Download

1 / 28
280 likes | 366 Views
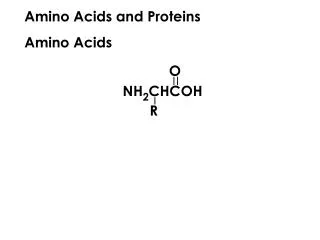
Identifying Extracellular Plant Proteins Based on Frequent Subsequences of Amino Acids. Y. Wang, O. Zaiane, R. Goebel. Introduction. Protein: linear sequence of amino acids Protein subcellular localization Plant: nuclear, cytoplamic, mitochondria, extracellular, …

E N D
Identifying Extracellular Plant Proteins Based on Frequent Subsequences of Amino Acids Y. Wang, O. Zaiane, R. Goebel
Introduction • Protein: linear sequence of amino acids • Protein subcellular localization • Plant: nuclear, cytoplamic, mitochondria, extracellular, … • Intracellular vs. Extracellular • Sequence information alone • Class imbalance • Transparency
Related Word • N-terminal sorting signals • Amino acid composition • Lexical analysis • Integrative approach • Subsequence methods
Predicting Extracellular Proteins • Feature Extraction • Support Vector Machine • Boosting • Frequent Pattern Method
Feature Extraction • Frequent subsequences: subsequences that occur in more than a certain percentage of extracellular proteins • Strong discriminative power • Perform similar functions via relationed biochemical mechanism • Capture local similarity
Support Vector Machine • Input data represented as feature vectors • Find a linear separator that separate the data and maximize the margin • Kernel function: nonlinear separator
SVM for extracellular protein prediction • Data Transformation(sequencevector) • Frequent subsequences as features • Transform protein sequence as binary vectors • Kernel Functions • Linear kernel • Polynomial kernel • RBF kernel
Boosting • Iterative algorithms to improve weak classifier • Different weighted distribution of examples in each iteration • Increase the weights of incorrectly classified examples, and decrease the weights of correctly classified ones
Frequent Pattern Method • Frequent pattern: *X1*X2*…*Xn* extracellular • X1,X2,…Xn are frequent subsequences • “*” can be substituted to zero or up to MaxGap amino acids when matching a protein sequence
Z-number :support of rule R :accuracy of rule R
Experiments • Dataset(PASub project at UofA) • Plant: 3293 proteins, 171 extracellular • Five-cross validation
Evaluation Matrix • Overall accuracy is not good enough • F-measure
Result(Frequent Pattern) MinLen=3 Min_gain=0.1 MinSup=5% MinConf=80% MaxGap=300
Conclusion • Presented three methods for identifying extracellular proteins based on frequent subsequence of amino acids • SVM achieves the best result • FSP method provides easily interpretable rules
Future Work • Use for information about proteins (e.g., structure, function, …) • Integrating amino acid composition into FSP method • Incorporate more biological knowledge