Download

1 / 16
250 likes | 587 Views
Inverted Files . Ch-3 Frakes and Yates. Contents. Introduction STRUCTURES USED IN INVERTED FILES The Sorted Array B-trees BUILDING AN INVERTED FILE USING A SORTED ARRAY Producing an Inverted File for Large Data Sets without Sorting. 1. Introduction.

E N D
Inverted Files Ch-3 Frakes and Yates
Contents • Introduction • STRUCTURES USED IN INVERTED FILES • The Sorted Array • B-trees • BUILDING AN INVERTED FILE USING A SORTED ARRAY • Producing an Inverted File for Large Data Sets without Sorting
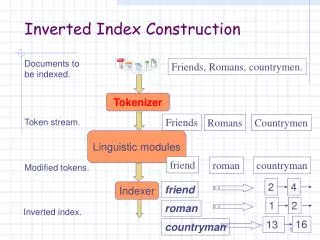
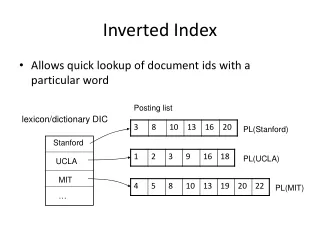
1. Introduction • The concept of the inverted file type of index is as follows. Assume a set of documents. Each document is assigned a list of keywords or attributes, with optional relevance weights associated with each keyword (attribute). An inverted file is then the sorted list (or index) of keywords (attributes), with each keyword having links to the documents containing that keyword (see Figure 3.1) . • This is the kind of index found in most commercial library systems. The use of an inverted file improves search efficiency by several orders of magnitude, a necessity for very large text files. The penalty paid for this efficiency is the need to store a data structure that ranges from 10 percent to 100 percent or more of the size of the text itself, and a need to update that index as the data set changes.
Contd.. Usually there are some restrictions imposed on these indices and consequently on later searches. Examples of these restrictions are: • a controlled vocabulary which is the collection of keywords that will be indexed. Words in the text that are not in the vocabulary will not be indexed, and hence are not searchable. • a list of stopwords (articles, prepositions, etc.) that for reasons of volume or precision and recall will not be included in the index, and hence are not searchable. • a set of rules that decide the beginning of a word or a piece of text that is indexable. These rules deal with the treatment of spaces, punctuation marks, or some standard prefixes, and may have signficant impact on what terms are indexed. • a list of character sequences to be indexed (or not indexed). In large text databases, not all character sequences are indexed; for example, character sequences consisting of all numerics are often not indexed.
2. STRUCTURES USED IN INVERTED FILES • There are several structures that can be used in implementing inverted files: sorted arrays, B-trees, tries, and various hashing structures, or combinations of these structures. The first three of these structures are sorted (lexicographically) indices, and can efficiently support range queries, such as all documents having keywords that start with "comput."
3. The Sorted Array • An inverted file implemented as a sorted array structure stores the list of keywords in a sorted array, including the number of documents associated with each keyword and a link to the documents containing that keyword. This array is commonly searched using a standard binary search, although large secondary-storage-based systems will often adapt the array (and its search) to the characteristics of their secondary storage. The main disadvantage of this approach is that updating the index (for example appending a new keyword) is expensive. On the other hand, sorted arrays are easy to implement and are reasonably fast.
4. B-trees • Another implementation structure for an inverted file is a B-tree. More details of B-trees can be found in Chapter 2, and also in a recent paper (Cutting and Pedersen 1990) on efficient inverted files for dynamic data (data that is heavily updated). A special case of the B-tree, the prefix B-tree, uses prefixes of words as primary keys in a B-tree index (Bayer and Unterauer 1977) and is particularly suitable for storage of textual indices. Each internal node has a variable number of keys. Each key is the shortest word (in length) that distinguishes the keys stored in the next level. The key does not need to be a prefix of an actual term in the index. The last level or leaf level stores the keywords themselves, along with their associated data (see Figure 3.2)
Contd.. • Because the internal node keys and their lengths depend on the set of keywords, the order (size) of each node of the prefix B-tree is variable. Updates are done similarly to those for a B-tree to maintain a balanced tree. The prefix B-tree method breaks down if there are many words with the same (long) prefix. In this case, common prefixes should be further divided to avoid wasting space.
5. BUILDING AN INVERTED FILE USING A SORTED ARRAY • The production of sorted array inverted files can be divided into two or three sequential steps as shown in Figure 3.3. First, the input text must be parsed into a list of words along with their location in the text. This is usually the most time consuming and storage consuming operation in indexing. Second, this list must then be inverted, from a list of terms in location order to a list of terms ordered for use in searching (sorted into alphabetical order, with a list of all locations attached to each term). An optional third step is the postprocessing of these inverted files, such as for adding term weights, or for reorganizing or compressing the files. See Fig.3.3.
6. Producing an Inverted File for Large Data Sets without Sorting • Indexing large data sets using the basic inverted file method presents several problems. Most computers cannot sort the very large disk files needed to hold the initial word list within a reasonable time frame, and do not have the amount of storage necessary to hold a sorted and unsorted version of that word list, plus the intermediate files involved in the internal sort. Whereas the data set could be broken into smaller pieces for processing, and the resulting files properly merged, the following technique may be considerably faster. For small data sets, this technique carries a significant overhead and therefore should not be used.
Contd.. • The new indexing method (Harman and Candela 1990) is a two-step process that does not need the middle sorting step. The first step produces the initial inverted file, and the second step adds the term weights to that file and reorganizes the file for maximum efficiency (see Figure 3.6).
Contd.. Thank You