Download

1 / 52
520 likes | 784 Views
ANTLR. ANother Tool for Language Recognition. Overzicht. Inleiding: Antlr: what’s in a name? Vertalers: lexers en parsers LL parser voordelen, akkefietjes Antlrworks: debugger Productieregels voor output Boomgrammatica (Antlr tree grammar) Boomparser (Antlr tree parser)

E N D
ANTLR ANother Tool for Language Recognition
Overzicht • Inleiding: Antlr: what’s in a name? • Vertalers: lexers en parsers • LL parser voordelen, akkefietjes • Antlrworks: debugger • Productieregels voor output • Boomgrammatica (Antlr tree grammar) • Boomparser (Antlr tree parser) • Programmatransformaties • Besluit
Inleiding ANTLR = ANother Tool for Language Recognition • programma om “compilers” te schrijven • genereert parser voor front-end van compiler of voor domein-specifieke toepassing ANTLRWorks = antlr programmeeromgeving • auteurs • antlr:Terence Parr (UoSF) • antlrworks: Jean Bovet (master student) • locatie:http://www.antlr.orgtutorial:http://www.ociweb.com/jnb/jnbJun2008.html • boek: the definitive Antlr reference CT467
Inleiding • ANTLR v3 is geschreven in Java • Genereert gramatica’s in Java, C, C#,.. • Motor = LL(*) top-down parser • Vgl. lex/yacc: LR bottom-up • Antlr gaat extra mile: • Antlrworks: debug grammatica tijdens parsen • Tree parser: parser van interne boomvoorstelling • String template (source source herschrijven)
Vertaler • Wat is een vertaler? • Een vertaler leest een invoertekst, analyseert de structuur en schrijft een uitvoertekst • Werking? • Invoertekst is een stroom bytes.Deze wordt naar “handelbare” vorm gebracht in 2 fasen: Lexicale analyse: vormt woorden alfabetSemantische analyse: vormt zinnen taal
Lexicale Analyse Doel:“uit de stroom van bytes betekenisvolle woorden en leestekens te halen die eigen zijn aan de programmeertaal.” = tokens met attributen Vb.: 5 = geheel getal met waarde 5a = variabele met naam “a”
Lexicale Analyse Tokens in EBNF, in hoofdletters, vb: NUM : ('0'..'9')+; ALF : ‘A'..‘Z'|’a’..‘z'; ID : ALF (ALF|NUM)*; + : ≥ 1 (herhalingsteken, minstens 1) * : ≥ 0 (herhalingsteken, minstens 0) | : “of” Resultaat: “tokens”
Grammaticale Analyse Grammatica definieert geldige zinnen, in kleine letters, bv. expr: expr : NUM | ID | expr '+' expr; Voldoet: 3, alfa, a+b; ander vb: var : ID; assign : var '=' expr; Resultaat: “grammaticaregels”
Grammaticale Analyse Parsing met productieregels non-terminals terminals
Grammaticale Analyse Afleiding (derivation) = substitutie van nonterminals (ouder) door zijn productie (kinderen) parseboom
Grammaticale Analyse Rechtse of linkse afleidingsubstitutie van meest rechtse of meest linkse nonterminal door productie parseboom Toepassing: a : = 7 ; b : = c + (d := 5 + 6 , d) Lexicale tokenstroom:id : = num; id : = id + (id := num + num, id)
Voorbeeld a : = 7 ;b := c + (d := 5 + 6 , d) Lexicale tokenstroom:id : = num; id : = id + (id := num + num, id) Afleiding 1 2 3 4 5 6 7 8 10 9 11 12
Afleiding 1 • Voorbeeld • a : = 7 ;b := c + (d := 5 + 6 , d) • Lexicale tokenstroom:id : = num; id : = id + (id := num + num, id) 2 3 4 5 6 7 8 10 9 11 12
LinkseAfleiding • Voorbeeld • a : = 7 ;b := c + (d := 5 + 6 , d) • Lexicale tokenstroom:id : = num; id : = id + (id := num + num, id) 1 2 4 5 3 6
Contextvrije grammatica Contextvrij = substitutie kan uitgevoerd worden onafhankelijkvan de context = symbolen voor en na de substitutie Ambigue grammatica: waneer meerdere parsebomen mogelijk zijn
Predictieve Parser (LL) Principe:de afleidingsregel voor non-terminals wordt bepaald door het ingelezen token, d.w.z. door de ingelezen terminal. Kan gerealiseerd worden door een Recursive descent parser
Predictieve Parser (LL) Recursieve afdaling algoritme: 1 functie voor elke niet-terminaal 1 case voor elke productie Vb.: grammatica
3.2. Predictieve parsing Recursieve afdaling algoritme:
Grammatica in Antlr TOKENS = terminals regels = nonterminals grammar = regels + tokens prog = startregel grammar prog; prog : assign+ EOF; assign : var '=' expr '\r\n'+; var : ID; expr : NUM | ID | expr '+' expr; NUM : ('0'..'9')+; ALF : ('a'..'z'|'A'..'Z')+; ID : ALF (ALF|NUM)*;
Grammatica in AntlrWorks In AntlrWorks:
Linkse recursie conflict In AntlrWorks:
Linkse recursie conflict Ambiguïteit: welke regel start met dit token? bij input ID: expr ID of expr expr + expr ? beide regels kunnen met ID starten...
Linkse recursie conflict Regel E start met E [1] E E + T[2] E T First(X) start-tokens van regel (X) First(E) = First(E+T) U First(T) welke productie: 1 of 2 ?
Linkse recursie herschrijven Oplossing: a) herken ET|E+T als ET +T +T + .... +T b) herschrijf tot rechtse recursie E T (+T)*
Linkse recursie herschrijven Linkse recursiewegwerken grammar prog; prog : assign+ EOF; assign : var '=' expr '\r\n'+; var : ID; expr : NUM | ID | expr '+' expr; NUM : ('0'..'9')+; ALF : ('a'..'z'|'A'..'Z')+; ID : ALF (ALF|NUM)*; Linkse recursie wegwerken door extra term
Linkse recursie herschrijven Linkse recursiewegwerken grammar prog; prog : assign+ EOF; assign : var '=' expr '\r\n'+; var : ID; term : NUM | ID; expr : term (‘+’ term)*; NUM : ('0'..'9')+; ALF : ('a'..'z'|'A'..'Z')+; ID : ALF (ALF|NUM)*; Linkse recursie wegwerken door extra term
Debuggen in AntlrWorks Eenvoudige grammatica Debuggen alfa=5 b=2+a
Debuggen in AntlrWorks Debuggen: input alfa=5 b=2+a
Debuggen in AntlrWorks Debuggen: input + startregel alfa=5 b=2+a
Debuggen in AntlrWorks Debuggen alfa=5 b=2+a
Gegenereerde bestanden Wat genereert ANTLRWorks nu uit grammatica prog.g? • progLexer.java, progParser.java • main: __Test__.java parser lexer • input: __Test__input.txt
Tokens en parseboom Debuggen – tokens + parseboom alfa=5 b=2+a
Gegenereerde bestanden Structuur van het testprogramma:
Acties of producties toevoegen • Acties bij herkenning van tokens of regels regels: groen tokens: blauw grammatica: “token” lexer: “A”... “U”
Acties of producties toevoegen • @members = helper code • actie: telklinkers
Acties of producties toevoegen • @members = helper code • actie: telklinkers
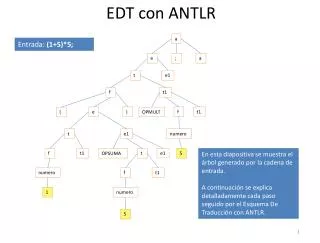
Acties: tel klinkers • Input: “aaeaiiou” • Output en Afleidingsboom
Lexicale en grammaticale analyse FRONT-END • Lexicale analyse produceert tokenstoken = type van woord (bv. getal, “if”)
Lexicale en grammaticale analyse FRONT-END • Grammaticale analyse produceert syntax.AST = abstracte syntaxboom met betekenis van programma bewaart. Meestal is er extra informatiein symbooltabellen, afhankelijkheidsgrafen ...
Lexicale analyse en parsing BACK-END • De back-end loopt de AST af en genereert de output
Boomgenerator • ANTLR genereert ook “CommonTree” bomen • Nut: overzichtelijke structuur, boomvoorstellingen in fasen, programmatransformaties. • CommonTree bomen kunnen gegenereerd worden met de optie {output=AST}.
Boomgenerator • CommonTree bomen kunnen gegenereerd worden met de optie {output=AST}. • Boomoperaties zijn productieregels:operator om boom te maken: ^(... ...) • Vb.: ^(wortel blad_1 ... blad_n) genereert
Boomgenerator • Boom-grammatica: • De output: via apart testprogramma....
Boomgenerator • Testprogramma: • ast = parser g g.prog_ast getTree() • print ast met ast.toStringTree().
Boomgenerator • Resultaat van boomgeneratiegrammatica prog_ast: • = gewone output ($prog_ast.text) + tree ouput (ast.toStringTree()).
Boomgenerator • ANTLR genereert “CommonTree” bomen • Nut: programmatransformaties. • Voorbeeld: for-lus 2x ontrollen in f.g
Boomgenerator • TreeRewrite.g leest “CommonTree” genereert getransformeede lus • Genererende tokens uit = f.g • Grammatica f wordt ook gebruikt voor testprogramma in AntlrWorks!
Boomgenerator • TreeRewrite.g leest “CommonTree” genereert getransformeede lus • Genererende tokens uit = f.g • Grammatica f wordt ook gebruikt voor testprogramma in AntlrWorks!
Boomgenerator • TreeRewrite leest “CommonTree” bomen en genereert getransformeede lus
Boomgenerator • Lustransformatie: • Input: Output: for (i=0; i < n; i++) { s = f(i); v = g(k); } for (i=0; i < n; i++) { s = f(i); v = g(k); s = f(i); v = g(k); }