Download

1 / 27
270 likes | 389 Views
csda. csda. Rethinking Custom ISE Identification: A New Processor-Agnostic Method. Ajay K. Verma, Philip Brisk and Paolo Ienne Processor Architecture Laboratory (LAP) & Centre for Advanced Digital Systems (CSDA) Ecole Polytechnique Fédérale de Lausanne (EPFL). Custom ISE Identification.

E N D
csda csda Rethinking Custom ISE Identification: A New Processor-Agnostic Method Ajay K. Verma, Philip Brisk and Paolo Ienne Processor Architecture Laboratory (LAP) & Centre for Advanced Digital Systems (CSDA) Ecole Polytechnique Fédérale de Lausanne (EPFL)
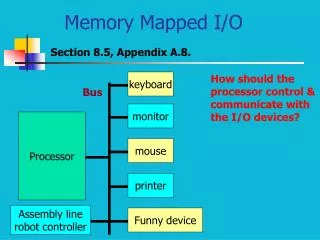
Custom ISE Identification Register File AFU ALU MUL LD/ST out1 = F (in1, in2, in3, in4) out2 = G (in1, in2, in3, in4) Data Memory Limited number of I/O ports
Outline • Related work • Problem formulation • ISE selection • I/O serialisation • Underlying assumptions and justifications • Main idea • How to generate a sparse set of potential ISEs • Effective I/O serialisation heuristic • Results • Conclusions
Related Work • ISE identification under I/O constraints • Search space pruning using I/O and convexity constraints [Atasu03, Clark03, Yu04, Pozzi06, Yu07, Chen07] • ILP based approach [Atasu05] • Polynomial time algorithm [Bonzini07] • ISE identification under relaxed I/O constraints • Restricted search space exploration [Pozzi05] • Generation of a semi compact set of connected ISEs [Pothineni07] • I/O serialisation • Exponential time algorithms[Pozzi05, Pothineni07]
Our Contributions (1 of 2) ISE Selection I/O Serialisation Atasu03 Pozzi05 Chen07 Pothineni07 Bonzini07 Yu07 Our I/O serialisation algorithm (faster, optimal/heuristic) Our ISE selection algorithm (optimal, faster, single run)
Our Contributions (2 of 2) a a 0.5, 1.0 0.6, 1.0 0.4, 1.0 0.8, 1.0 b c b c 0.3, 1.0 0.7, 1.0 0.3, 1.0 0.3, 1.0 d d e e 0.7, 1.0 0.5, 1.0 f f 0.5, 1.0 0.2, 1.0 No need to redo the ISE selection process, the optimal ISE is bound to be in the generated sparse set of ISE candidates
a x1 d b c e x3 g f h x2 Problem Formulation • Given • a dataflow graph • a set of forbidden nodes • Find a subgraph S, which is • convex • free of forbidden nodes • And, has largest gain M (S) = Nexec * (SW (S) – HW (S))
a x1 d b c e x3 g f h x2 ISE Merit Estimation c b d e f M (S) = Nexec * (SW (S) – HW (S))
Assumption about Merit Function Monotonicity:If a valid subgraph is contained in another valid subgraph, then the ISE corresponding to the bigger subgraph is always beneficial The assumption holds for typical single-issue RISC processor
Only Maximal ISEs Should Be Considered a a b bc x x c d d {abc, bcd}
a b x c d Criteria for Clustering Nodes • For two nodes u and v, if any valid subgraph containing one of the two can be extended to a valid subgraph containing both, then the two nodes can be clustered together S (u) T (uv) M (S) ≤ M (T) This criteria is too expensive to check {ab} {abc} {b} {bc}
Polynomial Time Algorithm for Clustering • Consistent set of a node u: • P (u) = {x | there exist a valid subgraph containing both u and x} x u x u S = {u, x} u and x do not have a predecessor successor relationship u is a successor of x, or vice versa Theorem: Two nodes can be clustered iff they have the same consistent set
a x1 d b c e x3 g f h x2 Example P (a) = {a, g} P (b) = {b, c, d, e, f, g} P (c) = {b, c, d, e, f, g} P (d) = {b, c, d, e, f, g} P (e) = {b, c, d, e, f, g} P (f) = {b, c, d, e, f, g, h} P (g) = {a, b, c, d, e, f, g, h} P (h) = {f, g, h}
Significant Size Reduction via Clustering Benchmark: aes All possible grouping of clusters can still be infeasible
a bcde h f g Cluster Graph • Cluster graph of a DAG is an undirected graph whose • nodes correspond to clusters of DAG, • nodes corresponding to clusters C1 and C2 are connected by an edge, if no path between the nodes of C1 and C2 contains a forbidden node in the original DAG a x1 d x3 b c e g x2 f h
a bcde h f g Maximal Cliques of Cluster Graph Theorem: There is a one to one correspondence between maximal cliques of the cluster graph and maximal ISEs {ag, fgh, bcdefg} Unless we have further knowledge about processor-model, the set of potential ISEs cannot be reduced any further
Second Contribution: I/O Serialisation ISE Selection I/O Serialisation Atasu03 Pozzi05 Chen07 Pothineni07 Bonzini07 Yu07 Our I/O serialisation algorithm (faster, optimal/heuristic) Our ISE selection algorithm (optimal, faster, single run)
a x1 d b c e x3 g f h x2 Register-File Access Serialisation c b d e g f
a x1 d b c e x3 g f h x2 Access Order of Inputs • Theorem: If the order in which inputs (outputs) are accessed (produced) is known, then the subgraph can be pipelined optimally in polynomial time g Access order of inputs: (g, bc, d) c b d e f
Reduction into A Matrix Problem • Problem: Given an m x n integer matrix A, an m-dimensional integer array R, and an n-dimensional integer array C, find the permutations ξ and Φ, such that the following expression is minimum maxi, j (Rξ (i) + aij + CΦ (j)) C A R
Ping-Pong: Heuristic for Matrix Problem Ping-Pong (A, R, C) { Pick a random permutation ξ; do { find the best Φ for current ξ; find the best ξ for current Φ; } while (change) output ξ and Φ; }
Example c c b b g g d c b e g d d e e f f f
Experimental Setup Input dataflow graph exp / subopt exp / opt ISE selection Atasu03 ISE selection Atasu03 ISE selection Our algorithm poly / subopt exp / opt No serialisation I/O serialisation Pozzi05 I/O serialisation Our algorithm
Results (1 of 3) Benchmark:aes Biggest dataflow graph:703 Our algorithm takes only 30 seconds compared to several hours taken by Pozzi’s algorithm
Results (2 of 3) The best AFU with 22 inputs and 22 outputs
Results (3 of 3) adpcmcoder adpcmdecoder viterbi
Conclusions ISE Selection I/O Serialisation Atasu03 Pozzi05 Chen07 Pothineni07 Bonzini07 Yu07 Our I/O serialisation algorithm (faster, optimal/heuristic) Our ISE selection algorithm (optimal, faster, single run) Processor-agnostic under some general assumptions