Download

1 / 9
90 likes | 174 Views
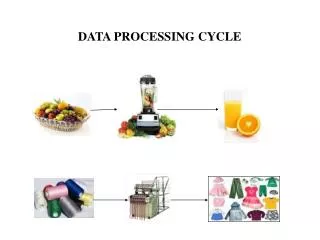
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises, what is raw data and why does it need conversion? Raw data can be any fact or figure, for example, the number of hours an employee has worked in a month, his rate of pay etc. <br><br>https://www.loginworks.com/blogs/top-big-data-tools-to-store-data-in-data-processing-cycle/

E N D
TOP BIG DATA TOOLS TO STORE DATA IN DATA PROCESSING CYCLE Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises, what is raw data and why does it need conversion? Raw data can be any fact or figure, for example, the number of hours an employee has worked in a month, his rate of pay etc. all these are numbers or facts, the meaningful information that comes out of it after processing is the employee’s payroll or an invoice. This is the most common reference for data processing. The term is closely related to specialist business tasks like sales order processing or sales ledger processing, graphics, charts etc. Therefore, much of the information used in an organization is provided by data processing systems. Data processing can be achieved in several ways. The method that must be deployed for it depends on certain factors like: 1. Size and the nature of the business 2. Timing facets STAGES OF DATA PROCESSING
Data processing is divided into 6 stages, and we receive the output in the final stage. These stages are: 1. Collection of data 2. Storage of data 3. Data Sorting 4. Data Processing 5. Data Analysis 6. Presentation and Conclusions For any logical operations or calculations to be performed on data, first all the required facts must be collected. This data is then stored and processed. This task has seen several advancements in the types of tools that can be used to accomplish it. PRESENT DAY ORGANIZATION NEEDS In today’s digital world, Electronic Data Processing is the most popular technique of data processing. Organizations hold a large amount of data or Big
Data to be processed for their functioning. Traditional applications or tools are becoming obsolete for processing this massive amount of data as they are incapable of handling it. Most organizations process data exceeding Terabytes in size. Several challenges are faced in processing this amount of data that is also diverse and complex to handle. It has been observed through surveys in organizations that almost 80% of the data collected in an unstructured format. To produce the relevant output after data processing, most relevant and important data must be captured. However, with the unstructured large volume of data, this task gets extremely complicated and unattainable. Then comes the issue of storage of this massive amount of data. Modern technology has sufficed the situation through present day tools developed for the storage and analysis of Big Data. Tools to store and analyze data in Data Processing 1. APACHE HADOOP Apache Hadoop is an open-source software framework based on java capable of storing a great amount of data in a cluster. It can process large sets of data in parallel across clusters of computers. The concept is to scale up from a single server to several thousands of machines, each with a capability to perform local computation and provide storage. It eliminated the dependency on hardware for delivering high-availability. The detection and handling of failures are possible through the library at the application layer. Apache Hadoop offers below modules: Hadoop Common: This module consists of the utilities to support other modules. Hadoop Distributed File System (HDFS): High-throughput access to the application data is provided by the distributed file system of Hadoop. Hadoop YARN: cluster resource management and job scheduling are achieved by this framework.
Hadoop MapReduce: It involves parallel processing of large sets of data or Big data. Hadoop Distributed File System (HDFS) is the main storage system of Hadoop. The HDFS splits the large data sets across several machines to be processed in parallel. There is also replication of data in a cluster, performed by HDFS, thus, enabling high availability of data. Several projects running in relation to Hadoop at Apache, catering to data storage include: Cassandra™: This scalable multi-master database does not allow any single points of failure. Chukwa™: Large distributed systems require management which is achieved by a data collection system called Chukwa. HBase™: HBase provides the capability of structured data storage through a distributed and scalable database for large tables. Hive™: Hive is a data warehouse that provides the capability of data summarization and ad hoc querying. 2. MICROSOFT HDINSIGHT
Azure HDInsight is Microsoft’s cloud-based solution for extremely quick, easy and cost-effective data processing on a large scale. HDInsight utilizes Windows Azure Blob storage as the default file storage system. This cloud service is capable of providing high availability of data at low cost. Multiple scenarios like Data warehousing, ETL, Machine Learning and IoT are enabled through it. HDInsight uses the most commonly used open-source frameworks, for example, Spark, Hadoop, Hive, Storm, Kafka etc. Microsoft HDInsight is a highly effective analytics service for organizations and enterprises which is fully- managed and full-spectrum. The service has increased in its popularity for being cost-effective with additional fifty percent prices cut on HDInsight. This obviously inclines enterprises to switch to the cloud. Organizations have highly benefited through the HDInsight service which has proved itself capable of satisfying their primary needs. The system is highly secure, with enterprise-grade protection through encryption and meets the essential compliance standards like PCI, HIPPA, ISO etc. 3. NOSQL NoSQL (Not Only SQL) database has come up with the ability to handle unstructured data when the traditional SQL could only handle large sets of structured data. There is no particular schema in NoSQL databases to support unstructured data. This was quite a boost for the enterprises incorporating regular updates to their applications, in achieving the flexibility to handle them quickly. There can be a wide variety of data models, which may include key- value, document, graph and columnar formats. Better performance is achieved through NoSQL when the amount of data is to be stored. It enables large-scale data clustering in web applications and cloud. Several NoSQL DBs are available in the present day to be able to analyze Big Data. Data storage is achieved through:
Key-value stores: stores each piece of data or value associated with a unique key. Examples of implementations include Aerospike, Memchache DB, Berkeley DB, Riak, Redis etc. Document Databases: stores semi-structured data and metadata in a document format. Example, MongoDB, MarkLogic, CouchDB, DoucumentDB etc. Wide-column stores: the data is stored in the data tables organized as columns instead of rows. Example, Cassandra, Google BigTable, HBase etc. Graph stores: stores data in the form of nodes, just like records in an RDBMS. The connections between the nodes are called edges. Example, Allegro graph, Neo4j, IBM Graph, Titan etc. Features of NoSQL include: 1. Offers on-demand, pay as you go system 2. Auto-healing and Seamless upgrades 3. Flexible to scale up and down as required 4. Customizable and deep monitoring alert system 5. Very secure and reliable 6. Backup and recovery options available 4. HIVE Hive is a data warehouse built on top of Apache Hadoop, facilitating reading, writing and management of large datasets. The dataset resides in a distributed storage system.It is managed using SQL-like query option HiveSQL (HSQL). HSQL is used to analyze and query Big Data. The primary use of Hive is for Data mining. Its features include:
1. Tools allowing easy access to data through SQL, which in turn enable data warehousing tasks,for example, extract/transform/load (ETL), data analysis and reporting. 2. It can work with a variety of data formats imposing a structure to them. 3. It can directly access the data stored in the distributed file system of Hadoop- HDFS or can access it through other databases like HBase. 4. Query execution is possible through Apache Tez, Apache Spark, or MapReduce 5. It supports SQL like structured language called HSQL. 6. Sub-second query recovery through Hive LLAP, Apache Slider and Apache YARN. The designing of Hive was not done for online transaction processing (OLTP) workloads. Hive is best utilized for traditional data warehousing jobs. 5. SQOOP Apache Sqoop is a tool designed to connect Hadoop with numerous relational databases in order to transfer data. It is capable of transferring a large amount of data between structured data stores and Hadoop effectively and efficiently. Advantages of Sqoop: 1. Sqoop facilitates the transfer of data between various types of structured databases like Postgres, Oracle, Teradata, and so on. 2. Offloading of certain processing done in the ETL is possible through Sqoop since the data resides in Hadoop. It is a cost-effective, efficient and fast method of carrying out Hadoop processes. 3. Data transfer via Sqoop can be executed in parallel among many nodes. 6. POLYBASE Polybase technology can access data from outside the database through t-SQL. PolyBase works on top of SQL Server 2012 Parallel Data Warehouse (PDW) and it accesses data stored in PDW. It can execute queries on external Hadoop data
or to import or export Azure Blob storage data. PolyBase is extremely useful for organizations to make lucrative decisions on data. This is achieved by bridging the gap of data transfer between different data sources like structured relational databases and unstructured Hadoop data. There is no need for installation of any external software to your Hadoop environment to achieve this. Knowledge of Hadoop is not required by end users to query the external tables. PolyBase Features: 1. It can query the data from SQL Server or PDW stored in Hadoop. Since the data is distributed in different distributed storage systems like Hadoop for scalability, PolyBase enables us to query that data easily through t-sql. 2. It can query the data that is stored inside Azure Blob Storage. Data used by Azure services is securely stored and managed in Azure Blob storage. PolyBase technology is an effective and efficient medium to work on it through t-sql. 3. It can import Hadoop data and data stored in Azure Blob Storage or Azure Data Lake Store. PolyBase works on Microsoft SQL’s columnstore technology to 4. perform analysis on data imported from Hadoop, Azure data lake store or Azure Blob store without the need of performing ETL operations. 5. It can export data to Hadoop, Azure Data Lake Store or Azure Blob Storage. As Hadoop and Azure storage systems provide cost-effective methods for data storage, PolyBase provides the technology to export data to these systems and archive it. 6. Integration with BI tools. Integration with Microsoft’s Business Intelligence tools and other analysis tools is also possible with PolyBase. Performance of PolyBase: 1. Push computation to Hadoop. The query optimizer used in PolyBase makes a cost-based decision after which computations are pushed to Hadoop to considerably improve the performance. This decision is based on statistics. This creates MapReduce jobs and utilizes Hadoop’s distributed resource. 2. Scales compute resources. The use of SQL Server PolyBase scale-out groups improves the query performance tremendously. Parallel data transfer,
therefore, becomes possible between different SQL server instances and the nodes in Hadoop. External data computation also leverages extra compute resources. 7. BIG DATA IN EXCEL 2013 Excel has been popular with many users and organizations, who find comfort in using it more than other complicated software. Considering this Microsoft has come up with a tool that can connect data stored in Hadoop, which is EXCEL 2013. Hortonworks primarily provides Enterprise Apache Hadoop, which gives an option to access big data using EXCEL 2013stored in their Hadoop platform. The Power View feature of EXCEL 2013 can be easily used to summarize data in Hadoop. Excel 2013 provides the ability to perform the exploratory or ad-hoc analysis. Excel is popular with data analysts who prefer using traditional tools to get rich data insights by interacting with new types of data stores. The ‘Data Model’ feature of Excel 2013 supports large volumes of data for organizational usage. Connect with source url:- https://www.loginworks.com/blogs/top-big-data-tools-to-store-data-in-data- processing-cycle/