Download

1 / 48
1.3k likes | 2.3k Views
Hash Table. Data Structures. Hash Table. A hash table is a data structure that offers very fast insertions and searching for objects that are inserted into the container .

E N D
Hash Table Data Structures
Hash Table • A hash table is a data structure that offers very fast insertions and searching for objects that are inserted into the container. • Hash tables are very efficient and useful in all types of applications and a good understanding of them can be very useful. • In games a hash table can be used, for example, in a massively multiplayer online role playing game for storing a database of players and their stats, items, weapons and equipment, character information, and so forth. • Hash tables are based on the array data structure.
Hash Table • In general, hash tables work by taking an object and hashing it to an integer. • This integer is used as the array position for that object in the hash table. • Hashing a value refers to executing an algorithm on the object to create an integer that lies within the array bounds of the hash table. • Every object that is inserted into the hash table has its own key. This key is an identifier that is hashed into an array index and used for the object. The key can be anything, even the object itself. • The code used to hash an object into an array index is called a hash function.
Hash Table Some general uses for hash tables include but are not limited to the following: • Spell checkers • Database systems • Dictionaries • Phone directories • Implementation of a symbol table for a compiler in a general and game scripting system • Implementation of a caching system • Implementation of a transposition table in a chess game • List of players in a massively multiplayer online role-playing game
Hash Table • Even with a large number of items, a search for an object in a hash table can be almost instantaneous in some situations. • This speed due to hash tables being based on the array data structure. When the array index of an object is known, it is found quickly. • The trick is calculating an object’s array index position, so that it can be placed within the hash table and quickly retrieved at a moment’s notice.
Hash Table Because hash tables are based on arrays, they inherit their weaknesses as well as their strengths. • Hash tables are expensive and hard to expand, because the positions of the objects within a hash table depend on the size of the data structure; a change in size invalidates all objects already inside of the container. • When using open addressing, the performance of hash tables can decrease as the container becomes full. • Objects cannot be ordered easily within a hash table. • Looking up objects in a hash table is fast and uses array subscripts. • Copying hash tables can be expensive and requires that both tables be of the same size to avoid having to rehash all existing elements. • Insertions into a hash table are fast.
Hash Table: When to Use • Hash maps should be used when you are required to store a huge amount of data, • and there is no need to keep the data sorted (the order of elements is irrelevant), • but it is important to have fast searching. *If it is important for the elements to be in a particular order, however, then you should implement your hash as a map data structure. *Elements in a map are always sorted but not in a hash table. The disadvantage to a map is that it is usually stored as binary tree, meaning that it will take longer to find elements in a map.
Why Hash Table? • Hash tables are good for doing a quick search on things. • For instance if we have an array full of data (say 100 items). If we knew the position that a specific item is stored in an array, then we could quickly access it. For instance, we just happen to know that the item we want it is at position 3: myitem=myarray[3]; • With this, we don't have to search through each element in the array, we just access position 3. • The question is, how do we know that position 3 stores the data that we are interested in? • This is where hashing comes in handy. Given some key, we can apply a hash function to it to find an index or position that we want to access.
Hashing hash function hash table 0 1 key pos 2 3 : : (TABLESIZE – 1)
Hashing hash table 0 hash function 1 “Kruse” 5 2 3 4 Kruse 5 6
What is the hash function? • A hash function is an algorithm that takes a value and compresses it into the range of the hash table’s array. • This value is known as the key, and it can be anything from a string, to a number, and so fourth. The hash value of the key depends on the size of the hash table’s array. • A change in the array size will invalidate all hashed keys in the table, which will require them to be rehashed and the existing objects repositioned to new elements. • When a hash table is created, its size can be a prime number that is roughly twice the number of elements that will be inserted into the table. • Using a size that is twice the predicted number of inserted elements will likely decrease the number of collisions in the set.
What is the hash function? • There are many different hash functions. Some hash functions will take an integer key and turn it into an index. A common one is the division method. • Division method (one hash method for integers) • Using modulus division is the most common hash method • key % m_size; • Dividing by a prime number results in fewer collisions (good distribution of hash values)
Hash Functions Division method (one hash method for integers) Let's say you had the following numbers or keys that you wanted to map into an array of 10 elements: 123456123467123450 To apply the division method, you could divide the number by 10 (or the maximum number of elements in the array) and use the remainder (the modulo) as an index. The following would result: 123456 % 10 = 6 (the remainder is 6 when dividing by 10) 123467 % 10 = 7 (the remainder is 7) 123450 % 10 = 0 (the remainder is 0) These numbers would be inserted into the array at positions 6, 7, and 0 respectively.
Hash Functions What happens when the keys aren't integers? You have to apply another hash function to turn them into integers. Effectively, you get two hash functions in one: function to get an integer function to apply a hash method to get an index to an array
Commonly Used Hash Functions Suppose that each key is a string. The following C++ function uses the division method to compute the address of the key: inthashFunction(char *key, intkeyLength) { int sum = 0; for(int j = 0; j <= keyLength; j++) sum = sum + static_cast<int>(key[j]); return (sum % HTSize); //HTSize is hash table size }//end hashFunction
What is a Hash Table ? • The simplest kind of hash table is an array of records. • This example has 701 records. [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700] . . . An array of records
Each record has a special field, called its key. In this example, the key is a long integer field called Number. What is a Hash Table ? [ 4 ] Number 506643548 [ 4 ] [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 5 ] [ 700] . . .
The number might be a person's identification number, and the rest of the record has information about the person. What is a Hash Table ? [ 4 ] Number 506643548 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700] . . .
When a hash table is in use, some spots contain valid records, and other spots are "empty". What is a Hash Table ? Number 281942902 Number 233667136 Number 506643548 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
In order to insert a new record, the key must somehow be converted toan array index. The index is called the hash valueof the key. Inserting a New Record Number 281942902 Number 233667136 Number 506643548 Number 155778322 . . . Number 580625685 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Typical way create a hash value: Inserting a New Record Number 281942902 Number 233667136 Number 506643548 Number 155778322 . . . Number 580625685 (Number mod 701) What is (580625685 mod 701) ? [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Typical way to create a hash value: Inserting a New Record Number 281942902 Number 233667136 Number 506643548 Number 155778322 . . . Number 580625685 (Number mod 701) What is (580625685 mod 701) ? 3 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
The hash value is used for the location of the new record. Inserting a New Record [3] Number 281942902 Number 233667136 Number 506643548 Number 155778322 . . . Number 580625685 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
The hash value is used for the location of the new record. Inserting a New Record Number 281942902 Number 233667136 Number 580625685 Number 506643548 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Hash Function • Hashing maps keys from: • Large range of integers into smaller range of integers • Non integer into small range of integers • Problem: collisions • Two keys can have the same hash value • Collisions are inevitable*, see: • “Birthday Paradox” (Probability Theory) • Can be tested: write down your birthday in the attendance sheet… • See if this birthday paradox is true… • “Pigeonhole Principle”
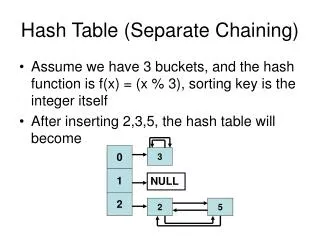
Collision Resolution • Algorithms to handle collisions • Two categories of collision resolution techniques • Open addressing, or closed hashing, is a method of collision resolution in hash tables. With this method a hash collision is resolved by probing, or searching through alternate locations in the array (the probe sequence) until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table. • collisions result in storing one of the records at another slot in the table (closed hashing) • Chaining (or open hashing):keys are stored in linked lists attached to cells of a hash table. in this strategy, none of the objects are actually stored in the hash table's array; instead once an object is hashed, it is stored in a list which is separate from the hash table's internal array. • collisions are stored outside the table (open hashing)
Collision Resolutions • Separate Chaining • Use Linked List • Harder to implement • It takes bigger memory space for storing Linked List pointers • Open Addressing, usually better than Chaining • Linear Probing • Quadratic Probing • Double Hashing
Here is another new record to insert, with a hash value of 2. Collisions My hash value is [2]. Number 281942902 Number 233667136 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
This is called a collision, because there is already another valid record at [2]. Collisions When a collision occurs, move forward until you find an empty spot. Number 281942902 Number 233667136 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
This is called a collision, because there is already another valid record at [2]. Collisions When a collision occurs, move forward until you find an empty spot. Number 281942902 Number 233667136 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
This is called a collision, because there is already another valid record at [2]. Collisions When a collision occurs, move forward until you find an empty spot. Number 281942902 Number 233667136 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
This is called a collision, because there is already another valid record at [2]. Collisions The new record goes in the empty spot. Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
The data that's attached to a key can be found fairly quickly. Searching for a Key Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Calculate the hash value. Check that location of the array for the key. Searching for a Key My hash value is [2]. Not me. Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Keep moving forward until you find the key, or you reach an empty spot. Searching for a Key My hash value is [2]. Not me. Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Keep moving forward until you find the key, or you reach an empty spot. Searching for a Key My hash value is [2]. Not me. Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Keep moving forward until you find the key, or you reach an empty spot. Searching for a Key My hash value is [2]. Yes! Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
When the item is found, the information can be copied to the necessary location. Searching for a Key My hash value is [2]. Yes! Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . Number 701466868 [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ]
Records may also be deleted from a hash table. Deleting a Record Please delete me. Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 506643548 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Records may also be deleted from a hash table. But the location must not be left as an ordinary "empty spot" since that could interfere with searches. Deleting a Record Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Records may also be deleted from a hash table. But the location must not be left as an ordinary "empty spot" since that could interfere with searches. The location must be marked in some special way so that a search can tell that the spot used to have something in it. Deleting a Record Number 281942902 Number 233667136 Number 701466868 Number 580625685 Number 155778322 . . . [ 0 ] [ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 700]
Summary • Hash tables store a collection of records with keys. • The location of a record depends on the hash value of the record's key. • When a collision occurs, the next available location is used. • Searching for a particular key is generally quick. • When an item is deleted, the location must be marked in a special way, so that the searches know that the spot used to be used.
Hash implemented as unordered map • An unordered map is a hash table. • The data in an unordered_map is placed in a bucket depending on the result of a hashing function (and the order is not as easily predictable as a map container).
Hash implemented as unordered map #include <iostream> #include <string> #include <unordered_map> using namespace std; intmain() { unordered_map< int, string > m; m[1] = "one"; m[2] = "two"; m[4] = "four"; m[3] = "three"; m[2] = "TWO!"; cout<< m[2] << endl; m.clear(); return 0; } // for Visual Studio 2010
Hash implemented as unordered map #include <iostream> #include <string> #include <unordered_map> int main() { std::unordered_map<std::string, int> months; months["january"] = 31; months["february"] = 28; months["march"] = 31; months["april"] = 30; months["may"] = 31; months["june"] = 30; months["july"] = 31; months["august"] = 31; months["september"] = 30; months["october"] = 31; months["november"] = 30; months["december"] = 31; std::cout << "september -> " << months["september"] << std::endl; std::cout << "april -> " << months["april"] << std::endl; std::cout << "december -> " << months["december"] << std::endl; std::cout << "february -> " << months["february"] << std::endl; return 0; } // for Visual Studio 2010 http://en.wikipedia.org/wiki/Unordered_associative_containers_%28C%2B%2B%29
Hash Functions for C++ Unordered Containers Please read http://marknelson.us/2011/09/03/hash-functions-for-c-unordered-containers/ #include <iostream> #include <unordered_map> #include <string> using namespace std; typedefstring Name; intmain(intargc, char* argv[]) { unordered_map<Name,int> ids; ids["Mark Nelson"] = 40561; ids["Andrew Binstock"] = 40562; for ( auto ii = ids.begin() ; ii != ids.end() ; ii++ ) cout<< ii->first << " : " << ii->second << endl; return 0; } // for Visual Studio 2010
Hash Functions for C++ Unordered Containers Please read http://marknelson.us/2011/09/03/hash-functions-for-c-unordered-containers/ A very common change to the previous program will be in the use of a simple class or structure to hold the person’s name, keeping first and last names separate, and using the built-in pair class to hold the name: // // This program uses a specialization of // std::hash<T> to provide the function // object needed by unordered_map. // // Compile this example with Visual Studio 2010 // or g++ 4.5 using -std=c++0x // #include <iostream> #include <unordered_map> #include <string> #include <functional> using namespace std; typedef pair<string,string> Name; namespace std { template <> class hash<Name>{ public : size_t operator()(const Name &name ) const { return hash<string>()(name.first) ^ hash<string>()(name.second); } }; }; int main(intargc, char* argv[]) { unordered_map<Name,int> ids; ids[Name("Mark", "Nelson")] = 40561; ids[Name("Andrew","Binstock")] = 40562; for ( auto ii = ids.begin() ; ii != ids.end() ; ii++ ) cout << ii->first.first << " " << ii->first.second << " : " << ii->second << endl; return 0; } // for Visual Studio 2010