Download

1 / 35
360 likes | 383 Views
Discover how text mining enhances web user profiling, document categorization, authorship detection, and more. Explore the methods and potential of data mining in web analytics and information filtering.

E N D
Text-Mining: analysis of text data Dunja Mladenić J.Stefan Institute, Ljubljana, Slovenia and Carnegie Mellon University, USA http://www-ai.ijs.si/DunjaMladenic/ http://www.cs.cmu.edu/~dunja/
Web user profiling • imagine the user browsing the Web, most of the time by clicking hyperlinks • goal: provide help by highlighting the clicked hyperlinks (we assume that the user is clicking on interesting hyperlinks) • induce a profile for each user separately • the profile can be used to predict clicking on hyperlinks (in our case), to collect interesting Web-pages, to compare different users and share knowledge between them (collaborative agents)
Structure of the personal browsing assistant - Personal WebWatcher URL URL proxy (adviser) page User The Web User profile modified page Personal WebWatcher
Personal WebWatcher in action (1996) Highlight interesting hyperlinks
Data Pyramid Wisdom Knowledge plus experience Knowledge Information plus rules Information Data plus context Data
What is Data Mining? • Data mining (knowledge discovery in databases - KDD, business intelligence): • finding interesting (non-trivial, hidden, previously unknown and potentially useful)regularities in large datasets • “Say something interesting about the data.” • “Decribe this data.”
Data Mining: Potential usage • Market analysis • Risk analysis • Fraud detection • Text Mining • Web Mining • ...
Why text analysis? • The amount of text data on electronic media is growing daily • e-mail, business documents, the Web, organized databases of documents,... • There is a lot of information contained in the text • Available methods and approaches enabling solving interesting and non-trivial problems
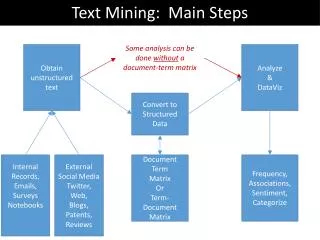
Problem description (I) • Text information filtering • Help with browsing the Web • Generation and analysis of user profiles • Automatic document categorization and keyword assignment to documents • Document clustering • Document visualization • Document authorship detection • Document copying identification • Language identification in text
Document categorization Document Classifier labeled documents ??? document category (label) unlabeled document
Automatic document categorization • Problem: given is a set of content categories filled with documents. • The goal is: to automatically insert a new document (assign one or more relevant categories to a new document). • Content categories can be structured (eg., Yahoo, Medline) or unstructured (eg., Reuters) • The problem is similar to assigning keywords to documents
Document to categorize: CFP for CoNLL-2000
Some predicted categories
Our approach to document categorization • Data is obtained from the existing collection of manually categorized documents, where the used content categories are structured • Using Text Mining methods, we constructed a model that captures manual work of editors • The model is used to automatically assign content categories and the corresponding keywords to new, previously unseen documents
System architecture Feature construction Web vectors of n-grams Subproblem definition Feature selection Classifier construction labeled documents (from Yahoo! hierarchy) ?? Document Classifier unlabeled document document category (label)
Summary of experiments and results • learning from categorization hierarchy: considering only promising categories during the classification (5%-15% of categories) • extended document representation: new features for sequences of two words • feature subset selection: Odds ratio using 50-100 best features (0.2%-5%)
More can be found at our project page www.cs.cmu.edu/ ~TextLearning/ pww/yplanet.html
Document authorship detection • Problem: based on a database of documents and authors, assign the most probable author to a new document • Solution is based on the fact that each author uses a characteristic frequency distribution over words and phrases
Document copying identification • Problem: predict probability that a given document was copied (partially or completely) from some other document(s) from our database • Algorithm uses complex indexing methods on (different length) parts of documents and compares them against the given document
Natural language identification • Text data analysis systems commonly use some natural language dependent methods • Need for identification of natural language the document is written in • Problem: for a given text identify the natural language it is written in selecting among the predefined languages
Algorithm for natural language identification • Basic algorithms are simple: for each language build a characteristic frequency table of pairs and triples of letters that can be simply used to identify a document language (TextCat publicly available system, covers 60 languages) • Problem is with short documents - in this case we can use mechanisms for language dependent stop-words detection (stop-words are frequent in all languages)
Problem description (II) • Topic identification and tracking in time series of documents • Document indexing based on content and not only keywords • Content segmentation of text • Document summarization • Link analysis • Information extraction
Topic identification and tracking in time series of documents • Problem: given is a time-sequence of documents (news) - based on this document sequence we want to: • identify document that introduces new topic • from the sequence of new documents identify documents about existing topics and connect them into a topic sequence
Text segmentation based on content • Problem: divide text that has no given structure (content table, paragraphs, etc.) into segments with similar content • Example applications: • topic tracking in news (spoken news) • identification of topics in large, unstructured text databases
Algorithm for text segmentation • Algorithm: • Divide text into sentences • Represent each sentence with words and phrases it contains • Calculate similarity between the pairs of sentences • Find a segmentation (sequence of delimiters), so that the similarity between the sentences inside the same segment is maximized and minimized between the segments
Text Summarization • Task: Given a text document create a summary reflecting the document’s contents • Three main phases: • Analyzing the source text • Determining its important points • Synthesizing an appropriate output • Most methods adopt linear weighting model – each text unit (sentence) is assessed by: • Weight(U)=LocationInText(U)+CuePhrase(U)+Statistics(U)+AdditionalPresence(U) • …output consists from topmost text units (sentences)
Information extraction • Collect a set of Home pages from the Web and build a “soft” database of people (name, address, coworkers, research areas and publications, biography...) • Collect electronic seminar announcements and extract location (room number), start and end time, name of the speaker
Where are we now? • Growing interest and need for handling large collections of text • The area is present in Slovenia for over 5 years with strong international connection • joint R&D project with: Microsoft Research, European and American research institutions, cooperation with Boeing • Organization of international events focused on Text Mining (ICML-99, KDD-2000, ICDM-2001)
Instead of conclusions... • Text Mining enables solving some problems that are often not expected to be addressed by computers: • document authorship detection, identification of related content or finding “interesting” people, document segmentation and organization, automatic collection of officer names for the selected sector companies, finding experts in some area, who is involved with whom (discovering social networks), ...
To find more information check: <http://www-personal.umich.edu/~wfan/text_mining.html> <http://ai.about.com/library/weekly/aa102899.htm> <http://extractor.iit.nrc.ca/bibliographies/ml-applied-to-ir.html> <http://www.content-analysis.de/> get research papers at <http://www.researchindex.com> • KDD-2000 Text Mining Workshop <http://www.cs.cmu.edu/~dunja/WshKDD2000.html> • ECAI-2000 ML for Information Extraction <http://www.dcs.shef.ac.uk/~fabio/ecai-workshop.html> • PRICAI-2000Text and Web MiningWorkshop <http://textmining.krdl.org.sg/cfp.html> • IJCAI-2001 Adaptive Text Extraction and Mining Workshop <http://www.smi.ucd.ie/ATEM2001/>, Text Learning: Beyond Supervision <http://www.cs.cmu.edu/~mccallum/textbeyond/> • ICDM-2001 Text Mining Workshop <http://www-ai.ijs.si/DunjaMladenic/TextDM01/> • ECML/PKDD-2001 Text Mining tutorial <http://www-ai.ijs.si/DunjaMladenic/TextDM01/Tutorial.ps>
Link Analysis • Mechanisms for detecting which vertices in the graph (pages on the web) are more important on the basis of link structure: • Hits algorithm (Hubs & Authorities) (Kleinberg 1998) • PageRank (Page 1999) weighting (used by Google to better rank good pages)
Link analysis on Amazon data • We downloaded product pages from Amazon.com web site: • …products are connected with cross-sell relation (“customers who bought this product also bought following products…”) • 130.000 books and 32.000 music CDs connected into graph • Question: which products (books or CDs) are the most important? • …we used Hits algorithm to calculate the weights • Harry Potter & Beatles won the test.
Popular books • Harry Potter and the Goblet of Fire (Book 4): J K Rowling, Mary Grandpre • The Beatles Anthology: The Beatles, Paul McCartney, George Harrison, Ringo Starr, Lennon, John Lennon • Prodigal Summer: Barbara Kingsolver • Harry Potter and the Sorcerer's Stone (Book 1): J K Rowling • The Mark : The Beast Rules the World (Left Behind #8): Tim LaHaye, Jerry B Jenkins • Harry Potter and the Chamber of Secrets (Book 2): J K Rowling • Harry Potter and the Prisoner of Azkaban (Book 3): J K Rowling, Mary Grandpre • The Sibley Guide to Birds (Audubon Society Nature Guides Ser.): David Allen Sibley • ....
Popular CDs • The Beatles • A Day Without Rain: Enya • Lovers Rock: Sade • All That You Can't Leave Behind: U2 • Riding With The King: Eric Clapton, BB King • Black and Blue: Backstreet Boys • Sailing To Philadelphia: Mark Knopfler • You're The One: Paul Simon • Kid A: Radiohead • Music: Madonna • Red Dirt Girl: Emmylou Harris • Renee Fleming • ...