Download

1 / 19
190 likes | 382 Views
character recognition based on probability tree model. Presenter: Huang Kaizhu. Outline. Introduction How probability can be used in character recognition? What is probability tree model? Two improvement direction Integrate Prior knowledge Relax the tree structure into a hyper tree

E N D
character recognition based onprobability tree model Presenter: Huang Kaizhu
Outline • Introduction • How probability can be used in character recognition? • What is probability tree model? • Two improvement direction • Integrate Prior knowledge • Relax the tree structure into a hyper tree • Experiments in character recognition
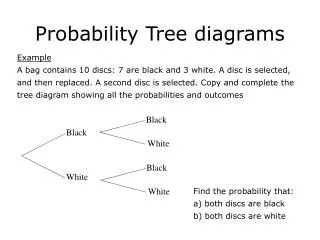
Disease Diagnosis problem • How a doctor get to know a patient have a cold? • A. The patient has a headache? • B. The patient has a sore throat? • C. The patient has a fever? • D. The patient can breathe well via his nose? • Now a patient has the following symtoms. A is no, B is yes, C is no, D is yes • What is the hidden principle of the doctor in making a judgment?
Disease Diagnosis problem(cont) • A good doctor will get his answer by checking: P1= P(Cold=true,A=N, B=Y,C=N,D=Y) Vs P2= P(Cold=false,A=N, B=Y,C=N,D=Y) if P1>P2, the patient is judged to have a cold if P2>P1, the patient is judged to have no cold
What is Probability Model Classifier? • A Probability model classifier is a kind of classifier based on the probability inductions. The focus is now changed into how to calculate: P(Cold=true,A=N, B=Y,C=N,D=Y) and P(Cold=false,A=N, B=Y,C=N,D=Y) Now a classification Problem is change into a distribution estimation problem
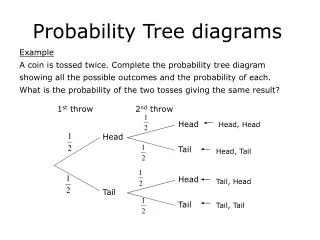
Used in character recognition • How can the probability model used in character recognition? • (similar to the Disease Diagnosis Problem) • Find a probability distribution of the features for every type of character. P(‘a’, f1,f2,f3,…,fn), P(‘b’,f1,f2,f3,…,fn),…, P(‘z’,f1,f2,f3,…,fn) • Compute in what probability a unknown character belongs to each type of character. And classify this character into the class with the highest probability. For example: P(‘a’,fu1, fu2 ,… ,fun, )> P(C,fu1, fu2 ,… ,fun, ) , C=‘b’,’c’,…’z’ We judge the unknown character into ‘a’ How can we estimate the joint Probability P(C, f1,f2,f3,…,fn)? C=‘a’,’b’…,’z’
Estimate the joint Probability • 1. Estimation based on direct counting P(Cold=true,A=N, B=Y,C=N,D=Y) =Num(Cold=true,A=N, B=Y,C=N,D=Y)/TotalNum; Impractical!! Reasons: Huge samples needed. if the num of features is n ,at least 2n samples are needed for binary features.. • 2. Estimation based on Dependence relationship between features
Advantage • Joint Probability can be written into a product form. P(A,B,C,D) =P(C)P(A|C)P(D|C)P(B|C) • BY estimating each item of the above according to counting process,We can avoid the sample exploration problem Probability tree model is a kind of model based on the above principle
Probability tree model • It assume that dependence relationship among features can be represented as a tree. • It seeks to find out a tree structure to represent the dependence relationship optimally and the probability can be written into:
Algorithm 1.Obtaining P(vi ) and P(vi,vj) for each pair of (vi,vj) by accumulating process . Vi is the feature 2.Calculating the mutual entropy 3.Utilizing Maximum spanning tree algorithm to find the optimal tree structure,which the edge weight between two nodes vi,vj is I((vi,vj) This algorithm was proved to be optimal in [1]
Two problems of tree model • Can’t process sparse data or missing data For example, if the samples are too sparse, maybe nose problem never happens in all the records of the patients with cold and nose problem happens 2 times in all the records of the patients without cold Thus no matter what symptom a patient has, a “cold=FALSE” judgment will be made since the P(cold=true,A,B,C,D =FALSE)= P( cold=true,D=false|C)*…=0 < P(cold=false,A,B,C,D =FALSE); • Can’t perform well in multi-dependence relationship
2 Our improvements • To problem1: Introduce prior knowledge to overcome it • So the example in last slide:
Key point of Technique 1 • When a variable(feature) are always the same in one class, we replace its probability with a proportion of the variable probability in the whole database
To Problem2: Introduce Large Node methods to overcome it CLT LNCLT
Algorithm • 1. Find out the tree model • 2.Refine the tree model based on frequent itemset Basic idea: if two variable come out together with each other more frequently, more possible it will be combined into a large node
Experiments1---Handwritten digit Lib Database setup: • 60000-digit training lib ,10000-digit test lib • Database is not sparse Purpose: evaluate the technique to problem 2 The digits recognized correctly by LNCLT are wrongly recognized into the right-bottom digits by CLT
Experiments1---Printed character Lib Database setup: • 8270 training lib , • Database is sparse Purpose To evaluate the technique to Problem 1:sparse data Before introducing Prior knowledge: Recognition rate of training data: 86.9% After introducing Prior knowledge: Recognition rate of training data: 97.7%