Download

1 / 33
340 likes | 558 Views
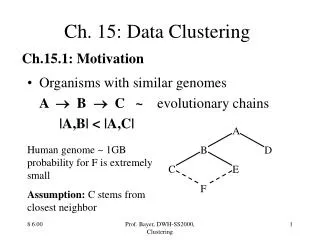
Data Clustering. Clustering – A Naïve Example. Clustering 1 - {0}, {1,3}, {2} Depending on how similarity of data objects is considered could also be: Clustering 2 - {0,2}, {1,3}. Clustering.

E N D
Clustering – A Naïve Example Clustering 1 - {0}, {1,3}, {2} Depending on how similarity of data objects is considered could also be: Clustering 2 - {0,2}, {1,3}
Clustering • “Assignment of a set of observations into groups called clusters so that observations in the same cluster are similar in some sense” • Some data contains natural clusters – easy to deal with • In most cases no ideal solution – only ‘Best Guesses’
Supervised and Unsupervised Learning So, what is the difference between say: classification and clustering? • Clustering belongs to a set of problems known as unsupervised learning tasks • Classification involves the use of data 'labels' or 'classes‘ • In Clustering there are no labels - much more complex task.
So, how is clustering performed? • In the most common techniques a distance measure is employed • Most naïve include distance measures • Referring to the earlier example is distance between objects:
So, how is clustering performed? • How we use these distances determines the cluster assignments for each of the objects in the dataset • Other measures include Hamming distance C A T One single change, so distance = 1 M A T
So, how is clustering performed? • Other aspects which affect Clustering • Number of clusters? • Predefined or natural clusterings? • How are objects similar and how is this defined?
How can we tell if our clustering is any good? • Cluster validity - as many measures as there are clustering approaches! • Many attempts: no correct answers only best guesses! • Few standardised measures but: • Compactness – members of the same cluster ‘tightly-packed’ • Separation – clusters should be widely separated
How can we tell if our clustering is any good? • Dunn Index The ratio between the minimal intracluster distance to maximal intercluster distance
How can we tell if our clustering is any good? • Davies-Bouldin Index A function of the ratio of the sum of within-cluster scatter to between-cluster separation where: n is the number of clusters, Sn is the average distance of all objects from the cluster to their respective cluster centre, and S(Qi,Qj) is the distance between cluster centres Small values are therefore indicative of good clustering
How can we tell if our clustering is any good? • C – index Where: • S is the sum of distances over all pairs of objects in the same cluster • l is the number of those pairs. • Then, Sminis the sum of the l smallest distances if all pairs of objects are considered (i.e. if the objects can belong to different clusters). • Smaxis the sum of the l largest distance out of all pairs. Again, a small value of C indicates a good clustering.
How can we tell if our clustering is any good? • Class Index Special case where object labels may be known but we would like to assess how well the clustering method predicts these Solution 1 - {0}, {1,3}, {2} = 1.0 (all objects clustered correctly) Solution 2 - {0,2}, {1,3} = 0.75 ( 3 of 4 objects clustered correctly)
What about clustering the columns as well as the rows? • Yes, can be done also – known as ‘Biclustering’ • Generates a subset of rows which exhibit similar behaviour across a subset of columns.
Clustering Algorithm Types • 4 basic types • Non Hierarchical or Partitional: k-Means/C-means/etc. • Hierarchical: Agglomerative/Divisive/etc. • GA-based/Swarm/Leader etc. • Others: Data Density etc.
Non-Hierarchical/Partitional Clustering Iterative process: Partitional Algorithm initial partition of k clusters perform random assignment of data objects to clusters do (1) Calculate new cluster centres from membership assignments (2) Calculate membership assignments from cluster centres until cluster membership assignment stabilizes
Non-Hierarchical/Partitional Clustering Unclustered Data Initial random centres 1st Iteration Final Clustering 2nd Iteration
Hierarchical Agglomerative • Clusters are formed by either: • Dividing the bag or collection of data into clusters or • Agglomerating similar clusters • Metric required to decide when smaller clusters of objects should be merged (or split) Divisive
Fuzzy Sets • Extension of conventional sets • Deal with vagueness • Elements of fuzzy sets are allowed partial membership described by a membership function VERY OLD
Fuzzy Techniques • Fuzzy C-Means (FCM) (Dunn-1973/Bezdek-1981) – Non-Hierarchical Approach • Data objects allowed to belong to multiple ‘fuzzy’ clusters • Maximisation of objective function • Numerous termination criteria
FCM Problems: • Specification of parameters up to 4 different parameters • Relies on simple distance metrics • Outliers still a problem
FCM Simple Example: Following 1st Iteration Memberships calulated from initial means/centres Following 2nd Iteration
Fuzzy agglomerative hierarchical clustering (FLAME) Fuzzy Approach – employs data density measure Basic concepts: • cluster supporting object (CSO) object with density higher than all its neighbors; • Outlier object with density lower than all its neighbors, and lower than a predefined threshold; • Everything else all other objects Algorithm uses these concepts to form clusters of data objects
FLAME • Algorithm comprises three steps • For each data object • Find the k-nearest neighbours • Use the proximity measurements to calculate density • Use density to define the object type (CSO /Outlier/other) • Assign initial Fuzzy Memberships • Local Approximation of Fuzzy Memberships • Initialization of fuzzy membership: Each CSO is assigned with fixed and full membership to itself to represent one cluster; • All outliers are assigned with fixed and full membership to the outlier group; • The rest are assigned with equal memberships to all clusters and the outlier group • Then fuzzy memberships of all the ”rest” objects are updated by a converging iterative procedure called Local/Neighborhood Approximation of Fuzzy Memberships - fuzzy membership of each object is updated by a linear combination of the fuzzy memberships of its nearest neighbors. • Construct clusters from fuzzy memberships
FLAME 2D Example
FLAME • Problems • Still requires parameters: k, neighbourhood density, etc. • High computational overhead • But... • Produces good clusters and can deal with non-linear structures well • Effective mechanism for dealing with outliers
“Rough Set” Clustering • Rough k-Means proposed by Lingras and West • Not strictly Rough Set Clustering • Borrows some of the properties of RST but not all core concepts • Can in reality be viewed as binary-interval based clustering
“Rough Set” Clustering • Utilises the following properties of RST to cluster data objects: • A data object can only be a member of one lower approximation • A data object that is a member of the lower approximation of a cluster is also member of the upper approximation of the same cluster. • A data object that does not belong to any lower approximation is member of at least two upper approximations.
“Rough Set” Clustering • Two main concepts that are borrowed are • Upper and Lower approximation concepts • These concepts are used to generate centres
“Rough Set” Clustering Calculation of the means or centres for each cluster Weighting of lower approx and boundary affects the values of each mean/centre
“Rough Set” Clustering Simple 2D Example
Real-World Applications (Apart from grouping data points what is clustering actually used for?) • Google Search – Data clustering is one of the core AI methods used for the search engine. Adsense also. • Facebook uses data clustering techniques in order to identify communities within large groups • Amazon uses recommender systems to predict a user's preferences based on the preferences of other users in the same cluster • Other Applications: • Mineralogy • Seismic analysis and survey, • Medical Imaging, ...etc.
Summary • Clustering is a complex problem • No ‘right’ or ‘wrong’ solutions • Validity measures are generally only as good as the ‘desired’ solution