Download

1 / 17
170 likes | 300 Views
Enhancing Performance Portability of MPI Applications Through Annotation-Based Transformations. Md. Ziaul Haque , Qing Yi , James Dinan , and Pavan Balaji ICPP, Oct, 2013. Lyon, France. Motivation. Node i. Node j. Node k. MPI provides a wide variety of communication operations

E N D
Enhancing Performance Portability of MPI Applications Through Annotation-Based Transformations Md. ZiaulHaque, Qing Yi, James Dinan, and PavanBalaji ICPP, Oct, 2013. Lyon, France.
Motivation Node i Node j Node k • MPI provides a wide variety of communication operations • One-sided vs. two-sided • Synchronous vs. asynchronous • Collective vs individual sends/recvs • Performance of these operations are sensitive to • Their context of uses within applications • Hardware support for inter-node communications • Underlying MPI library and system capabilities • Optimizations within MPI libraries are insufficient • Libraries cannot see the context of the operations and thus cannot optimize beyond a single operation
Enhancing Performance Portability of MPI Applications • Applications must parameterize communications to • Send the messages of the right sizes • Overlap communications with computation • Use appropriate communication operations • So that the knobs can be automatically tuned at or before runtime • Here we consider compilation time • Use annotations to allow explicit parameterization of implementation algorithms • Programmable control of optimizations • Integration of domain knowledge • Fine-grained parameterization of transformations • Automated tuning for performance portability
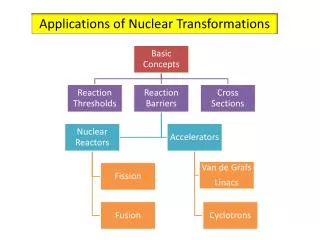
Outline • Annotation-driven transformation framework • Light weight program transformations • Using the POET program transformation language • Optimizing MPI applications for performance portability • Optimizing the use of MPI libraries • The Annotation language • Automating program transformations • Coalescing of MPI one-sided communications • Overlapping communication with computation • Selecting the appropriate MPI operations • Experimental results • Conclusion and future research
Optimizing MPI Applications Developer Platform Analysis System properties Annotated code Optimization Analyzer Performance Measurements Transformation configuration Annotated code Program Transformation Modified source code Vendor Compiler (e.g. icc/gcc) Executable
Implemented Using The POET Language • A scripting language for • Applying parameterized program transformations Interpreted by search engine and transformation engine • Programmable control of compiler optimizations • Ad-hoc translation between arbitrary languages • Under development since 2006 • Open source (BSD license) • Language documentation and download available at • www.cs.uccs.edu/~qyi/poet
The Annotation Language • Recognizes only annotated statement blocks #pragma mpi @pragma@ stmt of the underlying language • Each @pragma@ is one of the following annotations • osc_coalesce (@win_buf_spec@) …… [nooverlap] • cco @mpi_comm@(arg1,…,argm) …… • rma (@win_buf_spec@) …… • local_ldst (@win_buf_spec@) …… [nooverlap] • indep @mpi_comm@(arg1,…,argm) …… • Each transformation is driven by a pragma • Future work will seek to automatically generate pragma via program analysis
Annotation-driven Optimization Algorithm foreach annotated MPI block (annot, body) in input: (1) if (is data coalesce annot(annot)): foreach win ∈ win_buf_list(annot): mpi_osc_data_coalesce(win, has overlap(annot), body); (2) if (is cco annot(annot)): foreach comm ∈ comm groups of(annot): mpi comp comm overlap(comm, innermost body of(body)); (3) if (is rma annot(annot)): foreach win ∈ win buf list of(annot): if (cache coh(config)): mpi rma 2 ldst(win,body); (4) if (is ldst annot(annot)): if (cache coh(config)): mpi_ldst_coh(win,has_overlap(annot),body); else mpi ldst incoh(win,has overlap(annot),body); input: input MPI program to optimize;config: architecture configurations of the system;
Coalescing of One-sided Communications Original code with pragma #pragma mpi osc_coalesce (win) nooverlap { MPI_Win_fence(win); MPI_Accumulate(x[0], target, win); MPI_Accumulate(x[1], target, win); foo(); MPI_Put(y[0], target1, win); MPI_Put(y[1], target2, win); MPI_Put(y[2], target1, win); MPI_Win_fence(win); } Optimized pseudo code MPI_Win_fence(win); MPI_Accumulate(x[0,1], target, win); foo(); MPI_Put(y[0,2], target1, win); MPI_Put(y[1], target2, win); MPI_Win_fence(win); • Group communications to the same destination; • Postpone communication until a dedicated buffer for the group is full • The actual transformation generates complex code to accommodate • Dynamic coalescing of messages in loops; Parameterization of message buffer sizes
Communication Coalescing: Key Strategies • Grouping of MPI communications • Members have the same destination and use the same MPI_Put/Get or the same reduction in Accumulate • Allocate a dedicated buffer for each group • Postpone communications until a coalescing buffer is full (constrained by preset CL_factor) • Use AVL trees to resolve conflicting addresses of Accumulate • Unless a “no overlap” clause is given by user annotation • Clear all buffers at the final synchronization • Free coalescing buffers for reuse • Handle unknown function calls • Treat as potential synchronizations • Trigger clearing of coalescing buffers • Unless annotated as safe statements by user annotations
Overlapping Communication With Computation Original code with pragma Optimized code #pragma mpi cco MPI_SendRecv(ew_comm,ns_comm) for( i=0; i<niter; i++ ){ …… if (ns_id>0) MPI_Send(…,ns_comm); if (ns_id<size-1) MPI_Recv(…,ns_comm,…); …inner stencil computation… … boundary computation … } #pragma cco MPI_SendRecv(ew_comm,ns_comm) for( i=0; i<niter; i++ ){ …… if (ns_id>0) MPI_Isend(…,ns_comm,&r1); if (ns_id<size-1) MPI_Irecv(…,ns_comm,&r2); …inner stencil computation… MPI_wait(&r1,&s1); MPI_wait(&r2&s2); … boundary/corner computation … } • Split synchronous operations into asynchronous ones and waits • Move asynchronous operations up as early as possible • Move wait operations as late as possible • Use the “indep” annotation to indicate independence of computation/comm • Ongoing extension: breaking up communications into smaller messages before overlapping them with computation
Remove Memory Accesses vs. Local Loads/stores Using Remote memory accesses Using local loads/stores #pragma mpi rma(win,buf,int,MPI_INT,wsize,wrank) { MPI_Win_lock(MPI_LOCK_SHARED, i, 0, win); for (j = 0; j < BUF_PER_PROC ; j++) { MPI_Put(&wrank,1,MPI_INT,i, base+j,1,MPI_INT,win); } MPI_Win_unlock(i, win); } #pragma mpi local_ldst(win,buf,int, MPI_INT, wsize,wrank) no_overlap { MPI_Win_lock( MPI_LOCK_EXCLUSIVE, i, 0, win ); for (j = 0; j < BUF_PER_PROC ; j++) { buf[base+j] = wrank; } MPI_Win_unlock(i, win); } • Performance penalties of mixing RMA and local load/stores • Exclusive locks are required when using local load/stores, which are faster when hardware supports cache coherence • Locking unnecessary when the hardware supports cache coherence • Optimization: automatically selects the best operations based on underlying system support of hardware platforms
Experimental Results • Goal: studying the performance portability of MPI applications • Using four benchmarks, with FT manually transformed • Using two supercomputers from DOE/ANL • Fusion: a cluster with 320 nodes, each with two Intel Nehalem Quad-Core 2.6 GHz processors and 36 GB of memory, interconnected via InfiniBand • {Surveyor}, a Blue Gene/P system with 1024 compute nodes, each with a quad-core 850 MHz PowerPC 450 processor and 2 GB memory.
Result: Applying osc_coalesce to bfs on Fusion(using 128 nodes)
Result: Optimizing NAS FT on Fusion(top) on Surveyor (bottom)
Conclusions • Most MPI optimizations are platform sensitive, it is difficult to determine a priori • What is the best message size to send/receive • Which communication operation to use • How much memory to use to coalesce messages • Automating the optimizations • Need to parameterize optimization configurations and specialize applications for each individual platform • Need to allow developers to provide hints and help --- annotation driven program analysis & transformation • Future work • Apply optimizations across procedure boundaries • Automatically determine opportunities and generate annotations