Download

1 / 22
230 likes | 250 Views
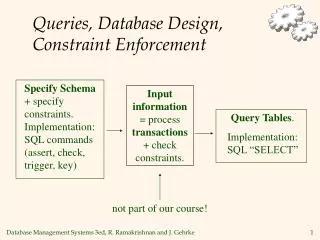
A Formal Approach to Finding Explanations for Database Queries. Sudeepa Roy Dan Suciu University of Washington, Seattle. We need to understand “Big Data”. Extract Feature. Clean. Integrate. 1. Acquire Data. 2. Prepare Data. 3. Store in DB. Do you have an explanation?. D 1. D 2.

E N D
A Formal Approach to Finding Explanations for Database Queries Sudeepa Roy Dan Suciu University of Washington, Seattle
We need to understand “Big Data” Extract Feature Clean Integrate 1. Acquire Data 2. Prepare Data 3. Store in DB Do you have an explanation? D1 D2 Data Analysis System D3 • 6. Ask Questions! 5. Plot Graphs 4. Run Queries ref. Big data whitepaper, Jagadish et al., 2011-12
Sample Questions • Why is there a peak for #sigmod papers from industry during 2000-06, while #academia papers kept increasing? • Why is #SIGMOD papers #PODS papers in UK? Dataset: Pre-processed DBLP + Affiliation data Disclaimer: Not all authors have affiliation info Explanations by our approach at the end
Ideal goal: Why Causality “What was the cause of the observation?” • Not simple association or correlation • e.g. People having headache drink coffee Does coffee cause headache? Does headache lead to drinking coffee?
But, causality is hard… • Has been studied for many years (Hume1748) • Extensive study in AI over the last decade by Judea Pearl using the notion of intervention: X is a cause of Y, if removal of X also removes Y keeping other conditions unchanged • Needs controlled experiments • Not always possible with a database
Realistic Database-y goal: Why Explanation Causality Explanation Controlled Input database and observed query outputs Experiment Causal Paths PK-FK constraints and their generalization Intervention Remove input tuples , query output should change Top Causes Top explanations will change the output in the expected direction to a greater extent
Previous/Related Work • Pearl’s notion of causality and intervention • Causal structure from input to output by lineage • Cause = Individual input tuples, not predicates • No inherent causal structure in input data • This work: • Formal framework of explanations (= predicates) • and theoretical analysis • causal structure within input data independent of queries or user questions • allow multiple tables and joins • Optimizations and Evaluation • find top explanations using data cube • Causality in databases • Meliou et al.’10, Meliou et al.’11 • Explanations in databases • Explaining outliers in aggregate queries: Wu-Madden’13 • Specific applications (Map-Reduce, Access log, User Rating,…): e.g. Khoussainova et al.’12, Fabbri et al.’12, Das et al.’11 • Other related topics • Provenance, deletion propagation: e.g. Green et al.’07, Buneman et al.’01 • Missing answer/Why-Not: e.g. Herschel et al.’09, Huang et al.’10, Chapman-Jagadish’09 • Finding causal structure/data mining: e.g. Silverstein et al.’00 • OLAP: e.g. Sarawagi-Sathe’01 • Informally use intervention • Explanation = predicate • Mostly single table, no join Upcoming VLDB 2014 Tutorial “Causality and Explanations in Databases” Alexandra Meliou, Sudeepa Roy, Dan Suciu
Outline • Framework • Causal Paths and Intervention • Computing Intervention • Optimization: Ranking Explanations by Data Cube • Evaluation • Future Work
Input and Output Output Plot Toy DBLP database Run Group-By Queries and Plot Why is q1/q3 q2/q4 e.g. q1 selectcount(distinctx.pubid) from Author x, Authored y, Publication z where x.id = y.id andy.pubid = z.pubid andz.venue = ’SIGMOD’ and 2000 <= z.year andz.year <= 2004 andx.domain = ’com’ Explanation(s) ф : Predicate on attributes e.g. [name = ‘JG’] [name = ‘JG’] [inst = ‘C.edu’] [name = ‘JG’] [year = 2007] Note: attr from multiple tables • User question • Numerical expression E • Direction: high/low E should change when database is “intervened “with E = (q1/q3) / (q2/q4) Direction = high These values will vary for q2, q3, q4 Output Input
Causal Paths by Foreign Key Constraints • Causal path X Y: removing X removes Y • Analogy in DB: Foreign key constraints and cascade delete semantics • Intuition: • An author can exist if one of her papers is deleted • A paper cannot exist if any of its co-authors is deleted • Author • (id, name, inst, dom) Authored (id, pubid) Publication (pubid, year, venue) Standard F.K. (cascade delete) Back and Forth F.K. (cascade delete + reverse cascade delete) Forward Reverse
Causal Paths and Intervention Forward Candidate explanation ф : [name = ‘RR’] Reverse Multiple tables require universal table Intervention ф: Tuples T0 that satisfy ф + Tuples reachable from T0 Given ф, computation of ф requires a recursive query
Objective: top-k explanations • Consider user question: Why is E = (q1/q2)/(q3/q4) low, Find top-k explanations фw.r.t a score ф= E(D - ф) The obvious approach: Two sources of complexity • 1. For all possible predicates ф • Compute the intervention ф for ф • Delete tuples in фfrom D • Evaluate q1, q2, q3, q4 on D – ф • Compute E(D - ф) • 2. Find top explanations with highest scores E(D - ф) (top-k) Recursion
ф is fixed Computing ф by a Recursive Program Delete from universal table tuples |= ф Cascade delete Reverse Cascade delete • Properties: • Program has a unique least fixpointwhich can be obtained in poly-time (n = |D| steps) • Program is not monotone in database, • i.e., if D D’, not necessarily (D) (D’) • Therefore not expressible in datalog • But expressible in datalog + negation
Convergence Depends on Schema • Convergence in • ≤ 4 steps Can be generalized S • Convergence requires • n - 1 steps R T
Finding Top-k Explanations with Data Cube • For all possible predicates ф • Compute the intervention ф for ф • ….. #Possible predicates is huge Running FOR LOOP is expensive Running RECURSION is expensive Optimization: OLAP data cube why (q1*q4)/(q2*q3) high? name, inst, venue group by name, inst, venue with cube e.g. Cube for q1 e.g. Query for q1 Suppose we want predicates on attributes [name, inst, venue] as explanations
Sketch of Algorithm with Data Cube q1: com, 2000-04 q2: com, 2007-11 q3: edu, 2000-04 q4: edu, 2007-11 • All computation done by DBMS • But, • Cube Algorithm matches theory for some inputs (e.g. single table, DBLP examples) • For other inputs it is a heuristic • (recursion is necessary) Score 1. (Outer)-join the cubes + compute score 2. Run Top-K
Experiment 1: Data Cube Optimization vs. Iterative Algo Data size vs. time Natality Dataset 2010: (from National Center for Health Statistics (NCHS)). Single table with 233 attributes, ~4M entries, 2.89GB size. More experiments in the paper
Experiment 2: Scalability of the Data Cube Optimization (Max) No. of attributes in explanation predicates vs. time Data size vs. time E1 E2 E1 E2 No. of attributes Why (q1/q2)/(q3/q4) low Why (q1/q2) low
Qualitative Evaluation (DBLP) Hard due to lack of gold standard • Q. Why is there a peak for #sigmod papers from industry • during 2000-06, while #academia papers kept increasing? • Intuition: • 1. If we remove these industrial labs and their senior researchers, the peak during 2000-04 is more flattened • 2. If we remove these universities with relatively new but highly prolific • db groups, the curve for academia is less increasing
Qualitative Evaluation (DBLP) source: DBLP P = 32, S = 3 P = 24, S = 1 P = 9, S = 0 P = 15, S = 2 Not top expl.: Wenfei Fan Peter Buneman ….. P = 15, S = 12 • Q. Why is #SIGMOD papers #PODS papers in UK? P = 6, S = 12 • Intuition: • If we remove these leading theoretical DB researchers or their universities/cities, the bar for UK will look different. • e.g. for UK, • Originally: PODS = 62%, SIGMOD = 38% • Removing all publications by Libkin: PODS = 46%, SIGMOD = 54%
Current/Future Work • Optimize for arbitrary SPJUA queries and schemas • Go beyond data cube • Model increasing/decreasing trend by linear regression (E = slope) • Ranking algorithm: simple, meaningful, diverse explanations • Prototype with a GUI
Thank you Questions?