Download

1 / 22
220 likes | 263 Views
This paper explores spin locks on shared-memory multiprocessors, proposing six models based on cache coherence and interconnect types. It delves into the challenges, advantages, and drawbacks of spin locks in ensuring mutual exclusion efficiently.

E N D
The Performance of Spin Lock Alternatives for Shared-Memory Microprocessors Thomas E. Anderson Presented by David Woodard
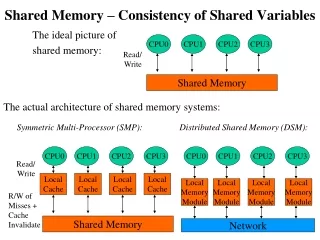
Introduction • Shared Memory Multiprocessors • Need to protect shared data structures (critical sections) • Often share resources including ports to memory (bus, network, etc.) • Challenge: Efficiently implement scalable, low latency mechanisms to protect shared data
Introduction • Spin Locks • One approach to protecting shared data on multiprocessors • Efficient on some systems, but greatly degrades performance on others
Multiprocessor Architecture • Paper focuses on two dimensions for design • Interconnect type (bus/multistage network) • Cache coherence strategy • Six Proposed Models • Bus: no cache coherence • Bus: snoopy write through invalidation cache coherence • Bus: snoopy write-back invalidation cache coherence • Bus: snoopy distributed write cache coherence • Multistage network: no cache coherence • Multistage network: invalidation based cache coherence
Mutual Exclusion and Atomic Operations • Most processors support atomic read/write operations • Test and Set Load the (old) value of lock Store TRUE in lock • If the loaded value is false, continue else continue to try until lock is free (spin lock)
Test and Set in a Spin Lock • Advantages • Quickly gain access to lock when available • Works well on systems with few processors or low contention • Disadvantages • Slows down other processors (including the processor holding the lock!) • Shared resources are also used to carry out the test and set instructions • More complex algorithms to reduce the burden on resources increases latency in acquiring lock
Spin on Read • Intended for processors with per CPU coherent caches • Each CPU can spin testing the value of the lock in its own cache • If free, then send test and lock transaction • Problem • Nature of cache coherence protocols slow down process • More pronounced in systems with invalidation based policies
Why Quiescence is Slow for Spin on Read • When the lock is released its value is modified, hence all cached copies of it are invalidated • Subsequent reads on all processors miss in cache, hence generating bus contention • Many see the lock free at the same time because there is a delay in satisfying the cache miss of the one that will eventually succeed in getting the lock next • Many attempt to set it using TSL • Each attempt generates contention and invalidates all copies • All but one attempt fails, causing the CPU to revert to reading • The first read misses in the cache! • By the time all this is over, the critical section has completed and the lock has been freed again!
Proposed Software Solutions • Based on CSMA (Carrier Sense Multiple Access) • Basic Idea: Adjust the length of time between attempts to access shared resource • Dynamically or Statically set delay? • When to delay? • After Spin on Read returns true, delay before setting • After every memory access Better on models where Spin on Read generates contention
Proposed Software Solutions • Delay on attempted set • Reduces the number of TSLs thereby reducing contention • Works well when delay is short and there is little contention OR when delay is long and there is a lot of contention • Delay on every memory access • Works well on systems without per CPU caches • Reduces the number of memory accesses thereby reducing the number of read instructions
Length of Delay - Static • Advantages • Each processor is given its own “slot”; this makes it easy to assign priority to CPUs • Few empty slots = good latency; Few crowded slots = little contention • Disadvantages • Doesn’t adjust to environments prone to bursts • Processors with same delay that have conflict will always have conflict
Length of Delay - Dynamic • Advantages • Adjusts to evolving environments; increases delay time after each conflict (up to a ceiling) • Disadvantages • What criteria determine the amount of back off? • Long critical sections could keep increasing delay in some CPUs • Bound maximum delay: What if the bound is too high? Too low?
Proposed Software Solution - Queuing • Flag Based Approach • As CPU waits Add to queue • Waiting CPUs spin on flag of processor ahead of it in the queue (different for each CPU) • No bus or cache contention • Queue assertion and deletion require locks • Not useful for small critical sections (such as queue operations!)
Proposed Software Solution - Queuing • Counter Based Approach • Each CPU does an atomic read and increment to acquire a unique sequence number • When a processor releases a lock it signals the processor with the next successive sequence number • Sets a flag in a different cache block unique to the waiting processor • Processor spinning on its own flag sees the change and continues (occurs invalidation and read miss cycles)
Proposed Software Solution - Queuing • Advantages • Separate flag locations in memory prevents saturation from multiple accesses • Especially useful for multistage networks (separate memory modules) • Disadvantages • Still not efficient for models without per processor caches Requires memory access of one memory location • Increased lock latency due to increased instructions (increment counter, check location, zero location, set another location) • Preempting a process cause all processes behind it in the queue to wait • Can’t wait for multiple events
Hardware Solutions: Network • Combining Networks • Combine requests to same lock (forward one, return other) • Combining benefit increases with increase in contention • Hardware Queuing • Blocking enter and exit instructions queue processes at memory module • Eliminate polling across the network • Goodman’s Queue Links • Stores the name of the next processor in the queue directly in each processor’s cache • Inform next processor asynchronously (via inter-processor interrupt?)
Hardware Solutions: Bus • Use additional bus with specific coherence policy • Additional die space? Separate clock speed for bus? • Read broadcast • When one processor reads a value which other processors also need, fill all caches with one read • Eliminates extended quiescence waiting periods due to pending reads • Monitor bus for test and set instructions • Prevents bus contention If one processor performs the test and set instruction, it can share the result and other processors can abort their test and set instructions • Typically cache and bus controllers are not aware of instruction types; this information is handled by functional units (ex: ALUs) further down the pipeline
Conclusions • Traditional Spin Lock approaches are not affective for large numbers of processors • When contention is low, models borrowed from CSMA work well • Delay slots • When contention is high, queuing methods work well • Trades lock latency for more efficient/parallelized lock hand-off • Hardware approaches are very promising, but requires additional logic Additional cost in die size and money to manufacture
Resources • Dr. Jonathan Walpole http://web.cecs.pdx.edu/~walpole/class/cs533/winter2008/home.html • Emma Kuo: http://web.cecs.pdx.edu/~walpole/class/cs533/winter2007/slides/42.pdf