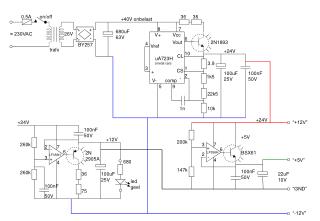
Download

1 / 27
280 likes | 463 Views
Co-Segmentation of 3D Shapes via Subspace Clustering Ruizhen Hu, Lubin Fan, Ligang Liu. Computer Graphics Forum (Proc. SGP), 2012. Presenter Yunhai@VCC. Background. Single-Shape Segmentation. [Shalfman et al. 2002]. [Katz et al. 05]. [Attene et. al 2006]. [Lai et al. 08]. K-Means.

E N D
Co-Segmentation of 3D Shapes via Subspace Clustering Ruizhen Hu, Lubin Fan, Ligang Liu. Computer Graphics Forum (Proc. SGP), 2012 Presenter Yunhai@VCC
Single-Shape Segmentation [Shalfman et al. 2002] [Katz et al. 05] [Attene et. al 2006] [Lai et al. 08] K-Means Core Extraction Fitting Primitives Random Walks [Golovinskiy and Funkhouser 08] [Shapira et al. 08] [Golovinskiy and Funkhouser 08] Normalized Cuts Shape Diameter Function Randomized Cuts
Supervised Co-Segmentation • Limitations • Prior knowledge of the category • Shape variation within each category shall be small [Kalogerakis et al.10, van Kaick et al. 11] Input Mesh Labeled Mesh Head Neck Torso Leg Tail Ear Training Meshes
Unsupervised Co-Segmentation [Huang et al. 11] [Sidi et al.11]
Problem • Each feature descriptor generally has its own advantages and limitations. • However, existing methods concatenate all features into a higher dimensional descriptor AGD SDF
Pipeline Gaussian curvature Shape diameter function Average geodesic distance Shape contexts Conformal factor Feature descriptors Subspace clustering Over-segmentation with normalized cuts
Subspace • Let be a given set of points drawn from an unknown union of linear or affine subspaces of unknown dimensions • The subspaces can be described as
Subspace Sparse Representation • Each data point in a union of linear subspaces can always be represented as a linear combination of the points belonging to the same linear subspace. • To get a sparse linear combination>>minimizing the number of nonzero • In practice use:
Subspace Sparse Representation • Written in matrix form • To enforce the sparsity of the optimal solution
Sparse Subspace Clustering • Each entry of the matrix measures the linear correlation between two points in the dataset. We use this matrix to define a directed graph G = (V,E) • To make it balanced, we define the adjacency matrix • Cluster the graph with normalized cut
An example Matrix of sparse coefficients Similarity graph Data drawn from 3 subspaces
Multi-feature co-segmentation • Multi-feature penalty
Multi-feature co-segmentation • Multi-feature: penalty W1 W2 Wn
Clustering • Affinity matrix • Minimal curvature mc • Ncut clustering
Result The algorithm vs supervised approach 92.6% vs 96.1%
Result Too many labels
Result The algorithm vs unsupervised approach 94.4% vs 88.2%
Compared to Sidi et al. • Do not require the input model to have the same topologies • Can generate the satisfactory co-segmentation results from only a few models ??
Limitation • Only use the geometric properties to distinguish patches and classify them.