Download

1 / 30
310 likes | 549 Views
Genetic Algorithm ,GA. Chuan-Yu Chang ( 張傳育 )Ph.D. Dept. of Electronic Engineering National Yunlin University of Science & Technology chuanyu@yuntech.edu.tw Office: ES709 Tel: 05-5342601 Ext. 4337. 簡介. GA 演算法是由 John Holland 於 1960 年代末期在密西根大學開始發展。

E N D
Genetic Algorithm ,GA Chuan-Yu Chang (張傳育)Ph.D. Dept. of Electronic Engineering National Yunlin University of Science & Technology chuanyu@yuntech.edu.tw Office: ES709 Tel: 05-5342601 Ext. 4337
簡介 • GA演算法是由 John Holland 於 1960 年代末期在密西根大學開始發展。 • 基因遺傳演算法(Genetic Algorithm)是一種模擬生物基因演化的搜尋演算法,其原理簡單的說就是達爾文的物競天擇,適者生存。 • 遺傳基因演算法其主要的目的為嚴謹地架構出自然生物系統的進化過程,藉由生物物種的基本運算子,在每代間進行演化,終而尋得適當問題的最佳解。 近來被廣泛的應用於搜尋各類問題的最佳解。
特色 • 遺傳的演算法則跟一般的最佳化方法所不同之主要特性分述如下 • 遺傳演算法的運算,主要在參數經過編碼的位元字串上,而非參數本身,所以在搜尋分析上不受參數連續性的限制。 • 遺傳演算法採用隨機多點同時搜尋的方式(複製→交配 →突變) ,而非傳統的單點依序搜尋方式,因此可以避免侷限在區域的最佳解上,而得到問題的最佳解上。 • 遺傳演算法則運算時只需訂定問題要求的目標函數(Objective function) ,並不需其他的的輔助資訊(如函數的微分性、連續性) ,所以適合各類問題的目標函數。
基本精神 用基因演算法求解最佳化的基本精神為: • 對於問題搜尋自然參數解的自然集合 • 將所要的參數編碼成一字串,隨機重複N個原始物種(字串),然後依據求解來得到適應函數(fitness function) • 適應高的函數被挑選到交配池,既複製的過程,在一交配及突變過程的運算下完成一代基因演算法則)如此重複下去以產生適應力最強的物種(最佳解)
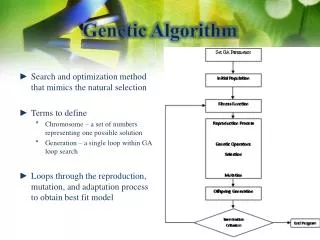
GA 的使用: • 在使用 GA 時有三個要點: • 1. 將問題的解表示成染色體 (chromosome) • 有時候我們所遇到的問題不是數字,例如許多城市的順序,氨基酸的組合等等。要如何以一串數字來表示一組合理的解,使得整個運算有效率並方便判讀。 • 2. 如何評斷每個個體的優劣 (fitness function) • 如何評估不同個體的好壞,如果問題中有明確的定義每組解的值,則這個部分很容易。但往往有很多問題沒有明確定義每組解的值,要如何列出一個式子來描述解空間對應到的值,將會影響到整個演算法的效能。 • 3. 運算子的實作 • 如何實作每一個運算,使得所得到的個體還是存在解空間中的。否則有可能演算法到最後得到的解,是不合理的。
GA 的演算法可以分為下列幾個步驟: • 1. 產生初始的族群 (initial generation) • 2. 產生子代 (reproduction) • i. 選擇一對適合繁殖的親代 • ii. 交配(crossover)產生一個新的個體 • iii. 此個體經過突變(mutation)成為子代 • 3. 計算整個每個個體的表現值(score) • 4. 選擇到達存活標準的個體(selection) • 5. 若整個族群滿足停止條件,則終止程式,輸出結果。否則回到步驟 2。
基因運算子(Genetic operators) • 一般而言,GA 有三種主要的運算子: • 選擇(selection) 、複製(reproduction) • 選擇哪些個體可以存活,或是選擇哪些個體可以產生子代,使得他的基因被保留在族群中。一般的作法是個體的分數越高,被選擇產生下一代的機率就越高。自然界也是強者會產生較多的子代,從另一個角度來看,弱者相對的被淘汰掉了。 • 交配(crossover) • 交配大致上可以分為兩種型態:離散型(discret),連續形(continuous)。若要交配的親代各為 A, B,則離散型的交配產生的子代 C,其染色體上的基因 Ci,不是 Ai 就是 Bi。而連續型的則會產生 Ci = Ai 和 Bi 的線性組合。選擇哪一個型態需視問題而定,且真正實作時有很多不同的變形。 • 突變(mutation)
基因運算子(Genetic operators) • 複製(reproduction): • 複製是依據每一物種的適應程度來決定下一代中應被淘汰或複製且保留的個數多寡的一種運算過程 • 複製過程有兩種形式:(a)輪盤式選擇(b)競爭式選擇 • 輪盤式選擇(roulette wheel selection) • 在每一代的演化過程中,首先依每個物種(字串)的適應函數值的大小來分割輪盤的位置,適應函數值越大的話,則在輪盤上佔有的面積比例也越大,每個物種在輪盤上佔有的面積比例越大代表被挑選到交配池中的機率越大,然後隨機選取輪盤的一點,其所對應的物種即被選入到交配池中。
基因運算子(Genetic operators) • 競爭式選擇(tournament selection) • 在每一代的演化過程中首先隨機地選取兩個或更多的物種(字串),具有最大適應函數值的物種即被選中送至交配池中。
基因運算子(Genetic operators) • 交配(crossover): • 交配運算式,依據交配率從一族群中隨機地任意兩個字元串,經彼此交換字元串的某些位元資訊而產生兩個新位元字串的一種過程,一般而言交配運算可以用: • 單點交配 • 雙點交配 • 均勻交配
基因運算子(Genetic operators) 單點交配 Y1Y2Y3Y4Y5Y6Y7Y8 X X1X2X3X4X5X6X7X8 Y 隨機選定一點,交叉互換 Y5Y6Y7Y8 X1X2X3X4 Y1Y2Y3Y4 X5X6X7X8 產生新的子代。 Y5Y6Y7Y8 X1X2X3X4 Y1Y2Y3Y4 X5X6X7X8
基因運算子(Genetic operators) • 突變(mutation): • 突變的過程是隨機的選取一物種的字串,並隨機選取突變點,並改變物種字串裡的位元資訊突變過程發生機率由突變機率所控制。 • 突變過程可以針對單一位元或對整個字串進行突變演算或以字罩突變方式為之,對於二進制的位元字串就是將字串的 0變1 , 1變成0 。
基因參數 (Genetic parameters): • 1.群體大小 (Population size, N): • 群體的大小代表著一次要搜尋多少個點;如果族群太小,則每次尋找的取樣不夠,很容易落到區域性最佳解中。但如果族群太大,則每一代的計算時間又太長。 • 2.互換率 (Crossover rate): • 即有多少子代是藉由親代交配而產生,而非只是單一個親代突變產生。通常互換的結果所產生的子代,往往落在較遠的地方,有助於幫助整個族群跳脫區域性最佳解。但如果互換太頻繁,則每一個新的落點附近還沒有搜尋過就又跳到別的地方,整個族群很難收斂。 • 3.突變率 (Mutation rate): • 每個基因突變的機率,太高的話,子代與親代相差太多,失去 local search 的意義。太低的話,整個族群演化的腳步又太慢。
編碼及解碼 二進位解碼 value:位元串所代表的值 Pmin : 參數值的最小值 Pmax :參數值的最大值 D : 位元串的十進位整數值 L : 位元串的長度
二近位編碼 • 編碼 轉成二進位 範例: x=1 y=2 z=4 ,x=00001 ,y=00010 ,z=00100
Matlab之基因演算 • genbin(bits,pop):利用隨機方式產生一初始族群。bits代表染色體長度,pop為族群大小。 • binvreal(newpop,a,b):轉換二進位制為實數值。newpop為新一代族群,a、b為區間範圍。 • selectga(fun,newpop,a,b):再製生產,字串依據合適值複製,所以在交配池內有較多之最合適的染色體有更高的機率。利用輪盤法選擇物種。fun為適應函數,newpop為新一代族群,a、b為區間範圍。 • fitness(fun,newpop,a,b):我們利用此函數計算其合適性。fun為適應函數,newpop為新一代族群,a、b為區間範圍。 • matesome(newpop,matenum):我們要匹配新的族群成員,此函數我們用來選擇部份成員來交配。newpop為新一代族群,matenum為交配率。 • mutate(newpop,mu):有時合適性並未增加,我們不能預期每次都有改進,所以在重覆相同步驟週期前我們完成一道突變手續。newpop為新一代族群,mu為突變率,切記莫過於太大。 • optga(fun,range,。bits,pop,gens,mu,matenum):此函數將所有步驟含在單一函數內。fun為適應函數,range為區間範圍,bits代表染色體長度,pop為族群大小,gens表示子代數,mu為突變率,matenum為交配率。
genbin(bits,pop):利用隨機方式產生一初始族群。bits代表染色體長度,pop為族群大小。genbin(bits,pop):利用隨機方式產生一初始族群。bits代表染色體長度,pop為族群大小。 方式1 f(x)=ex+sin(3πx) 我們定義上述函數為 f803 newpop=genbin(8,10) newpop = 1 1 0 0 0 0 0 1 0 0 0 1 1 0 0 1 0 0 1 1 1 0 1 0 1 1 1 1 0 1 0 1 1 1 1 1 0 1 1 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 1 1 0 1 0 0 1 1 1 0 1 0 1 0 1 0 1 0 0 0
selectga(fun,newpop,a,b):再製生產,字串依據合適值複製,所以在交配池內有較多之最合適的染色體有更高的機率。利用輪盤法選擇物種。fun為適應函數,newpop為新一代族群,a、b為區間範圍。selectga(fun,newpop,a,b):再製生產,字串依據合適值複製,所以在交配池內有較多之最合適的染色體有更高的機率。利用輪盤法選擇物種。fun為適應函數,newpop為新一代族群,a、b為區間範圍。 selpool=selectga('f803',newpop,0,1) selpool = 1 0 1 0 1 0 0 0 0 0 0 1 1 0 0 1 1 1 1 1 0 1 1 0 0 0 1 1 1 0 1 0 1 1 1 0 1 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 1 0 1 1 1 0 1 0 0 0 0 0 0 1 1 0 0 1 1 1 0 0 0 0 0 1
matesome(newpop,matenum):我們要匹配新的族群成員,此函數我們用來選擇部份成員來交配。newpop為新一代族群,matenum為交配率matesome(newpop,matenum):我們要匹配新的族群成員,此函數我們用來選擇部份成員來交配。newpop為新一代族群,matenum為交配率 newgen=matesome(selpool,0.6) newgen = 1 0 1 0 1 0 1 0 0 0 0 1 1 0 0 1 1 1 1 1 0 1 1 0 0 0 1 1 1 0 1 0 1 1 1 0 1 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 1 0 0 1 1 1 0 0 0 0 0 1
mutate(newpop,mu):有時合適性並未增加,我們不能預期每次都有改進,所以在重覆相同步驟週期前我們完成一道突變手續。newpop為新一代族群,mu為突變率,切記莫過於太大。mutate(newpop,mu):有時合適性並未增加,我們不能預期每次都有改進,所以在重覆相同步驟週期前我們完成一道突變手續。newpop為新一代族群,mu為突變率,切記莫過於太大。 newgen1=mutate(newgen,0.01) newgen1 = 1 0 1 0 1 0 1 0 0 0 0 1 1 0 0 1 1 1 1 1 0 1 1 0 0 0 1 1 1 0 1 0 1 1 1 0 1 0 0 0 1 0 1 0 1 0 0 1 0 0 0 0 0 0 1 0 1 1 0 0 0 0 0 1 0 0 0 1 1 0 0 1 1 1 0 0 0 0 0 1
fitness(fun,newpop,a,b):我們利用此函數計算其合適性。fun為適應函數,newpop為新一代族群,a、b為區間範圍fitness(fun,newpop,a,b):我們利用此函數計算其合適性。fun為適應函數,newpop為新一代族群,a、b為區間範圍 [fit,fitot]=fitness('f803',newgen1,0,1) fit = 1.9477 1.9010 2.9506 2.0957 3.2352 1.9032 1.0817 2.8829 1.9010 2.8829 fitot = 22.7819 [max,mostfit]=max(fit) max =3.2352 mostfit =5 xval=binvreal(newgen1(mostfit,:),0,1) xval =0.9098
方式2: optga(fun,range,。bits,pop,gens,mu,matenum):此函數將所有步驟含在單一函數內。fun為適應函數,range為區間範圍,bits代表染色體長度,pop為族群大小,gens表示子代數,mu為突變率,matenum為交配率。 [xval,max]=optga('f803',[0 1],8,10,1,0.01,0.6) chrom =0 0 1 0 0 1 0 0 1 0 1 0 1 1 0 0 0 0 0 0 1 1 1 0 1 0 1 1 0 0 0 1 0 0 1 0 1 1 0 0 1 1 0 0 0 0 1 0 0 1 1 1 1 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 0 0 0 1 0 0 0 xval = 0. 8941 max = 3.2855
討論: 比較方式一及二,我們發現數據有些小小的差距,其實兩個方式是一樣的,會產生如此現象,最主要是 • 我們初始值是採用隨機產生。只要我們計算代數越多,誤差的情況會越減少,不過,相對的所花費的時間也越多。 • 特別注意突變率不宜過大,會影響值的正確性。 • 基因演算法有兩個特徵︰交配互換基因和突變。通常基因演算法的執行速度較慢,但它可最佳應用至困難的問題,例如有多點最佳值,然而整體最佳值才是所需的。標準演算法在這時後常是失敗的,所以基因演算法花費較多時間是值得的。應注意每回執行基因點演算法皆產生不同的結果,因為程序的亂度特性
灰色建模︰ • 灰色建模(Grey Modeling)是灰色預測中相當重要的一部份,它利用原始數列作累加生成(Accumulate Generating Operation)後,開始的數列以較規則的形式呈現,在針對累加生成後所產生的數列,以近似的微分方程,來進行建模。 • 傳統的GM(1,1)模型是以一般的微分方程作基礎,求出模型的解,而模型的待定係數則是以統計回歸分析中的最小平方法(Least Square Method)來分析,此一方法使用的預設前提是需要大量的取樣樣本,方能對參數作有效的預估,但是灰色預測建模通常只使用極少的數據,如此將造成建模時產生極大的誤差。且當建模數據成單調遞增或遞減分布時,傳統灰色預測建模相當準確,並能做有效的預測,但對於跳動的數據或是數據中隱含的若干不規律,以傳統的方式建模,誤差則相當大。 • 為改善此情形,以最佳化的方法改善建模的誤差,但其最後的模型待定係數a、b是以最小平方法求得。
範例︰ 範例一 原始數列 x(0)=(10,30,35,60,65) 累加數列 x(1)=( 40,75,135,200) • 傳統GM(1,1): 模型參數解 GM(1,1)模型響應表示式 表為傳統GM(1,1)模型經累減生成後與實際值所做的比較。 GM(1,1,)建模值與實際值之比較
遺傳演算法求GM(1,1)模型: [arfa fit]=optga('f800',[0 1],10,10,100,0.01,0.9) arfa = 0.5191 fit =0. 0732 f800(0.5191) a1 = -0.2585 23.6855 • 模型參數解 • GM(1,1)模型響應表示式 • 表為遺傳演算法所設計之最佳化GM(1,1)模型經累減生成後與實際值所做的比較。
討論︰ • 我們使用基因演算法作GM(1,1)建模,主要是利用基因演算的特性。因其比較不會受限於局部最佳解,較易找出多點之最佳值,我們可利用找出之多點最佳值再去找出最佳解,因我們可從多點值之中找出最佳值之坐落位置,再縮小範圍求得最佳解。不過,有幾點需特別注意。首先,我們撰寫適應函數時,應注意矩陣之次項,否則會發現程式無法執行,通常很容易發生,而且不易發現問題所在。再者,當我們執行程式時,因基因演算法之第一步驟為產生一隨機子代,所以每次求得之值並不相同,並不一定就是我們要的答案,我們必須多執行幾次找出最佳者。最後,再程式中之突變率需依代數的長短來決定,基本上,代數越長突變率就不需太大,否則易將把求得之最佳解再次突變,不過還是視情況而定。