Download

1 / 18
300 likes | 769 Views
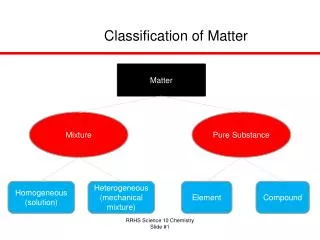
高斯混合模型 (Gaussian Mixture Model). 高斯分布. 其中 μ 為平均值 (Mean) , σ 為標準差 (Standard Deviation). 高斯混合模型. 利用高斯模型的 平均值描述特徵參數的分佈位置 , 共變異矩陣來描述分型形狀的變化 ,因此高斯混合模型可以很平滑的描述聲音的特徵分佈. 高斯混合模型 (10 個高斯成分 ) 表示圖. 高斯混合模型. 用一個高斯混合模型來表示一位語者. 高斯混合模型. 高斯混合密度為 M 個高斯密度的權重加總,其公式為 : 混合權重必須符合 之條件

E N D
高斯分布 其中μ為平均值 (Mean),σ為標準差(Standard Deviation)
高斯混合模型 利用高斯模型的平均值描述特徵參數的分佈位置,共變異矩陣來描述分型形狀的變化,因此高斯混合模型可以很平滑的描述聲音的特徵分佈 高斯混合模型(10個高斯成分)表示圖
高斯混合模型 • 用一個高斯混合模型來表示一位語者
高斯混合模型 • 高斯混合密度為M個高斯密度的權重加總,其公式為: • 混合權重必須符合 之條件 • 基本密度是D維的高斯函數 其中 為特徵向量, 為高斯機率密度值, wi 為混合權重值 其中 為平均向量, 為共變異矩陣,D為特徵向量的維度
D2 D1 Dtotal = D1 + D2
LBG演算法 • 計算整體平均向量 • 進行分裂: • 將分裂後的平均向量進行分類,並計算出新群集的平均向量
LBG演算法 • 計算平均向量與特徵參數的距離總和,使得總體距離和獲得最小,也就是當更新率小於δ時即停止 • 重複之前的步驟,直到分裂到所設定的數目 其中,D’為前一回合的總距離值
估算初始參數值 • 假設有12個特徵參數(音框),分群後的其中一個A群聚由特徵參數1 、 4、7和8四個特徵參數所組成,如下: • 混合權重值wi • 平均向量 特徵參數1 特徵參數4 特徵參數7 特徵參數8 4/12=0.3334
估算初始參數值 • 共變異矩陣
估算初始參數值 • 假設有三組特徵參數分別為 , 則 平均值為4 平均值為3
EM演算法 • 取得第i個混和的事後機率值
EM演算法 • 對各參數進行重新估算
EM演算法 • 進行最大相似估算 • 收斂條件 其中 收斂門檻
辨識 • 將每個樣本與待測的語音進行最大相似估算,機率值最大的,即為答案