Download

1 / 51
520 likes | 561 Views
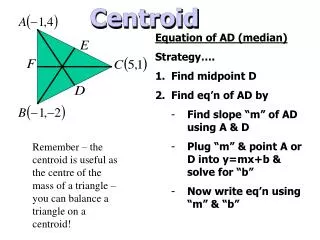
Centroid index Cluster level quality measure. Pasi Fränti. 3.9.2018. Clustering accuracy. P. Classification accuracy. Known class labels. Solution A:. Solution B:. Oranges. Oranges. 100 %. Precision = 5/7 = 71% Recall = 5/5 = 100%. Apples. Apples. 100 %. Precision = 3/3 = 100%

E N D
Centroid indexCluster level quality measure Pasi Fränti 3.9.2018
P Classification accuracy Known class labels Solution A: Solution B: Oranges Oranges 100 % Precision = 5/7 = 71% Recall = 5/5 = 100% Apples Apples 100 % Precision = 3/3 = 100% Recall = 3/5 = 60%
Clustering accuracy No class labels! Solution A: Solution B: ???
Internal index Sum-of-squared error (MSE) Solution B: Solution A: 11.3 31.2 30 40 18.7 8.8
External index Compare two solutions Solution B: Solution A: 5 5/7 = 71% 2/5 = 40% 2 3/5 = 60% 3 • Two clustering (A and B) • Clustering against ground truth
Set-matching based methods M. Rezaei and P. Fränti, "Set-matching measures for external cluster validity", IEEE Trans. on Knowledge and Data Engineering, 28 (8), 2173-2186, August 2016.
What about this…? Solution 2: Solution 1: Solution 3: ? ?
External index Selection of existed methods • Pair-counting measures • Rand index (RI) [Rand, 1971] • Adjusted Rand index (ARI) [Hubert & Arabie, 1985] • Information-theoretic measures • Mutual information (MI) [Vinh, Epps, Bailey, 2010] • Normalized Mutual information (NMI) [Kvalseth, 1987] • Set-matching based measures • Normalized van Dongen (NVD) [Kvalseth, 1987] • Criterion H (CH) [Meila & Heckerman, 2001] • Purity [Rendon et al, 2011] • Centroid index (CI) [Fränti, Rezaei & Zhao, 2014]
Point level vs. cluster level Cluster-level mismatches Point-level differences
Point level vs. cluster level Agglomerative (AC) ARI=0.91 ARI=0.82 Random Swap (RS) K-means ARI=0.88
Pigeon hole principle • 15 pigeons (clustering A) • 15 pigeon holes (clustering B) • Only one bijective (1:1) • mapping exists
Centroid index (CI) [Fränti, Rezaei, Zhao, Pattern Recognition 2014] empty CI = 4 15 prototypes(pigeons) 15 real clusters (pigeon holes) empty empty empty
Definitions • Find nearest centroids (AB): • Detect prototypes with no mapping: • Number of orphans: • Centroid index: Number of zero mappings! Mapping both ways
Example S2 1 1 2 IndegreeCounts 1 2 1 Mappings 1 1 0 1 1 1 1 1 0 Value 0 indicates an orphan cluster CI = 2
Example Birch1 Mappings CI = 7
Example Birch2 Mappings 1 0 1 1 Two clustersbut only one allocated 3 1 Three mappedinto one CI = 18
Example Birch2 Mappings 2 1 Two clustersbut only one allocated 0 1 1 0 Three mappedinto one 1 CI = 18
Unbalanced exampleK-means result KMGT CI = 4 500 0 2000 0 1 1 1011 492 4 2 458 560 0 989 490 0 K-means tend to put too many clusters here … … and too few here
Unbalanced exampleK-means result GTKM CI = 4 5 1 1 0 1 0 0 0
Mean Squared Errors Green = Correct clustering structure Raw numbers don’t tell much
Adjusted Rand Index [Hubert & Arabie, 1985] How highis good?
Normalized Mutual information [Kvalseth, 1987]
Normalized Van Dongen [Kvalseth, 1987] Lower is better
Centroid Similarity Index [Fränti, Rezaei, Zhao, 2014] Ok but lacks threshold
Centroid Index [Fränti, Rezaei, Zhao, 2014]
Bridge Accurate clustering GAIS-2002 similar to GAIS-2012 ? -0.04 -0.29 -0.29
GAIS’02 and GAIS’12 the same? Virtually the same MSE-values GAIS 2002 GAIS 2012 160.8 160.72 -0.04 160.68 160.6 -0.29 -0.29 160.43 -0.04 160.39 160.4 GAIS 2002 +RS(8M) GAIS 2002 +RS(8M) 160.2
GAIS’02 and GAIS’12 the same? But different structure! GAIS 2002 GAIS 2012 160.8 160.72 CI=17 160.68 160.6 CI=0 CI=1 160.43 CI=18 160.39 160.4 GAIS 2002 +RS(8M) GAIS 2012 +RS(8M) 160.2
Seemingly the same solutions Same structure “same family”
But why? • Real cluster structure missing • Clusters allocated like well optimized “grid” • Several grids results different allocation • Overall clustering quality can still be the same
RS runs 1M vs 8M CI=26 MSE=0.07% CI=26 MSE=0.02% B1 C1 A1 160.8 1M: 161.37 161.48 161.44 CI=1 MSE=0.15% CI=3 MSE=0.28% CI=1 MSE=0.09% 160.6 8M: 160.99 161.22 161.24 160.4 B8 C8 A8 CI=24 MSE=0.01% CI=26 MSE=0.16% 160.2
Three alternatives 3. Partition similarity 1. Prototype similarity Prototype must exist 2. Model similarity Derived from model
Partition similarity • Cluster similarity using Jaccard • Calculated from contigency table
x Split-and-Merge EM x Random Swap EM Gaussian mixture model 1 1 RI 0.98 ARI 0.84 MI 3.60 NMI 0.94 NVD 0.08 CH 0.16 1 1 1 1 3 1 CI=2 1 1 1 1 0 1
Gaussian mixture model CI=2 CI=1 CI=3 CI=0 CI=1 CI=0
KMGT 1 1 2 CI = 2 2 0 1 0
GTKM 1 1 1 0 CI = 1 1 1 2
SLGT 1 0 1 3 0 1 CI = 2
GTSL 0 2 2 0 0 2 CI = 3