Download

1 / 34
340 likes | 441 Views
A Presentation of: “Programming A Paintable Computer” William Butera PhD Thesis, MIT 2002. Paintable Computing. all images (c) their respective owners. The Goal. Computing by the Liter. The Big Idea. The Superlative Multi-Processor Inverse of Current Architecture Paradigm

E N D
A Presentation of: “Programming A Paintable Computer” William Butera PhD Thesis, MIT 2002 Paintable Computing all images (c) their respective owners
The Goal • Computing by the Liter
The Big Idea • The Superlative Multi-Processor • Inverse of Current Architecture Paradigm • What are the hard problems? • Are they worse than what has already been solved?
Architecture Problems • Asynchronous devices • No easy way to make synchronous • Highly Unreliable Processors
Architecture Problems • No Global Communication • Unknown (and Unknowable) Topology
Architecture Problems • Code must be compact • Nodes cannot support large processes • Working sets must be small • Infinitely many paths to failure
The Solution • New Architecture => New Solution • Out with the old assumptions • Self Assembly • Better paradigm • Redefines “success”
Complex Adaptive Systems • Aggregate Behavior • simple parts => arbitrarily complex systems • Statistical Output • Local Interactions => Global State
Implementing a Solution • What sort of hardware is a good target? • Cannot be too small • Must be able to do useful work • Cannot be too large • Must be hard enough
Reference Standard “Paintable” Computer-- Processing -- • Really tiny “traditional” architecture • CPU: 10-200Mhz • RAM: 50K words • Bus: 16+ bit • Programmable in traditional languages • C, Java, etc
Reference Standard “Paintable” Computer-- Power -- • Unspecified interface • Does not impinge on the architecture • Examples • Batteries • Chemical substrate • Photo-cell • Structural power routing • Fuel Cells
Reference Standard “Paintable” Computer-- Networking -- • Directionless • Bandwidth: 100kbps Full Duplex • Radius: ~8 particles • Gaussian Random distribution of connectivity • Example Technologies: • luminescence • electrostatic • near-field RF
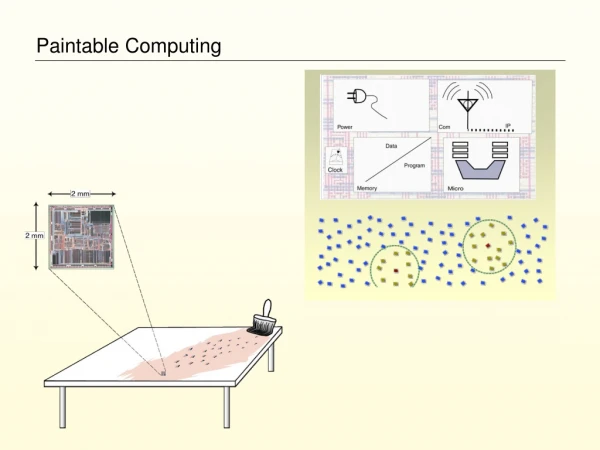
The Pushpin Computer • A real system • An example of a paintable computer • Model architecture • 330 nodes
System Layout • Separate communication, ground, and power • Planes separated by flexible silicon insulation
Programming Model • Program Fragments (PFrag's) • Computational Elements • Shared Memory Partitions • Inter Process Communication • Embedded OS • Local Resource Control • Special PFrag Services
Shared Memory Layout • PFrag I/O • Bassinet: Pre-Load Store • Launch Pad: Post-Unload Store • Data I/O • Home Page: Output to Neighbors • Mirrored Home Pages: Input From Neighbors • Organized as a key value pairs
OS Services 1 and 2 of 4 • Housekeeping • Defragmenting Memory • Resizing I/O Zone • Network Access • Inter Processor Communication • Manages Access I/O Regions • Manages Joins/Leaves • Mediates PFrag Access to I/O Regions
OS Services 3 and 4 of 4 • Running PFrags • Installs / Uninstalls the PFrag • Runs the PFrag • PFrag Services • Mathematics • Random Numbers • Access to Memory • Transit Request Messages • etc.
PFrag Implementation • Implements Five Functions • Install • Moves Self From Bassinet to Main Memory • DeInstall • Cleans Up and Erases Self • Update • Runs the process
PFrag Transit • Transfer-Granted • Cleans Up and Moves to Launch Pad for Transit • Transfer-Refused • Allows PFrag to Dequeue Transfer Request
Does It Work? • Need to prove Viability • Simple Applications that we can use to: • Test • Validate • Butera Implements • BreadCrumbs • Near Sighted Mailman • Knitting Club
What Is It Good For? • What software will Motivate? • Need a “Killer App” • Only works well on a Paintable Architecture • Butera Implements • Gradient • MultiGrad • Tessellation Operator • Diffusion • Channel Operator • Coordinate Operator
Can It Do What I Want It To? • Need to Prove Utility • Simple Applications that do something Useful • Traditional Service We Cannot Live Without • Butera Implements: • Streaming Audio • Holistic Data Storage • Surface Bus • Image Segmentation
Where do we go from here? • AMD and Intel • 2-4 on core processors • cannot go faster • go wider! • How far can we expand sideways? • A job for Architecture!
How Good Is It? • Can We Compare to Traditional? • Apples = Oranges? • Consider Two Cases • Serial Operation • Embarrassingly Parallel Operation
The Worst Case: Serial • Cannot “optimize away” all serial operations • Interactive Programs • Shells will work • low system requirements • low communication overhead • Will need a new device to do graphics • Build output into paintable? • Integrate a larger processor for graphics? • Can still do Mulitprocessing • Can make it massively fault tolerant
The Best Case: Parallel • Where is our overhead? • Getting the problem to the device • Getting the problem off the device • Sharing intermediates • The Computation Scales • with number of units • Cost is critical
How Does Cost Scale? • Butera's Die Assumptions: • Large Die = 100 mm2 • Medium Die = 25 mm2 • Small Die = 1 mm2 • Current Processor Dies • Pentium M = 84 mm2 • Pentium 4 = 131 mm2 • “Smithfield” Dual Core = 206 mm2 • Opteron Dual Core = 199 mm2
Peering Into the Process • Butera's Defect Rate Analysis • 200, 500, 1000 defects • Class 1 Cleanroom • 1 particle per ft3 • 30cm (diameter) wafers = 0.785 ft2 • 250 to 1270 ft of linear air motion • If process takes 5 days: • 2 to 10.5 ft per hour air motion • Assumptions are reasonable, even optimistic
How Does Cost Scale? • Butera's Calculations
Why is this relevant? • Yield Ratio is ~ 200 : 1 • As much as 20,000% greater yield
How Can This Help? • Consider a motivating problem • Embarrassingly Parallel • O(n2) computation • O(n) input • O(n) output • No inter-node communication • Only Need to Consider Problem Input/Output • O( n * log8(n) )