Download

1 / 30
300 likes | 311 Views
Learn about R-Tree index structure for range queries in multiple dimensions such as CAD and geo-data applications. Discover insertion, splitting strategies, and the optimization of search routines within R-Trees.

E N D
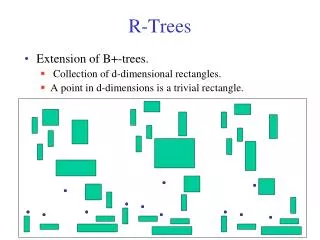
Introduction • Range queries in multiple dimensions: • Computer Aided Design (CAD) • Geo-data applications • Support special data objects (boxes) • Index structure is dynamic.
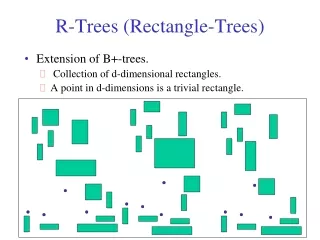
R-Tree • Balanced (similar to B+ tree) • I is an n-dimensional rectangle of the form (I0, I1, ... , In-1) where Ii is a range • Leaf node index entries: (I, tuple_id) • Non-leaf node entry: (I, child_ptr) • M is maximum entries per node. • m M/2 is the minimum entries per node.
Invariants • Every leaf (non-leaf) has between m and M records (children) except for the root. • Root has at least two children unless it is a leaf. • For each leaf (non-leaf) entry, I is the smallest rectangle that contains the data objects (children). • All leaves appear at the same level.
Searching • Given a search rectangle S ... • Start at root and locate all child nodes whose rectangle I intersects S (via linear search). • Search the subtrees of those child nodes. • When you get to the leaves, return entries whose rectangles intersect S. • Searches may require inspecting several paths. • Worst case running time is not so good ...
Insertion • Insertion is done at the leaves • Where to put new index E with rectangle R? • Start at root. • Go down the tree by choosing child whose rectangle needs the least enlargement to include R. In case of a tie, choose child with smallest area. • If there is room in the correct leaf node, insert it. Otherwise split the node (will be illustrated later) • Adjust the tree ... • If the root was split into nodes N1 and N2, create new root with N1 and N2 as children.
Adjusting the tree • N = leaf node. If there was a split, then NN is the other node. • If N is root, stop. Otherwise P = N’s parent and EN is its entry for N. Adjust the rectangle for EN to tightly enclose N. • If NN exists, add entry ENN to P. ENN points to NN and its rectangle tightly encloses NN. • If necessary, split P • Set N=P and go to step 2.
Splitting Nodes • A well designed splitting strategy should obey: • Minimize the total area of the two nodes • Minimize the overlapping of the two nodes
Splitting Nodes – Exhaustive Search • Try all possible combinations. • Optimal results! • Bad running time!
Splitting Nodes – Quadratic Algorithm • Find pair of entries E1 and E2 that maximizes area(J) - area(E1) - area(E2) where J is covering rectangle. • Put E1 in one group, E2 in the other. • If one group has M-m+1 entries, put the remaining entries into the other group and stop. If all entries have been distributed then stop. • For each entry E, calculate d1 and d2 where di is the minimum area increase in covering rectangle of Group i when E is added. • Find E with maximum |d1 - d2| and add E to the group whose area will increase the least. • Repeat starting with step 3.
Greedy continued • Algorithm is quadratic in M. • Linear in number of dimensions. • But not optimal.
Splitting Nodes – Linear Algorithm • For each dimension, choose entry with greatest range. • Normalize by dividing the range by the width of entire set along that dimension. • Put the two entries with largest normalized separation into different groups. • Randomly, but evenly divide the rest of the entries between the two groups. • Algorithm is linear, almost no attempt at optimality.
The R*-tree: An Efficient and Robust Access Method for Points and Rectangles Norbert Beckmann, Hans-Peter Kriegel Ralf Schneider, Bernhard Seeger
Introduction • R-trees use heuristics to minimize the areas of all enclosing rectangles of its nodes. • Why? • Why not ... • minimize overlap of rectangles? • minimize margin (sum of length on each dimension) of each rectangle (i.e. make it as square as possible)? • optimize storage utilization? • all of the above?
Minimizing Covering Rectangle • Dead space is the area covered by the covering rectangle which is not covered by the enclosing rectangles. • Minimizing dead space reduces the number of paths to traverse during a search, especially if no data matches the search.
Minimizing Overlap • Also reduces number of paths to be traversed during a search, especially when there is data that matches the search criteria.
Mimimizing Margin • Minimizing margin produces “square-like” rectangles. • Squares are easier to pack so this tends to produce smaller covering rectangles in higher levels.
Storage Utilization • Reduces height of tree, so searches are faster. • Searches with large query rectangles benefit because there are more matches per page.
Problems with Guttman’s Quadratic Split • Distributing entries during a split favors the larger rectangle since it will probably need the least enlargement to add an additional item. • When one group gets M-m+1 entries, all the rest are put in the other node.
R*-tree - ChooseSubtree • Let E1, ..., Ep be rectangles of entries of the current node, • ChooseSubtree(level) finds the best place to insert a new node at the appropriate level. • CS1: Set N to be the root • CS2: If N is at the correct level, return N. • CS3: If N’s children are leaves, choose the entry whose overlap cost will increase the least. If N’s children are not leaves choose entry whose rectangle will need least enlargement. • CS4: Set N to be the child whose entry was selected and repeat CS2. • Ties are broken by choosing entry whose rectangle needs least enlargement. After that choose rectangle with smallest area.
ChooseSubtree analysis • The only difference from Guttman’s algorithm is to calculate overlap cost for leaves. This creates slightly better insert performance.
Optimizing Splits • For each dimension, entries are sorted by low value, and then by high value. • For each sort we create d = M-2m+2 distributions. In the kth distribution (1kd), the first group has the first (m-1)+k entries. • We also have the following measures (Ri is the bounding rectangle for group i) : • area-value = area[R1]+area[R2] • margin-value = margin[R1]+margin[R2] • overlap-value = area[R1 R2]
Optimizing Splits • Split: S1: call ChooseSplitAxis to find axis perpendicular to the split. S2: call ChooseSplitIndex to find the best distribution. Use this distribution to create the two groups. • ChooseSplitAxis: CSA1: for each dimension, compute the sum of margin-values for each distribution produced. CSA2: return the dimension that has minimum sum. • ChooseSplitIndex: CSI1: for the chosen split axis, choose distribution with minimum overlap-value. Break ties by choosing distribution with minimum area-value.
Analyzing Splits • Split algorithm was chosen based on performance and not on any particular theory. • Split is O(n log(n)) in dimension. • m = 40% of M yields good performance (same value of m is also near-optimal for Guttman’s quadratic split algorithm).
Forced Reinsert • Splits improve local organization of tree. • Can the improvement be made less local? • Why not perform reinsert during inserts?
R* Insert • InsertData ID1: call Insert with leaf level as the parameter. • Insert(level) I1: call ChooseSubtree(level) to find the node N (at the appropriate level) into which we place the new entry. I2: if there is room in N, insert new entry, otherwise call OverflowTreatment with N’s level as parameter. I3: if OverflowTreatment caused a split, propagate OverflowTreatment up the tree (if necessary). I4: if root was split, create new root. I5: adjust all covering rectangles in insertion path.
R* Insert • OverflowTreatment(level) OT1: If the level is not the root and this is the first OverflowTreatment for this level during insertion of 1 rectangle, call Split. Otherwise call Reinsert with level as the parameter. • Reinsert(level) RI1: In decreasing order, sort the entries Ei of N based on the distance from the center of Ei to the center of N’s bounding rectangle. RI2: Remove the first p entries of N and adjust N’s bounding rectangle. RI3: call Insert(level) on the p entries in reversed sort order (close reinsert). Experimentally, a good value of p is 30% of M.
Insert Analysis • Experimentally, R* insert reduces number of splits that have to be performed. • Space utilization is increased. • Close reinsert tends to favor the original node. Outer rectangles may be inserted elsewhere, making the original node more quadratic. • Forced reinsert can reduce overlap between neighboring nodes.