Download
1 / 26
260 likes | 354 Views
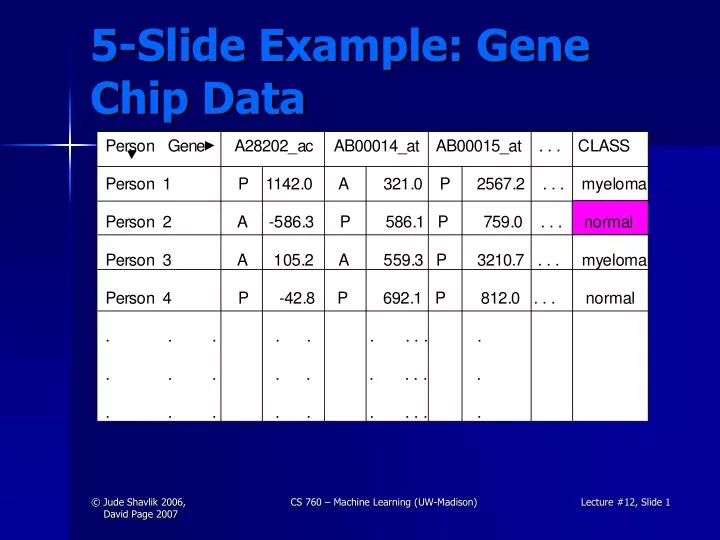
5-Slide Example: Gene Chip Data. Decision Trees in One Picture. Example: Gene Expression. Decision tree: AD_X57809_at <= 20343.4: myeloma (74) AD_X57809_at > 20343.4: normal (31) Leave-one-out cross-validation accuracy estimate: 97.1% X57809: IGL (immunoglobulin lambda locus).

E N D
5-Slide Example: Gene Chip Data CS 760 – Machine Learning (UW-Madison)
Decision Trees in One Picture CS 760 – Machine Learning (UW-Madison)
Example: Gene Expression Decision tree: AD_X57809_at <= 20343.4: myeloma (74) AD_X57809_at > 20343.4: normal (31) Leave-one-out cross-validation accuracy estimate: 97.1% X57809: IGL (immunoglobulin lambda locus) CS 760 – Machine Learning (UW-Madison)
Problem with Result Easy to predict accurately with genes related to immune function, such as IGL, but this gives us no new insight. Eliminate these genes prior to training. Possible of comprehensibility of decision trees. CS 760 – Machine Learning (UW-Madison)
Ignoring Genes Associated with Immune function Decision tree: AD_X04898_rna1_at <= -1453.4: normal (30) AD_X04898_rna1_at > -1453.4: myeloma (74/1) X04898: APOA2 (Apolipoprotein AII) Leave-one-out accuracy estimate: 98.1%. CS 760 – Machine Learning (UW-Madison)
Another Tree AD_M15881_at > 992: normal (28) AD_M15881_at <= 992: AC_D82348_at = A: normal (3) AC_D82348_at = P: myeloma (74) CS 760 – Machine Learning (UW-Madison)
A Measure of Node Purity Let f+ = fraction of positive examples Let f- = fraction of negative examples f+ = p / (p + n),f- = n / (p + n), p=#pos, n=#neg Under an optimal code, the information needed (expected number of bits) to label one example is Info( f+, f-) = - f+ lg (f+) - f- lg (f-) This is also called the entropy of the set of examples (derived later) CS 760 – Machine Learning (UW-Madison)
Another Commonly-Used Measure of Node Purity • Gini Index: (f+)(f-) • Used in CART (Classification and Regression Trees, Breiman et al., 1984) CS 760 – Machine Learning (UW-Madison)
-1 Info(f+, f-) : Consider the Extreme Cases • All same class (+, say) Info(1, 0) = -1 lg(1) + -0 lg(0) 0 • 50-50 mixture Info(½, ½) = 2[ -½ lg(½)] = 1 0 (by def) 0 1 I(f+, 1-f+) f+ 0 1 0.5 CS 760 – Machine Learning (UW-Madison)
Evaluating a Feature • How much does it help to know the value of attribute/feature A? • Assume Adivides the current set of examples into N groups Let qi = fraction of data on branch i fi+ = fraction of +’s on branch i fi - = fraction of –’s on branch i CS 760 – Machine Learning (UW-Madison)
Evaluating a Feature (con’t) E(A) Σ qi xI (fi+, fi-) • Info needed after determining the value of attribute A • Another expected value calc Pictorally N i= 1 A I (f+, f-) v1 vN I (fN+, fN-) I (f1+, f1-) CS 760 – Machine Learning (UW-Madison)
Info Gain Gain(A) I(f+, f-) – E(A) Our scoring function in our hill-climbing (greedy) algorithm Constant for all features So pick A with smallest E(A) That is, choose the feature that statistically tells us the mostabout the class of another example drawn from this distribution CS 760 – Machine Learning (UW-Madison)
Color Shape Size Class Red BIG + Blue BIG + Red SMALL - Yellow SMALL - Red BIG + Example Info-Gain Calculation CS 760 – Machine Learning (UW-Madison)
Info-Gain Calculation (cont.) Note that “Size” provides complete classification, so done CS 760 – Machine Learning (UW-Madison)
ID3 Info Gain Measure Justified(Ref. C4.5, J. R. Quinlan, Morgan Kaufmann, 1993, pp21-22) Definition of Information Info conveyed by message M depends on its probability, i.e., (due to Shannon) Select example from a set S and announce it belongs to class C The probability of this occurring is the fraction of C’s in S Hence info in this announcement is, by definition, CS 760 – Machine Learning (UW-Madison)
ID3 Info Gain Measure (cont.) Let there be Kdifferent classes in set S, the classes are: What is expected info from a msg about the class of an example in set S ? is the average number of bits of information (by looking at feature values) needed to classify a member of set S CS 760 – Machine Learning (UW-Madison)
Shape Circular Polygonal Handling Hierarchical Features in ID3 Define a new feature for each level in hierarchy, e.g., Let ID3 choose the appropriate level of abstraction! Shape 1 = {Circular, Polygonal} Shape2 = { , , , , } CS 760 – Machine Learning (UW-Madison)
7 9 5 11 13 Handling Numeric Featuresin ID3 On the flycreate binary features and choose best Step 1: Plot current examples (green=pos, red=neg) Step 2: Divide midway between every consecutive pair of points with different categories to create new binary features, eg featurenew1 = F<8 and featurenew2 = F<10 Step 3: Choose split with best info gain Value of Feature CS 760 – Machine Learning (UW-Madison)
F<10 T F F< 5 - T F + - Handling Numeric Features (cont.) Note Cannotdiscard numeric feature after use in one portion of d-tree CS 760 – Machine Learning (UW-Madison)
Student ID 1 999 99 1+ 0- 0+ 1- 0+ 0- Characteristic Property of Using Info-Gain Measure FAVORS FEATURES WITH HIGH BRANCHING FACTORS (i.e. many possible values) Extreme Case: At most one example per leaf and all I(.,.) scores for leafs equals zero, so gets perfect score! But generalizes very poorly (ie, memorizes data) CS 760 – Machine Learning (UW-Madison)
Fix: Method 1 Convert all features to binary e.g., Color = {Red, Blue, Green} From 1 N-valued feature to N binary features Color = Red? {True, False} Color = Blue? {True, False} Color = Green? {True, False} Used in Neural Nets and SVMs D-tree readability probably less, but not necessarily CS 760 – Machine Learning (UW-Madison)
Fix: Method 2 Find info content in answer to: What is value of feature A ignoring output category? fraction of all examples with A=i Choose A that maximizes: Read text (Mitchell) for exact details! CS 760 – Machine Learning (UW-Madison)
Color? Color? Y R G vsYvs … R vsBvs … G B Fix: Method 3 Group values of nominal features vs. • Done in CART (Breiman et.al. 1984) • Breiman et.al. proved for the 2-category case, optimal binary partition can be found be considering only O(N) possibilities instead of O(2N) CS 760 – Machine Learning (UW-Madison)
Multiple Category Classification – Method 1 (used in SVMs) Approach 1: Learn one tree (ie, model) per category Pass test ex’s through each tree What happens if test ex. is predicted to lie in multiple categories? To none? CS 760 – Machine Learning (UW-Madison)
Multiple Category Classification – Method 2 Approach 2: Learn one tree in total Subdivides the full space such that every pointbelongs to one and only one category (drawing slightly misleading) CS 760 – Machine Learning (UW-Madison)