Download
1 / 10
150 likes | 543 Views
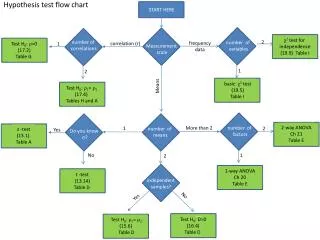
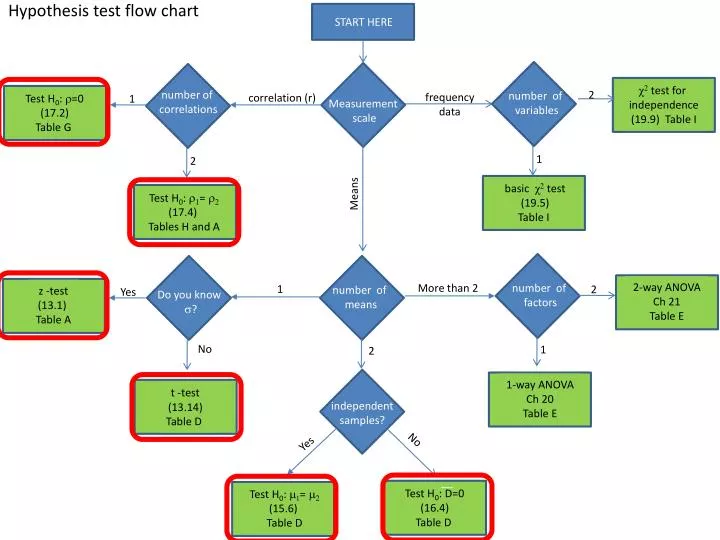
Hypothesis test flow chart. χ 2 test for i ndependence (19.9) Table I. Test H 0 : r =0 (17.2) Table G . n umber of correlations. n umber of variables. f requency data. c orrelation (r). 1. 2. Measurement scale. 1. 2. b asic χ 2 test (19.5) Table I .

E N D
Hypothesis test flow chart χ2 test for independence (19.9) Table I Test H0: r=0 (17.2) Table G number of correlations number of variables frequency data correlation (r) 1 2 Measurement scale 1 2 basic χ2 test (19.5) Table I Test H0: r1= r2 (17.4) Tables H and A START HERE Means 2-way ANOVA Ch 21 Table E z -test (13.1) Table A More than 2 1 2 number of means Yes Do you know s? number of factors No 2 1 t -test (13.14) Table D 1-way ANOVA Ch 20 Table E independent samples? Yes No Test H0: m1= m2 (15.6) Table D Test H0: D=0 (16.4) Table D
Chapter 16: Inference about Correlation Coefficients We will make inferences about population correlations in two ways: To test if a population has a correlation different from zero. To test if two correlations are different from each other. We use the letter ‘r’ for sample correlations. We use the Greek symbol r (rho) for population correlations.
1) Testing the null hypothesis that a single correlation is equal to zero. The sampling distribution for r is very complicated and can be strongly skewed. However, for testing whether a sample is being drawn from a population with zero correlation, Ronald Fisher figured out an easy way to convert a sample correlation from r to t, so we can run a standard t-test: Using df = n-2, where n is the number of pairs in the correlation. The book makes it even easier by giving us Table G which provides critical values of r for values of a and df. We don’t have to convert from r to t, just look up the critical value for r in table G. I’ve provided a version of Table G and its corresponding calculator in Excel for you.
Example: We found that the heights of the 75 women in our class correlates with the heights of their mothers with a value of r= 0.35. If we consider this a random sample of the population, does this suggest that there is a positive correlation between the heights of women and their mothers? (use a value of a = .01) Answer: We will be testing the null hypothesis using a one-tailed test: H0: r = 0 HA: r > 0 All we have to do is look up the critical value for r for df = 75-2 = 73 and a = .01 for a one-tailed test in table G: Our critical value of r is 0.268. Our observed value of r (.35) is greater than this critical value (.268), so we Reject H0and conclude that there is a very low probability of observing this high of a correlation by chance if the null hypothesis was true. If we assume that the women in this class were randomly sampled from the general population then we conclude that a significant correlation exists in the population.
Example: The hours of video games played by the 94 students in this class correlates with current GPA with a value of -.1044. Using an a value of .05, is this significantly different from zero? Answer: We will be testing the null hypothesis using a two-tailed test: H0: r = 0 HA: r ≠0 All we have to do is look up the critical value for r for df = 94-2 = 92 and a = .05 for a two-tailed test in table G. Our critical value of r is ±0.203. So we fail to reject Ho (*whew*) Using APA format: There is not a significant correlation between GPA and video game playing, r(92) = -.1044, p<.05.
Example (from the tutorial) 2) Let's pretend that you sample 17 light pants from a population and measure both their cost and their jewelry. You calculate that their cost correlates with jewelry with r = -0.83. Using an alpha value of α = 0.01, is this observed correlation significantly different than zero? Answer: robs = -0.83tobs = -5.7633tcrit = ± 2.95 (df = 15)or rcrit = ± 0.61We reject H0.The correlation between cost and jewelry for light pants is significantly different than zero, r(15) = -0.83, p < 0.0001.
2) Testing the null hypothesis that two independently sampled correlations are the same. The sampling distribution of correlations becomes more and more skewed when the correlation of the population gets closer to 1 or -1. So comparing whether two correlations are different requires a more complicated conversion. Comparing two correlation values is done by first converting from r to Fisher’s z’ (z-prime) and then conducting a z-test where The book provides Table H for converting from sample correlations r to z’ so you don’t have to use the formula. I’ve provided a version of table H along with a calculator in excel which you can download.
Example: The heights of the 75 women in our class correlates with the heights of their mothers with a value of r= 0.35, and the correlation between the 21 men and their father’s heights is 0.61. If we assume that these students are randomly sampled from the general population, can we conclude that correlations of heights between men and their fathers is different than the correlation of heights between women and their mothers? Use a = 0.05 Answer: Let r1 = 0.61, n1 = 21, r2 = 0.35 and n2 = 75. and let H0: r1= r2 and HA: r1≠r2 Step 1: Convert the correlations to z’. Looking these values up in table H we find: z1 = 0.7082 and z2 = 0.3654 Step 2: Calculate z from the equations:
Step 3: find the critical values for z. We’re conducting a two-tailed test with a = .05. We want to find the value of z for which each tail contains a proportion of 0.025. Looking this up in table A, column C gives: zcrit = ±1.96 Our value of z=falls outside the rejection region, so we fail to reject H0. Using APA format: “There is not a statistically significant difference between the correlation between women and their mothers (r = .61) and men and their fathers (r = . 35), z = 1.303, p<.05”
What does the probability distribution of correlations look like?