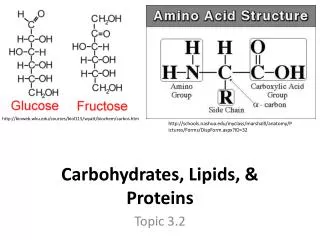
Download
1 / 34
340 likes | 460 Views
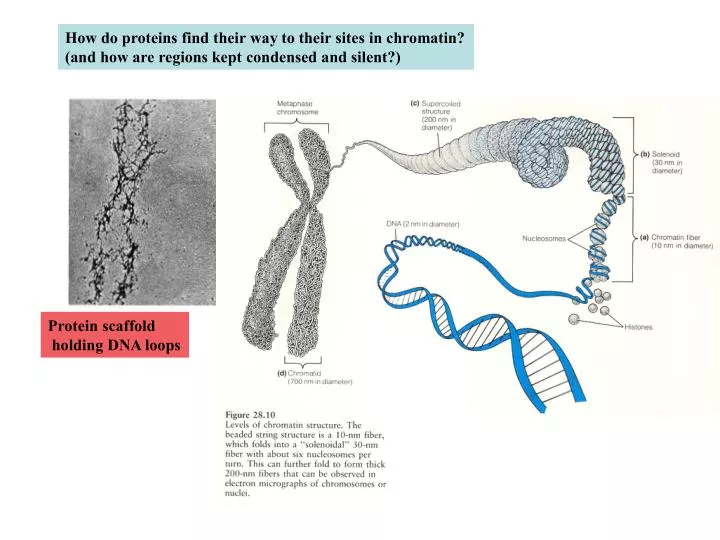
How do proteins find their way to their sites in chromatin? (and how are regions kept condensed and silent?). Protein scaffold holding DNA loops. Answer: there are chromatin-remodeling factors in cells. These make specific regions of chromatin accessible to the transcription machinery.

E N D
How do proteins find their way to their sites in chromatin? (and how are regions kept condensed and silent?) Protein scaffold holding DNA loops
Answer: there are chromatin-remodeling factors in cells These make specific regions of chromatin accessible to the transcription machinery
Among the activities are those that modify the histone tails of nucleosomes and contribute to the change of state in the surrounding chromatin Note that the although the core is compact and hidden, the tails are of “variable” structure and accessible. These can be modified to allow easier disruption of the chromatin,
lys can be acetylated by HATS by histone acetyl transferases lys can be methylated Histone modification influences chromatin accessibilty. Acetylation marks the chromatin for decondensation and activation. Methylation can reverse this.. Green flags and red lollipops indicate the location of acetyl and methyl histone modifications
The reversal requires acetylases Here is how a region of the genome can be silenced by silencing factors (SF) Silencig factor methylase A methylase initiates modification methylated nucleosome binds SF and more methylase It spreads to silence a region It is not known how the boundaries are set
De-condensation requires DNA-binding regulators as well as re-modeling enzymes. The slide shows a case where HAT and SWI/SNF work with a regulator to open up a region for transcription. (details not known).
The rest of the course is about the fate of the RNA made by transcription. How is it processed? How is it translated? Emphasis is on enzymology rather than description,
RNA processing - eukaryotic m-RNA capping of the 5’ end Polyadenylation at the 3’ end Splicing to remove introns stop AUG m7GpppN1 AAAAAAAA Poly(A) tail CAP Structure Introns removed
These processing factors work while transcription is proceeding. They cycle on (and off) via the polymerase CTD. Certain factors associate as the CTD is phosphorylated during initiation and clearance. As the RNA is elongated other factors associate. (details not yet clear).
Thus capping factors enter first; splicing and polyA factors enter later. These events are largely mediated by the changing state of the polymerase CTD The CTD consists of many repeats. The serines can be phosphorylated. The prolines can be isomerized (see next)
The enzyme pin1 can recognize certain prolines in the CTD and convert the peptide bond to the trans configuration.
Here’s what can happen to just one of the repeats. (there can by up to 52 of them) These events create chemical diversity and this changes as transcription and processing proceed.
Repeat of earlier slide - the CTD is changing as elongation proceeds. Certain factors associate as the CTD is phosphorylated during initiation and clearance. As the RNA is elongated other factors associate. (details not yet clear).
The 5’ Cap structure of eukaryotic mRNAs O CH3 + Unusual 5’ppp5’ linkage N7 H N1 CH2 O N9 O -O-P=O N3 N H2 O -O-P=O O OH OH -O-P=O O Base1 O 2HC +1 3’ 2’ Presence of methyl Groups at positions 1 and 2 is variable O-CH3 O Only this part comes from the primary transcript -O-P=O O Base2 O 2HC +2 3’ 2’ O-CH3 O -O-P=O
H2O Phosphorylase Pi ppN1pN2p... pppGOH Guanylyl Transferase (capping enzyme) PPi GpppN1pN2p... SAM Guanine 7-Methyl Transferase SAH 7meGpppN1pN2p... O-2’Methyl Transferase 7meGpppN1pN2p... O-CH3 O-CH3 pppN1pN2p... The 5’ capping reaction
Reminder that pol II is involved phosphorylase Capping enzyme methylases
How is the m-RNA 3’ end determined? Key point - the 3’ end is not a termination site. Instead the nascent RNA is cleaved while transcription proceeds. Then poly A is added. (termination occurs downstream). To the terminator AAUAAA (G/U) rich promoter Cleavage and polyA addition will occur here. This happens while polymerase is present in the region beyond these sites.
Factors assembling over the 3' end -CPSF= 4 subunits, recognizes the conserved hexamer AAUAAA (Cleavage and Polyadenylation Specificity Factor) CStF = - 3/4 subunits,recognizes the G/U rich element (Cleavage Stimulatory Factor) CFs = other required Cleavage Factors PAP = Poly(A) Polymerase = polymerizes poly (A) tail PABII = Poly(A) Binding Protein II - controls the length of The poly(A) tail (70nt in yeast, 200 in mammals) PAP CFs CPSF CStF AAUAAA AAUAAA (G/U) rich The processing occurs in 2 steps - next slides.
1) mRNA cleavage step PAP CFs CPSF CStF AAUAAA (G/U) rich Polymerase helped deliver these factors to the nascent RNA .but is not present at this DNA site.
Here is how polymerase II might deliver the processing enzymes. Note also that splicing has already started.
PABII 2) Poly(A) addition - the 2 enzymes add adenosines to the new 3’ end ATP CPSF PAP A A3’OH PPi A A A A AAUAAA A A A A A A A A A A A A A A A A A PABII binds the nascent poly(A) tail when the size is about 10nt. This provides processivity to poly(A) polymerase (70nt tail in yeast, 200 in mammals)
Structure of the Active site of Poly(A) polymerase 2 metals again Incoming ATP analogue
Reminder that the poly(A) tail is bound and later the m-RNA is exported and delivered to the ribosome by PAB (AAA)n PABI
Here’s a time-line view of an elongating polymerase Factors recruited via CTD Polymerase passes the 2 processing signals Cleavage occurs and both the RNA and the polymerase are released.
RNA splicing - history, mechanism and regulation Discovered simultaneously by 2 groups that found that mature m-RNA did fully match its gene. Northern and Southern blots showed that there were internal gene segments that could not hybridize to mature m-RNA. And electron microsopy of hybrids showed the same - See next slide.
These micrographs show a DNA:RNA hybrid with loops of DNA that do not match the RNA. So this gene was transcribed, but only the blue segments were in mature m-RNA. The rest were spliced out. intron exon
! An exon does not always correspond to a coding sequence. An intron does not always correspond to a non-coding sequence Definitions Exons = RNA segments joined together by splicing Intron = RNA segments that are removed from between 2 exons intron exon
A B A B Why are introns so prominent in eukaryotic genomes ? Exon shuffling? One gene is better than 2 ? With splicing one gene can make 3 proteins, including this new one. Recombination during evolution?
Another possible reason: acquisition of tolerance to attack by transposable elements. Transposition Mobile element “junk” Splicing would allow this to be removed, if it inactivated a gene. Of course the "junk" may include useful protein domains and this could be a further advantage.
Introns separate functional domain exons in TFIIIA, supporting exon shuffling ideas Intron7 Zn Zn Zn Zn Zn Zn Zn Zn Zn C N Intron8 intron2 intron4 intron1 intron6 intron5 intron3 Activation Domain 9 Zinc Fingers This suggests that useful exons were “shuffle in” during evolution
In the case of pyruvate kinase gene it is less clear. Some exons are structural units that may have been shuffled in But the C-terminus looks like function domains were broken up by random insertions