Download
1 / 1
10 likes | 149 Views
TWO APPROACHES TO SPEECH INTELLIGIBILITY RESEARCH 1) Target cues in highly intelligible speech -- Clear speech -- Lombard effect -- Hyper-articulated speech 2) Target cues lost due to hearing impairment -- Loudness recruitment, elevated threshold

E N D
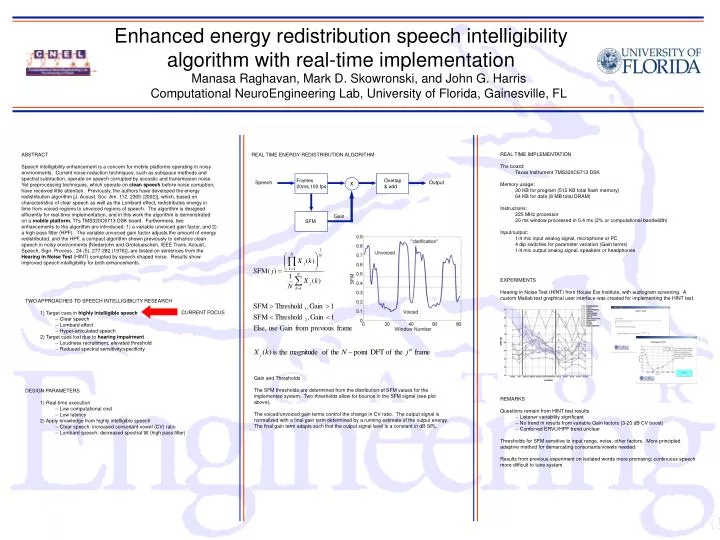
TWO APPROACHES TO SPEECH INTELLIGIBILITY RESEARCH 1) Target cues in highly intelligible speech -- Clear speech -- Lombard effect -- Hyper-articulated speech 2) Target cues lost due to hearing impairment -- Loudness recruitment, elevated threshold -- Reduced spectral sensitivity/specificity CURRENT FOCUS Overlap & add Frames 20ms,100 fps x Speech Output Gain SFM Enhanced energy redistribution speech intelligibility algorithm with real-time implementation Manasa Raghavan, Mark D. Skowronski, and John G. Harris Computational NeuroEngineering Lab, University of Florida, Gainesville, FL REAL TIME IMPLEMENTATION The board: Texas Instrument TMS320C6713 DSK Memory usage: 30 KB for program (512 KB total flash memory) 64 KB for data (8 MB total DRAM) Instructions: 225 MHz processor 20 ms window processed in 0.4 ms (2% or computational bandwidth) Input/output: 1/4 mic input analog signal, microphone or PC 4 dip switches for parameter variation (Gain terms) 1/4 mic output analog signal, speakers or headphones ABSTRACT Speech intelligibility enhancement is a concern for mobile platforms operating in noisy environments. Current noise-reduction techniques, such as subspace methods and spectral subtraction, operate on speech corrupted by acoustic and transmission noise. Yet preprocessing techniques, which operate on clean speech before noise corruption, have received little attention. Previously, the authors have developed the energy redistribution algorithm [J. Acoust. Soc. Am. 112, 2305 (2002)], which, based on characteristics of clear speech as well as the Lombard effect, redistributes energy in time from voiced regions to unvoiced regions of speech. The algorithm is designed efficiently for real-time implementation, and in this work the algorithm is demonstrated on a mobile platform, TI’s TMS320C6713 DSK board. Furthermore, two enhancements to the algorithm are introduced: 1) a variable unvoiced gain factor, and 2) a high pass filter (HPF). The variable unvoiced gain factor adjusts the amount of energy redistributed, and the HPF, a compact algorithm shown previously to enhance clean speech in noisy environments [Niederjohn and Grotelueschen, IEEE Trans. Acoust., Speech, Sign. Process., 24 (5), 277-282 (1976)], are tested on sentences from the Hearing in Noise Test (HINT) corrupted by speech-shaped noise. Results show improved speech intelligibility for both enhancements. REAL TIME ENERGY REDISTRIBUTION ALGORITHM EXPERIMENTS Hearing in Noise Test (HINT) from House Ear Institute, with audiogram screening. A custom Matlab test graphical user interface was created for implementing the HINT test. Gain and Thresholds The SFM thresholds are determined from the distribution of SFM values for the implemented system. Two thresholds allow for bounce in the SFM signal (see plot above). The voiced/unvoiced gain terms control the change in CV ratio. The output signal is normalized with a final gain term determined by a running estimate of the output energy. The final gain term adapts such that the output signal level is a constant in dB SPL. DESIGN PARAMETERS 1) Real-time execution -- Low computational cost -- Low latency 2) Apply knowledge from highly intelligible speech -- Clear speech: increased consonant-vowel (CV) ratio -- Lombard speech: decreased spectral tilt (high pass filter) REMARKS Questions remain from HINT test results -- Listener variability significant -- No trend in results from variable Gain factors (3-20 dB CV boost) -- Combined ERVU/HPF trend unclear Thresholds for SFM sensitive to input range, noise, other factors. More principled adaptive method for demarcating consonants/vowels needed. Results from previous experiment on isolated words more promising; continuous speech more difficult to tune system.






















