Download

1 / 38
380 likes | 513 Views
Experimenting with machine vision and Zynq M. Viti 1 , E. Primo 2 , C. Salati 2. 1 Datalogic Automation Srl 2 T3LAB. 14-15-16/02/2012. VIALAB Origins . Research program funded by Regione Emilia-Romagna From industrial to technological districts

E N D
Experimentingwithmachine visionand ZynqM. Viti1, E. Primo2, C. Salati2 1Datalogic Automation Srl 2 T3LAB 14-15-16/02/2012
VIALAB Origins • Research program funded by Regione Emilia-Romagna • From industrial to technological districts • Projects are lead by industrial partners • Project duration: 2 years • VIALABApplied Industrial Vision Laboratory • Computer Vision as an enabling technology for the manufacturing automation industry
VIALAB Partners • Datalogic • Automation (Prime Contractor) • Scanning (ADC) • System • SPA • Logistics • T3LAB, Region Emilia-Romagna High Technology Network • DEIS, Universityof Bologna • CRIT
VIALAB topics • Computing platforms and computational models • HW acceleration of machine vision algorithms • 3D Vision • Benchmark of machine vision libraries
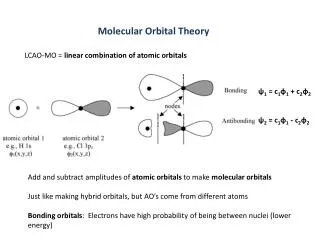
Machine Vision &Image Processing input = image output = image Image Processing input = image output = information Computer Vision image image information Image Processing Computer Vision machine vision = computer vision in industrial applications
FPGA in machine vision:conventional approach • Limited to image processing (image-in image-out) • Limited to videoStream-in videoStream-out applications • Limited to pre-processing in full computer vision applications • Pipeline architecture • PL (Programmable Logic) pre-filtering video stream in info out RAM PL CPU time PL - - - Img[n] Img[n+1] - - - CPU - - - Img[n-1] Img[n] - - -
Image processing • Kernel and sliding window • Examples average 4-connectivity 8-connectivity horizontal Sobel gradient x y
Filters • Smoothing filters • Median • Mean • Gauss (composed for optimization purpose: horizontal vertical) • Morphological smooth (with customizable mask) (composed: open close) • Morphological operators (with customizable mask) • Erode • Dilate • Open (composed: erode dilate) • Close (composed: dilate erode) • Edge detection • Sobel • Morphological gradient (with customizable mask) (composed: dilate - erode) • Punctual operators • Binarization (with customizable threshold) • Edge thinning • Canny-like (composed: median Sobel non-maximal suppression) • Edge sharpening • 3 different masks
Future filters • Punctual operators • Histogram stretching • Histogram equalization • Corner detection • Harris (composed: Sobelcornerness non-maximal suppression) • Piramidization • Bilateral
Filters’ architecture Filter BRAM extractor filterlogic video stream in video stream out NxN pixel BRAM BRAM . . . BRAM
Filters’ architecture • Maximum kernel size is statically configurable • Actual kernel size is dynamically configurable • Changing the maximum kernel size affects • time performance • latency • FPGA area • The actual kernel size has no effects on performance characteristics • The maximum operating frequency (with peaks of 200 MHz) depends only on the slowest combinatorial stage of a filter logic • Designed to • Maximize parallelism • Minimize dependence from kernel size
Selectable filtering CPU DDR mem. contr. bus selection register video stream out Filter.1 video stream out Filter.2 video stream in video stream out . . . Filter.n = Filter.n.2 Filter.n.1 video stream out video stream Filter.n.2 Filter.n.1
Demo characteristics • Screen = 1280 x 1024 pixel, 60 fps • b/w pixel rate • raw: ~80Mp/s • within a row: ~110Mp/s • Compiled at 166Mp/s • Target FPGA: Xilinx® Spartan®-6 LX150T • EvalBoard: AVNET Xilinx® Spartan®-6 FPGA Industrial Video Processing Kit • FPGA utilization: • Slice registers: ~25.000 (~14%) • LUT: ~40.000 (~40%) • BRAM: 12
Selectable filtering CPU DDR mem. contr. bus selection register video stream out BRAM extractor filter.1 BRAM video stream out BRAM filter.2 video stream out video stream in . . . . . . BRAM video stream out filter.n
Selectable filtering • Kernel size is the same for all filters and the BRAM extractor • Kernel size defined at compile time • A VHDL constant • Kernel size can be changed through download of a different bitstream • After having changed the value of the VHDL constant • Value of kernel of each filter is wired-in • Wired in an attached external register • The CPU program can dynamically select what filter will be applied to the input video stream • Latency = pixelTime * rowSize * kernelSize
Dynamic configurable filtering CPU DDR mem. contr. bus selection register kernel size kernel value configuration registers video stream out BRAM extractor filter.1 BRAM video stream out BRAM filter.2 video stream out video stream in . . . . . . BRAM video stream out filter.n ̷7x7
Dynamic configurable filtering • The CPU program can dynamically select what filter will be applied to the input video stream • The CPU program can dynamically configure the size of the kernel that will be used by the selected filter • Each filter designed to handle the maximum kernel size • Kernel size: 3x3, 5x5, 7x7 • The maximum kernel size depends on specific filter • When relevant, the CPU program can dynamically configure the value of the kernel that will be used by the selected filter • 4-connectivity vs. 8-connectivity • Application specific filters in morphologic filters • The BRAM-extractor provides enough parallelism to support the largest possible kernel • BRAM-extractor output parallelism: 7x7 pixels
Programmable filtering S2 ass. reg. Filter specific registers S1 ass. reg. CPU S3 ass. reg. S4 ass. reg. bus DDR mem. contr. threshold connectivity . . . . . . video stream in video stream out . . . . . . . . . . . . . . . . . . . . . . . . filter.n filter.2 filter.m filter.1 BRAM extr. BRAM extr. BRAM extr. BRAM extr. Stage 3 Stage 1 Stage 4 Stage 2
Programmable filtering • A set of filters is available • The filter that is embedded in each stage is configurable • The kernel size of each filter is determined at compile time, but the kernel sizes of different filters may be different • The kernel size of a filter depends on the specific characteristics of the filter • When relevant, the CPU program can dynamically set filter specific parameters; e.g. the value of the kernel in morphologic filters: • 4-connectivity vs. 8-connectivity • Application specific filters • Latency = • This would have been done better through partial reconfiguration
Video stream to memory CPU DDR mem. contr. bus selection register mem. interface kernel size kernel value configuration registers video stream out BRAM extractor filter.1 BRAM video stream out BRAM filter.2 video stream out video stream in . . . . . . BRAM video stream out filter.n
FPGA in machine vision:conventional approach • PL = pre-processing = image processing • CPU = machine vision • Parallelism through pipeline video stream in info out RAM PL CPU time PL - - - Img[n] Img[n+1] - - - CPU - - - Img[n-1] Img[n] - - -
Alternative approach:hardware acceleration char *inputData = 0xNNNNNNNN; char *outputData = 0xMMMMMMMM; char *accelInputData = 0xKKKKKKKK; char *accelOutputData = 0xLLLLLLLL; char *accelControl = 0xJJJJJJJJ; // Pure SW processing Process_data_sw(inputData, outputData); // HW Accelerator-based processing Send_data_to_accel(inputData, accelInputData); Process_data_hw(accelControl); Recv_data_from_accel(accelOutputData, outputData);
Alternative approach:hardware acceleration • How long does Process_data_hw(accelControl); last? • many CPU machine instructions: • Asymmetric MultiProcessing (AMP) • Interrupt based interaction • CPU performs other jobs in the meantime • few CPU machine instructions: • Co-Processing • Busy-wait interaction • CPU does nothing in the meantime
Alternative approaches:Asymmetric multi-processing • Zynq-7000 EPP Software Developers Guide: “Asymmetric multi-processing is a processing model in which each processor in a multiple-processor system executes a different operating system image while sharing the same physical memory” • Related to SW • Limited to the 2 cores of the ARM Cortex™–A9 multiprocessor • A stronger meaning of AMP: a subset of PL is seen as a processor performing a computational task in parallel with the CPU processing • PLAMP is not restricted to pre-processing • PLAMP may access data in DDR • PLAMP asymmetric multi-processing represented by a computational thread in the CPU SW environment
Alternative approaches:Asymmetric multi-processing video stream in PLPP info out PLAMP CPU time DDR PLPP - - - Img[n] Img[n+1] - - - CPU - - - Img[n-1] Img[n] - - - PLAMP - - - Img[n-1] Img[n] - - -
Asymmetric multi-processingCase study: blob analysis • PLPP (pre-processing) produces an image containing all binarized blobs and stores it in central memory • CPU performs blob labeling, computes the related region of interest (ROI) and produces the list of blobs • PLAMP and CPU compute in parallel a set of descriptors for each blob • CPU: orientation, rectangularity, … • PLAMP: area, perimeter, center, Euler's number, … • Each computation is represented by a SW thread • SW threads may interact with each other • Based on the related descriptors CPU classifies each blob
Asymmetric multi-processingCase study: blob analysis image with all binarized blobs image with all blobs labeled & blob ROIs list descriptor array for all blobs descriptor array & classification for all blobs video streamin PLPP CPU DDR DDR DDR DDR Computationofdescriptors CPU PLAMP CPU
Blob analysis & AMP:computation of blob descriptors time • Single sweep through ROI: • Area • Euler’s Number • Preliminary for center • Preliminary for perimeter • Single sweep through ROI: • Preliminary for pose PLAMP - - - - - - CPU - - - Center • Perimeter • Compactness • Pose • Length • Width • Eccentricity • Bounding box area Bounding box CPU or PLAMP?
Blob analysis & pre-processing:computation of blobs Preliminarysmoothing video stream in video stream video stream video stream Median Gaussian Binarization Morphologicalsmoothing video stream out video stream video stream Open Close
Blob analysis, pre-filtering &asymmetric multi-processing time PLPP Img[n+1] PLAMP - - - Img[n].blob[1] Img[n].blob[2] - - - Img[n].blob[k] - - - CPU bloblabeling - - - Img[n].blob[1] Img[n].blob[2] - - - Img[n].blob[k]
Asymmetric multi-processing • CPU • No parallelism/pipeline • Floating-point operations • PLAMP • Parallelism • Pipeline • Simple operations with short integers • Operations that can be based on look-up tables
Alternative approaches:Co-processing • Each ARM Cortex™–A9 MPcore™ already includes a FPU/NEON™ accelerator • But one may think of an application specific co-processor • A subset of PL is seen as a co-processor implementing an application specific, extension instruction set • PLCP includes • An extension register file (e.g. PL distributed memory) • An extension “ALU” • An ARM SW thread • Loads the operands in the extension register file • Operands may be references to data in DDR or On-Chip Memory • Activates the extension ALU • (Busy-)Waits for the completion of the operation • Fetches the results from the extension register file
Alternative approaches:Co-processing video stream in PLPP info out PLCP CPU PLAMP time PLPP - - - Img[n+1] - - - DDR PLAMP - - - Img[n] - - - CPU - - - Img’[n] Img”[n] - - - PLCP op
Co-processingCase study: Sobel gradients • hgrad[x, y] = normalize(p[x+1, y-1] + 2*p[x+1, y] + p[x+1, y+1] + - p[x-1, y-1] - 2*p[x-1, y] - p[x-1, y+1]) vgrad[x, y] = normalize(p[x-1, y+1] + 2*p[x, y+1] + p[x, y+1] + - p[x-1, y-1] - 2*p[x, y-1] - p[x-1, y-1]) • CPU operations: 4 (left) shifts + (5*2) sums + 2 (right) shifts • PL operations: • Cost of shift: 0 • Depth of each summation tree = 3 • Total time complexity: 3 sums
Co-processingCase study: blob analysis • Classification based on nearest neighbor strategy • Distance between the descriptor array of a blob and the descriptor array of all possible object classes • Two levels of parallelism: • Distance from several possible object classes • Distance of two descriptor arrays = f(distance of individual descriptors) • PL based co-processor to compute the distance of two descriptor arrays
Acknowledgements • Xilinx • Silica • Stefano Tabanelli • Universitàdi Bologna – DEIS • Prof. Luigi Di Stefano, VIALAB Scientific Director • Prof. Stefano Mattoccia, VIALAB OR4 Advisor • Michele Benedetti (Datalogic Automation), VIALAB Director • Luca Turrini (System), VIALAB OR4 responsible