Download

1 / 1
10 likes | 141 Views
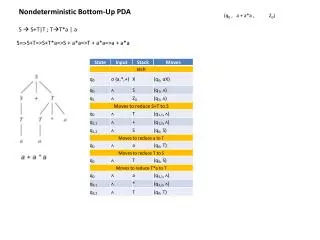
田浦研究室 Taura Laboratory. Big Computation, Big Data の世界を切り開こう!. MassiveThreads : 並列言語向け軽量スレッド. 超軽量なスレッド (80ns 未満でスレッドを作成・破棄 ) 通信ライブラリとの協調が容易 Pthread 互換の API I/O 待ちでブロックしたら 自動でスレッドを切り替え 分散環境への拡張 ノード間でスレッドを移動 させて動的負荷分散. 並列言語 Chapel に組み込んだ 例. 35 倍高速化 !. 次世代並列プログラミング言語を支える

E N D
田浦研究室 Taura Laboratory Big Computation, Big Dataの世界を切り開こう! MassiveThreads: 並列言語向け軽量スレッド • 超軽量なスレッド(80ns未満でスレッドを作成・破棄) • 通信ライブラリとの協調が容易 • Pthread互換のAPI • I/O待ちでブロックしたら • 自動でスレッドを切り替え • 分散環境への拡張 • ノード間でスレッドを移動 • させて動的負荷分散 並列言語Chapelに組み込んだ例 35倍高速化! 次世代並列プログラミング言語を支える 高性能な基盤ソフトウェア • メニーコアや分散環境では,タスクスケジューリングが実行効率に多大な影響を与える • 各コアがなるべく実行効率の高いタスクを処理できるようなタスクスケジューリング戦略(Depth-Aware Work Stealing) • 全ノードの状態が一目でわかる • CPU使用率 • ネットワーク送受信量 • あるノードのプロセス一覧 • 特定のユーザのプロセスだけ 表示 • 非常に軽量に動作 • 密行列積で8-15%の性能向上 • 並列アプリケーションの性能を比較により解析 • 1500タスク以上のアプリケーションでも性能差の原因部分を特定 • 解析方法はユーザが自由に設定可能 リアルタイムなシステム監視が可能 VGXP: リアルタイムモニタリングシステム PARP: 並列アプリケーションのプロファイル比較 高並列環境のタスクスケジューラ ParaLite: 並列データベース InTrigger- 広域分散クラスタ • [ユーザ視点] • 並列シェルを使って、多数のノードに対するコマンドの一括実行 • [管理者視点] • 自動的にクラスタ間でユーザアカウントを共有 • リアルタイムなシステム監視 • 全国17拠点 • 391ノード • 2268CPU 今年は軽井沢に研究室合宿に行ったりもしました!意欲のある学生皆様の参加を歓迎します^^わたしたちと一緒に充実した一年を過ごしましょう! GXPmake: 分散並列ワークフロー実行系 • 通常のMakefileを記述するだけで、依存関係を持つジョブを分散環境で並列実行 • アプリケーション例 • 自然言語処理、画像処理、レンダリングなど • 1CPUで120日要する大規模文書解析処理を8時間で完了 • 分散環境でのデータマネジメント • アプリケーションの特徴、使う分散環境に合わせてデータ移動を最適化 • 分散ファイルシステムという形で提供 ユーザにとって使いやすく、管理もしやすいクラスタ 2011年度の卒論テーマ例 卒業論文のテーマは、本人の興味のある分野に関連したものを、相談しながら決めます 「再帰的に生成したタスクに対するデータ局所性を考慮するスケジューラの実装と評価」 プログラマがたくさん並列単位=タスクを作れる、”タスク並列”というパラダイムが最近有望です。プログラムの性能をできる限り高めるタスクの実行順序を研究しています。 「クラスタのエネルギー消費を抑えるための資源電源管理」 並列計算クラスタを構成するノードには複雑な関係性があるため、この関係を考慮して適切なノードの電源を切ることが重要です。そのための最適なアプローチを研究しています。 「PGAS処理系におけるGCとリージョンによるメモリ管理」 並列分散プログラミング処理系の1つであるPGAS処理系上で、GCを効率よく行う方法を研究しています。 「汎用的自動パラメタチューニングシステムの設計」 アプリケーションのチューニングは計算機の性能を十分に発揮するためには不可欠ですが、最適化は難しい問題で時間もかかる作業ですので、これを自動化することを目指しています。 「Superword Level Parallelismを用いた再帰的アルゴリズムの自動ベクトル化の支援」 再帰的アルゴリズムのコードに対して適切なコード変換を行うことで、SLPを用いたベクトル化を適用可能にし、計算をSIMD命令(SSE等)で高速化する研究をしています。 「データ集約処理における再帰分割を用いた通信の最適化」 データ集約処理では、TBやPBを超えるデータを扱います。プロセスを再帰分割することで並列性の高い集合通信を行う最適化手法を研究しています。 • SQLが持つ高水準なデータ処理と、既存のプログラムを容易に統合 • “Collective Query”の提案 • 複数のクライアントで実行でき、結果もまた複数のクライアントが受け取るクエリ • 任意のコマンドラインを含められるようなSQL構文の拡張(UDX) - Hadoopより高速なクエリ処理 - UDXの活用により良いスケーラビリティを達成 ◆田浦研HP → http://www.eidos.ic.i.u-tokyo.ac.jp









![[ t-t-t ]](https://cdn1.slideserve.com/3099327/slide1-dt.jpg)