Download
1 / 16
160 likes | 319 Views
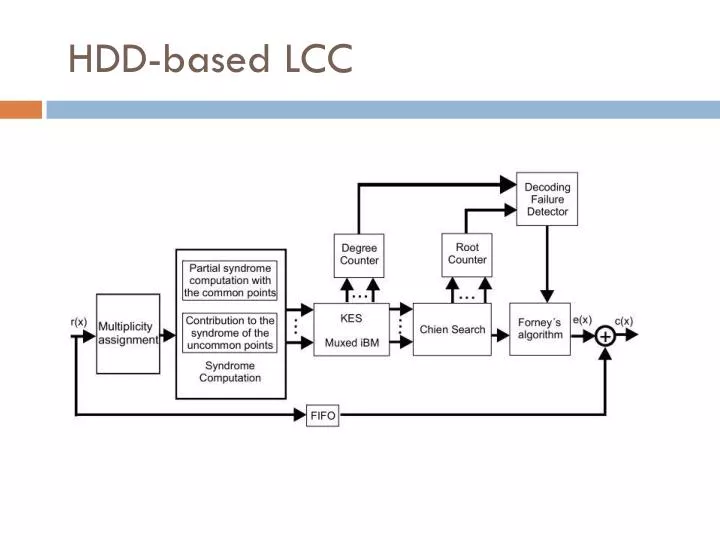
HDD-based LCC. LCC Multiplicity Assignment k reliable positions set represented as R. n-k unreliable positions set represented as . η<n-k most unreliable positions set represented as Z . Two interpolation positions . HDD-based LCC.

E N D
LCC Multiplicity Assignment • k reliable positions set represented as R. • n-k unreliable positions set represented as . • η<n-k most unreliable positions set represented as Z . Two interpolation positions
Something new: 1.当η很大时,syndrome update 的延迟可能很大。将测试向量分组的思想能减小syndrome update的延迟,但是无法减小KES和PS的延迟,能否找到合适的方法,让KES和PS与syndrome update协同。 2.能否从re-encoder中获益。经过re-encoder,k个可靠位置为0,可以减少k个syndrome计算单元,但是必须加入两个擦除译码器,可能得不偿失。
η=5,σ=2 将个测试向量分成组
Step-by-step Decoding Algorithm • 步进式译码的思想是:对(n,k)RS码,在接收码字的第i位(i=0~n-1),加上GF(2^m)中的任一非零元素β,β=1~2^m-1。如果码字的差错位数减小了,则第i位是错位位置,且错误大小为β。
当错误位置数小于k时,;当错误位置数等于k时,当错误位置数小于k时,;当错误位置数等于k时, 将在接收码字的第𝑗(𝑗=0~𝑛−1)位加上非零元素𝛽后得到的新的校验子定义为。
可以根据定理2直接确定第j位是不是错误位。但是当v=t时,不可计算,因此,我们不能直接计算可以根据定理2直接确定第j位是不是错误位。但是当v=t时,不可计算,因此,我们不能直接计算 对于v=t的情况,我们首先计算,如果=0,则j位为正确位。如果0,则可能是错误位。这种情况下,我们先求出β,使得。把β加到第j个位置上,码字的错误数可能变为t-1或者t+1。那么就能用来判断j个位置是否正确。如果,说明错误数为t-1,即j位是错误位置,且错误数为β;如果,说明错误数为t+1,即j位是正确位。 这种情况下,虽然不存在,但是,则的计算与无关。
Syndrome update 模块可以用计算来代替,并且计算可以直接得出各个测试向量的错误位置数。选择最优测试向量进行步进式译码。
最初的想法是:计算第一个测试向量的,如果测试向量的错误位置数为v,那么下一个测试向量的计算直接从v开始,即直接计算,找到错误位置数最小的那个测试向量进行译码,减小复杂度。最初的想法是:计算第一个测试向量的,如果测试向量的错误位置数为v,那么下一个测试向量的计算直接从v开始,即直接计算,找到错误位置数最小的那个测试向量进行译码,减小复杂度。 • 问题: • 1.对于,当错误位置数大于k的时候,可能为0也可能不为0。因此,不能从v开始算起,还得从t开始算起,存储量应该很大。 • 2.算法的可靠性还待验证。(C仿真) • 3.还停留在算法阶段,实现比较少,缺少对比。