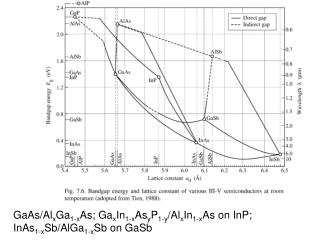
Download

1 / 6
60 likes | 192 Views
Generalized Linear Models 1. There is a response y and predictors x 1 ,…, x p. 2. y depends on the x’s through a l.c. h = b 1 x 1 +…+ b n x p. 3. The density of y is f(y i , q i , j ) = exp[A i {y i q i - g(q i )}/ j + t( y i , j /A i ) ]

E N D
Generalized Linear Models • 1. There is a response y and predictors x1,…, xp. • 2. y depends on the x’s through a l.c. h= b1x1+…+ bnxp. • 3. The density of y is • f(yi,qi,j) = exp[Ai{yi qi- g(qi)}/ j + t(yi ,j/Ai) ] • 4. Mean(y)=m =m(h), h=m-1(m) = l(m) : link function • j : scale parameter • 5. E(yi) = mi = g’(qi) and Var(yi) = g’’(qi) j/Ai Links and Variance Functions Family Link Variance binomial Logit: log(m/(1-m))m(1-m) poisson Log: log(m) m gaussian identity: m 1
Binomial Model: a trials with probability of success p. observe: y = s/a, s=#of successes. Then: Compare with: f(yi,qi,j) = exp[Ai{yiqi- g(qi)}/ j+ t(yi ,j/Ai) ] Ai=ai ; j=1; q=logit(p); g(q) =-log(1-p)=log(1+exp(q)) LogLik:
Poisson Model: log f(y)=y log(m)- m-log(y!) j=1; q=log(m); g(q) = m =exp(q) Compare with: f(yi,qi,j) = exp[Ai{yiqi- g(qi)}/ j+ t(yi ,j/Ai) ] Algorithm: Iterative Weighed Least Squares
Deviance Residuals: S: Saturated Model yiis estimated byq(yi) fromyi=g’(q(yi)) M: any non saturated model then the deviance of M with respect to S is DM= 2 S Ai{yiq(yi)- g(q(yi)} - Ai{yiqih- g(qih)} DM/j approx Chi-square with df=n-p Residuals: - Deviance: di=sign (yi-mi) | Ai{yiq(yi)- g(q(yi)} - Ai{yiqih- g(qih)}|0.5 - Response: yi-mih - Pearson: (yi-mih )/sqrt( Vi) - Working (yi-mih )/ ci where the denominator depends on the iteration Compare with: f(yi,qi,j) = exp[Ai{yiqi- g(qi)}/ j+ t(yi ,j/Ai) ]
options(contrasts = c("contr.treatment", "contr.poly")) x <- read.table("c:/flick.txt",head=T) Fl <- cbind(flick=x$flick, noflick=x$reps-x$flick) x.lg <- glm(Fl ~ morphine*del9, family = binomial,data=x) summary(x.lg, cor = F) plot(x$morphine,residuals.glm(x.lg,type="d")) plot(x$del9,residuals.glm(x.lg,type="d")) plot(predict(x.lg),residuals.glm(x.lg,type="d")) x.lg0 <- glm(Fl ~ log(1+morphine)*log(1+del9)-1, family = binomial,data=x) dose.p(x.lg0, cf = c(1,3), p = 1:3/4) dose.p(update(x.lg0, family = binomial(link = probit)), cf = c(1, 3), p = 1:3/4)
x <- (-5:5)/10 +0.3 p <- exp(0+1*x)/(1+exp(0+1*x)) y <- runif(11000) dim(y) <- c(1000,11) yy <- y; res <- NULL for(i in 1:11) yy[,i] <- y[,i] < p[i] for(i in 1:1000) res[i] <-coef(glm(yy[i,]~x,family=binomial))[2] ###Function f.cut ################################################# # Args: # p: vector of probailities that y=1 for each x. # y: vector of 0's and 1's with the response values. # Returns: list with components: # pred: vector of 0's and 1's with the predicted response # cutoff: value of the prob of 1 that decides # wether to predict a zero or a 1. # errors: Number of miscalssified observations or # prediction errors. f.cut <- function(p,y) { w <- unique(p); ww <-c(0,length(p)) for(i in 1:length(w)) if(ww[2]> sum((p> w[i])*(1-y)+(p<=w[i])*y)) ww<-c(w[i],sum( (p> w[i])*(1-y)+(p<=w[i])*y)) list(pred=(p>=ww[1])*1,cutoff=ww[1],errors=ww[2])}