall hendelser innefor en tidsperiode er Poisson-fordelt. Bruker gjentaks-intervall, T, som parameter i denne fordelingen. Da får vi Antar invers-gamma-fordeling (siden det er matematisk behagelig å gjøre det) for gjentaksintervallet Får da at marginalfordelingen blir: (dette er den såkalte negativ binomiske fordelingen).
Oppgave 7 (forts.): Kode finnes på http://folk.uio.no/trondr/nvekurs2/gryta_ekstrem.R Stasjonen Gryta har hatt vannføring>1.5m3/s y=27 ganger i løpet av t=44 år. • Plott a’ priori-fordeling og marginalfordeling hvis du bruker ==1 som førkunnskap. • Hva blir det generelle uttrykket for a’ posteriori-fordelingen til T? Plott den for Gryta for ==1 sammen med a’ priori-fordelingen. Forsøk også ==0.5 og til og med ==0 (ikke-informativt) . Ble det noen stor forskjell i a’ posteriori-fordelingen? Sammenlign med klassisk estimat: TML=t/y=1.63 år. • Finn 95% troverdighetsintervall ved å finne 2.5%- og 97.5%-kvantilen til a’ posteriori-fordelingen, når prioren ==1 brukes. (R-tips: 2.5%-kvantilen til inverse-gamme-fordelingen er en over 97.5%-kvantilen til gammafordelingen og vise versa.) Sammenlign med 95% konfidensintervall i oppgave 4. • Kan du finne prediksjons-fordelingen til antall nye flommer på Gryta de neste hundre år? Plott i så tilfelle denne. Sammenlign med Poisson-fordeling hvis man tar ML-parameteren for gitt. Hvorfor er sistnevnte fordeling skarpere enn den Bayesianske prediksjonsfordelingen? • Kjør en enkel MCMC-algoritme fra a’ posteriori-fordelingen. Se etter når trekningen stabiliserer seg (burn-in) og hvor mange trekninger som trenges før du få en trekning som er ca. uavhengig (spacing). • Hent 1000 uavhengige trekninger etter burn-in. Sammenlign med teoretisk a’ posteriori-fordeling (histogram og qq-plott). • Foreta ny MCMC-trekning men bruk nå a’ priori som er f(T)=lognormal(=0,=2). (Dette kan ikke løses analytisk). Sammenlign med de trekningene du fikk i d.
Oppgave 8: Ekstremverdi-analyse på Bulken (rundt 120 år med data). Kode: http://folk.uio.no/trondr/nvekurs2/bulken_ekstrem.R Data: : http://folk.uio.no/trondr/nvekurs2/bulken_max.txt Skal bruke Gumbel-fordelingen som fordelings-kandidat her: • Foreta et ekstremplott, det vil si sorter vannføringene og plott dem mot estimert gjentakintervall der n er antall år og i er en løpe-indeks fra n til 1. • Foreta en ekstremverditilpasning via første to l-momenter, 1og 2. (Ekstra: Sammenlign med det du får fra DAGUT). Parameterne forholder seg til l-momentene som = 2/log(2), = 1-0.57721. Estimater for 1 og 2 fås som • Plott flomstørrelse som funksjon av gjentaksintervall gitt l-moment-estimatene sammen med data (a). • Foreta ML-estimering av parameterne. • Plott flomstørrelse som funksjon av gjentaksintervall gitt ML-estimatene. • Foreta Bayesiansk analyse med flat prior. Foreta 1000 MCMC-trekninger (burnin=1000, spacing=10). Sammenlign. Se på usikkerheten i parametrene (fordelingen av parametre gitt data, a’ posteriorifordelingen altså). Se også på forløpet til trekningene. Har kjeden stabilisert seg (er burn-in lang nok) og er det avhengighet i trekningene (kunne spacing med fordel settes høyere)? • Bruk også prediksjonsfordelingen (altså der du tar parameterusikkerheten med i betraktningen) til å foreta samme plott som i a, c og e. Sorterte data
Oppgave 9: Ekstremverdi-analyse på Bulken (120 år med data). Kode: http://folk.uio.no/trondr/nvekurs2/bulken_ekstrem2.R Data: http://folk.uio.no/trondr/nvekurs2/bulken_max.txt Ekstrakode: http://folk.uio.no/trondr/nvekurs2/mcmc.R Skal bruke GEV-fordelingen som fordelings-kandidat her: • Foreta ML-estimering av parameterne. Start med optimeringen fra tilfeldige start-parametre (standard-normalfordelt). Gjør dette multiple ganger for å finne den globalt maksimale likelihood’en. Plott ekstremverdier og tilpasning. • La t være en tids-indikator som løper fra 1:120. Tilpass via ML en modell der hver av parametrene i tur er lineært tidsavhengig, for eksempel om (t)=0+t. • Bruk AIC=-2*log(maxlikelihood)+s*k, der k=antall parametre, til å avgjøre hvilken av modellene som er best, den uten tidsavhengighet eller en av de tre med. Den beste modellen er den med minst AIC. • Foreta Bayesiansk analyse på originalmodellen. Denne gangen ikke med flat prior, men der ~logN(3.89, 1.722), ~logN(2.64,1.742), ~N(0.0325, 0.232) (Et estimat på ”naturens prior” hentet fra et sett med ML-estimat for ulike stasjoner). Foreta 1000 MCMC-trekninger (burnin=10000, spacing=100). Denne gangen kan en ferdig-rutine for MCMC brukes. Sjekk trekningene, er de ok? Hva er spredningen(usikkerheten) til parameterne? Sammenlign med a. • Gjør det samme for den beste av de tre modellene med tidsavhengige parametre. Sammenlign spredningene til parametrene med spredningen i nullmodellen. Se også på spredningen i tidsregresjonskoeffisienten og bruk dette til å diskuter modellen =0. Beregne a’ posteriori modellsannsynlighet for null-modellvs tidsavhengig modell når vi anta P(tidsavhengighet)=50%. (marginalfordelingen beregnes via en ferdiglagd importance-sampling-rutine). Har man fått evidens for tidsavhengig modell? • Her har den beste tidsavhengige modellen blitt brukt som en stand-in for summen av tre ulike modeller. De to andre var ifølge AIC ikke spesielt bra og man kan regne med at Bayesiansk metodikk vil replikere dette. Hvis man tar hensyn til dette, og gir den beste tidsavhengige modellen a’ priori-sannsynlighet 50/3%, hva blir da a’ posteriori-sannsynligheten? Er det overbevisende evidens man har fått?
Oppgave 10: Skal nå kjøre ARMA-tilpasning av døgndata fra Hølen. Kode: http://folk.uio.no/trondr/nvekurs2/hoelen_arima.R • Plott data • De-trend (fjern lineær tids-trend og sesong-variasjon). • Se på autokorrelsjon (og partiell autokorrelasjon). • Tilpass en AR(1)-modell (PS: pacf antyder at AR(2) er bedre). Se om estimert parameter er lik noe du så i 13c. • Lag analytiske plott av residualene. Hva sier de? • Forsøk så med en ARMA(1,1)-modell. Se igjen på residualene. Hva sier de nå?
Oppgave 11: Bruk av Kalman-filter til å interpolere over hull på Farstad stasjon, år 1993. Skal bruke enkleste type kontinuerlig-tid Markov-kjede, tilfeldig gange eller mer nøyaktig, Wiener-prosess. Dataene er har varierende tidsoppløsning og blir log-transformert før analysen foretas. Oppdaterings-formelen (systemligningen) er Observasjonsligningen er Total kun to parametre, med andre ord, og . Kode: http://folk.uio.no/trondr/nvekurs2/farstad.R Data: http://folk.uio.no/trondr/nvekurs2/farstad_1993.txt • Plott data. Serien har et umarkert hull i månedskiftetmai-juni som må markeres. I tillegg, lag kunstige hull: 1993-02-01 00:00:00 - 1993-02-03 00:00:00 1993-03-01 12:00:00 - 1993-03-15 12:00:00 1993-08-01 00:00:00 - 1993-08-01 18:00:00 1993-09-01 00:00:00 - 1993-09-02 00:00:00 1993-10-01 00:00:00 - 1993-11-01 00:00:00 Plott data i hullene sammen med resterende data. b) Ta en titt på det implementerte Kalman-filteret og sammenlign med beskrivelsen i kurset. • Kjør en ML-optimering og sjekk resultatene. Hva kan sies om observasjonsparameteren ? • Foreta en Kalman-glatting med ML-estimerte parametre. Se på total-resultatet. • Sjekk hvordan interpoleringen har fungert i hullene. Hva slags interpolasjon er dette (på log-skala)? Hva får man ut her i tillegg til interpolasjonen? • Kritiser modellen og se om du skjønner hvorfor tilpasningen og usikkerhetene blir slik de blir. Om du er i det kreative hjørnet, prøv å foreslå bedre modeller.
Oppgave 12: Bruk av Kalman-filter til å interpolere over hull på stasjonene Etna og Hølervatn, 2010-2011. Dataene er har ekvidistant tidsoppløsning (døgn) og blir log-transformert før analysen foretas. Skal bruke en 2-dimensjonal AR1-prosess (så den har en stasjonær tilstand), krysskorrelert støy (slik at kompletering blir mulig) lik autokorrelasjon og varians, men individuell forventing og sesong-variasjoner i denne forventningen (som antas lik for de to seriene). Oppdaterings-formelen (systemligningen) er Observasjonsligningen er Total åtte parametre, med andre ord: a,eh,,,S1,C1og . Kode: http://folk.uio.no/trondr/nvekurs2/kompletering.R Data: http://folk.uio.no/trondr/nvekurs2/etna_hoelervatn.csv • Plott data. Lag kunstige hull (spesifisert i T-koden). Plott data i hullene sammen med resterende data b) Ta en titt på det implementerte Kalman-filteret og sammenlign med beskrivelsen i kurset. • Kjør en ML-optimering og sjekk resultatene. Hva vil autokorrelasjonen her ha å si? Hva har krysskorrelasjonen å si? • Foreta en Kalman-glatting med ML-estimerte parametre. Se på total-resultatet. • Sjekk hvordan kompletteringen har fungert i hullene. Hva skjer når begge stasjonene har hull samtidig? Et par kompletteringer ser ut til å fungere mindre bra. Hvorfor? • Sjekk om krysskorrelasjonen er null (altså at det ikke er grunn til å kompletere), via likelihood-ratio-testen.