Download

1 / 17
190 likes | 440 Views
Contry. Population. City. Cairo. Egypt. 9500000. London. England. 9400000. Paris. France. 2200000. Rome. Italy. 2800000. The ADT Hash Table. What is a table?.

E N D
Contry Population City Cairo Egypt 9500000 London England 9400000 Paris France 2200000 Rome Italy 2800000 The ADT Hash Table What is a table? A collection of items, each including several pieces of information. One of these pieces of information is a search key. A table is another example of ADT whose insertion, deletion and retrieval of items is made by value and not by position. items may be in order with respect to the search key. items may or may not have the same search key “City” is the search key • Efficient retrieval of items, if based on search key value: e.g. “Retrieve the population of London”. Hash Tables
Access Procedures for Tables • createTable( ) // post: Creates an empty table. • isEmpty( ) // post: Determines whether a table is empty. • getSize( ) • // post: Returns the number of entries in the table. • add(key, newElem) • // post: Adds the pair (key, newElem) to the table in its proper order according to // its key. • remove(key) • // post: Removes from the table the entry with given key. Returns either the value// post: associated with the given key or null if such entry does not exist. • getValue(key) • // post: Retrieves the value that corresponds to a given key from a table. Returns null// post: if no such entry exists in the table. Hash Tables
The add operation Elem (or search key) 0 add(searchKey, newElem){ i = the array index that the address calculator gives us for the searchKey of newElem. table[i] = newElem } 1 2 Addresscalculator 3 4 5 . . . . . . method “add” is of the order O(1) (it requires constant time). Introducing the ADT Hash Table Binary Search Tree: a particular type of binary tree that enables easy search of specific items. But: • efficiency of the search method depends on the form of the binary search trees,• in the best case scenario (balanced trees), for trees with 10,000 items, operations of “retrieve”, “insert”, and “delete” would still require O(log10,000) = 13 steps. Is there a more efficient way of storing, searching and retrieving data? Hashing: the basic idea Hash Tables
pseudocode pseudocode getValue(searchKey)// post: Returns the element that has a matching // post: searchKey. If not found, it returns null. i = the array index that the address calculator gives us, for element whose search key is equal to searchKey if (table[i].getKey( ) equals searchKey) return table[i].getValue(); else return null; The retrieve operation The remove operation remove(searchKey)// post: Deletes element that has a matching searchKey, // post: and returns true; otherwise returns false. i = the array index that the address calculator gives us for the given searchKey if (table[i].getKey( ) equals searchKey){ delete element from table[i]; return true; } else return false getValue(key) and remove(key) are also operations of the order O(1) (require constant time). Hash Tables
Definition The ADTHash Table is an array (i.e. array table) of elements (possibly associated with a search key unique for each element), together with an hash function and access procedures. • The access procedures include insertion, deletion, and retrieval of an element by means of the hash function. • A hash table can also be empty – no element is stored in the array table. • The hash functiondetermines the location in the table of a new element, usingits value (or search key if any). In a similar way, permits to locate the position of an existing element. • The hash functiontakes a search key and maps it into an integer array index. • A perfecthash functionis an ideal function that maps each search key into a unique array index. Hash Tables
Understanding how Hash Functions work Example: the table is a Directory Database with • Less than 10,000,000 people • Each person with his/her telephone number, as search key, • The telephone number is of type int: e.g., 123 4567 Store the person with number 123 4567 in table[1234567] 10,000,000 memory locations to spare! Numbers are regional. Store the person with number 123 4567 in table[4567] 10,000 memory locations to spare! Hash function: 1234567 4567 Takes a value of the search key and transforms into an integer used as array index value. Note: the above is an example of a perfecthash function Hash Tables
The collision problem Aperfect hash functionis an hash function that maps each search key into a unique array index. It is possible if we know in advance all the possible search key values. In practice, we don’t know all possible search key values. An hash function can map two or more search keys into the same integer array index: x y and h(x) = h(y) = i. A collision is when two or more elements with search keys x and y are told by the hash function to be stored in the same array location table[i], where i = h(x) = h(y).The two search keys x and y are said to have collided. A way for solving collisions is to provide appropriate collision-resolution schemes. Basic requirements for a “good” hash function: - be easy and fast to compute - place elements evenly throughout the hash table (i.e. minimizes collisions) Hash Tables
Selecting digits: given a search key number composed of a certain number of digits the hash function picks digits at specific places in the search key number: e.g. h(001364825) = 35(select the forth and the last digit) Folding: given a search key number, the function defines the index by adding up allthe digits in the search key. e.g. h(001364825) = 29(add the digits) Or by first grouping the digits and then adding them up. e.g. h(001364825) = 001+364+825 = 1190 (group the digits and add them up) Examples of Hash Functions (1) Assume hash functions have integers as search keys. • Simple and fast, • Generally, does not evenly distribute the elements in the hash table Note: you can apply more than one hash function to a search key Hash Tables
Modulo arithmetic: given a search key number, the function defines the index to be the modulo arithmetic of the search value with some fix number. e.g. h(001364825) = 001364825 mod tableSize Examples of Hash Functions (2) • We get lots of collision • We can more evenly distribute the elements in the table, if tableSize is prime Converting character string to an integer: given a search key is a string, we could first convert it into an integer, and then apply the hash function. We could think ofusing different ways of converting strings into a number to get better hash functionresults. e.g. h(“NOTE”) = 78 + 79 + 84 + 69, using the ASCII values of the letters. h(“TONE”) = 78 + 79 + 84 + 69. Hash Tables
. . . 7597 i=7597 mod 101=22 22 4567 i+1 23 0628 i+2 24 3658 i+3 25 . . . . . . Collision-resolution schemes Two main approaches: 1. Assign another location within the hash table to the new collided element. 2. Change the structure of the hash table: each table[i] can accommodate more than one element. 1. Open addressing schemes:In case of collision, probe for some other empty location to place the element in. The probe sequence of locations used by the add procedure has to be efficiently reproducible by the delete and retrieve procedures. Linear probing: Table locations have to be defined to be in oneof three states: empty, deleted, occupied;otherwise, after deletion, the retrieve operation might stop prematurely. Elements tend to cluster together. Parts of the table might be too dense and others relatively empty, making the hashing less efficient. Hash Tables
0 . . . h(58) = 3 h(14) 58 3 collision . . . h(91) h(91) = 3h'(91) = 7, i=(3+7 +7)%11 6 91 . . . h(14) = 3h'(14) = 7, i=3+7 collision h(91) 10 14 Open addressing schemes (continued) Double hashing: probe sequence is not sequential, but defined using the given search key. It uses the hash function “h” to calculate the initial index, and a second function “h' ” to calculate the size of the probing step, using the same search key. The function h' has the following properties: - h' (key) 0 - h' h Example: h (key)= key mod 11h' (key) = 7 – (key mod 7) Hash Tables
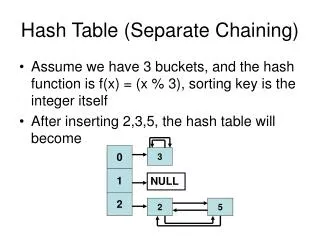
Restructuring the Hash Table Alter the structure of the hash table so to allow more than one element to be stored at the same location. The array table is defined so that each location table[i] is itself an array, called bucket. Buckets Limitation: how to choose the size of each bucket? The array table is defined as an array of linked lists. Each location table[i]is a reference to a linked list, called the chain, of all the elements that have collided to the same integer i. Separate Chaining public class ChainNode{ private keyedElem elem; private ChainNode next; ……. } public class HashTable{ private final int TABLESIZE=101 private ChainNode[ ] table; private int size; ….. } Hash Tables
Table …. 0 …. 1 …. 2 …. 3 . . . …. Size-1 A Separate Chaining Structure Each location of the hash table contains a reference to a linked list Hash Tables
pseudocode pseudocode getValue(searchKey){i = hashIndex(searchKey); node = table[i]; while((node null) && (node.getElem( ).getKey( ) searchKey)) { node = node.getNext( );} if (node != null){ return node.getElem( ); } else return null;} add(key, newElem){ searchKey = key; i = hashIndex(searchKey); node = reference to a new node containing newElem; node.setNext(table[i]); table[i] = node; } Implementing Hash Table with separate chaining “hashIndex” is a protected procedure of the class HashTable. Hash Tables
Hashing is the process that calculates where in an array a data element should be, rather then searching for it. It allows efficient retrievals, insertions and deletions. • Hash function should be easy to compute and it should scatter the elements evenly throughout the table. • Collisions occur when two different search keys hash into same array location. Two strategies to resolve collisions, using probing and chaining respectively. Summary Hash Tables
What is an Abstract Data Type Introduce individual ADTs ListsStacksQueuesTreesHeaps AVL TreesHash Tables Understand the data type abstractly Define the specification of the data type Use the data type in small applications,basing solely on its specification Implement the data type Static approach Dynamic approach Conclusion Some fundamental algorithms for some ADTs:pre-order, in-order and post-order traversal,heapsort Hash Tables
The End Hash Tables