Download

1 / 36
360 likes | 585 Views
A Gene Expression Project. Richard Mott Wellcome Trust Centre for Human Genetics. Project Summary. Gene Expression Analysis Comparison with phenotypes Gene Ontology Analysis Comparison between tissues Gene Coexpression Networks

E N D
A Gene Expression Project Richard Mott Wellcome Trust Centre for Human Genetics
Project Summary • Gene Expression Analysis • Comparison with phenotypes • Gene Ontology Analysis • Comparison between tissues • Gene Coexpression Networks • NB: There are many R packages available from CRAN for gene expression and network analysis, which are not covered in this lecture. • You should explore them!
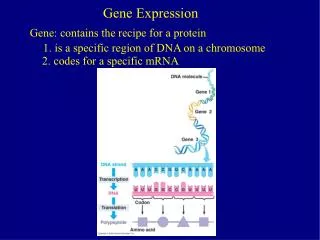
Gene expression datasets • Hippocampus (460 mice), • Liver and Lung (260 mice) • 100 Phenotypes • Mice are from a Heterogeneous Stock, from 164 families
Gene Expression data • Gene expression measured on Illumina Mouse arrays • 47000 50-mer probes • Approx 2 probes per gene • Covariates (eg Sex, Family) also available • > load("liver.exp.RData") • > load("liver.cov.RData") • > source("expression.tutorial.R")
Exploring Expression Data > liver.median <- apply(liver.exp, 2, median ) > hist(liver.median, breaks=50) > liver.subset <- liver.exp[,liver.median>6]
Sex Effects • Which transcripts have different expression levels for the two sexes? • Use a T-test on each transcript • The R apply() function speeds up the analysis • First define a function tfunc that performs the T test and reports the P-value • tfunc <- function( X, GENDER ) { tt <- t.test( X ~ GENDER ); return(tt$p.value) } • Then compute the test for each transcript • > sex.pvalue <- apply(liver.subset, 2,tfunc, liver.cov$GENDER ) • Then plot the distribution of p-values • > hist( sex.pvalue, breaks=50) • >sum(sex.pvalue<1.0e-5) • [1] 78
Sex Effects 312/2796 (11%) of transcripts with median level > 6 have sex effects with P < 0.01 78/2796 (2%) of transcripts with median level > 6 have sex effects with P < 0.00001
Family effects (Heritability) • Which transcripts are affected by genetic background? • Use one-way ANOVA wrapped inside apply() • First define a function to return the p-value of the ANOVA: • anova.pvalue <- function( X, factor ) { • a <- anova(lm( X ~ factor)) • return(a[1,5]) • } • Then find the transcripts with high heritability • family.pvalue <- apply( liver.subset, 2, anova.pvalue, liver.cov$Family )
Family Effects 18% of transcripts with median level >6 have heritability p-value < 0.01 0.2% of transcripts with median level >6 have heritability p-value < 0.00001
Body Weight • We can find transcripts associated with body weight in a similar fashion to family effects, except that linear regression is used. • Note that the direction of causality is no longer certain, ie it is not clear whether variation in a transcript is causative for variation in weight or vice versa > weight.pvalue <- apply( liver.subset, 2, anova.pvalue, liver.cov$EndNormalBW ) > hist(weight.pvalue,breaks=50)
Body Weight 11% of transcripts with median levels > 6 are significant at P < 0.01 1.5% of transcripts with median levels > 6 are significant at P < 0.00001
What do the genes do? • So far we have identified sets of genes which are associated with sex, family and weight • How can we characterise these genes ? • One popular method is to test if the annotations of these genes have unusual features. • Annotations include: • genome location • protein domain architecture (eg from INTERPRO) • gene function, where known (eg from GO) • From a statistical perspective, is is importation that a controlled vocabulary (ontology) is used to describe gene functions. • The analysis then does not have to understand any biology!!
The Gene Ontology (GO)http://www.geneontology.org/ • GO associates a set of GO-terms with every gene, describing aspects of the gene’s known function. • It has become a very popular tools for automated investigation of large sets of genes. • But note that: • GO is not complete, covering only biological processes, cellular components and molecular functions. Other ontologies are also important. • many genes have no known function
GO annotation Examples GO:0000001 mitochondrion inheritance GO:0000002 mitochondrial genome maintenance GO:0000003 reproduction GO:0000005 ribosomal chaperone activity GO:0000006 high affinity zinc uptake transporter activity GO:0000007 low-affinity zinc ion transporter activity GO:0000008 thioredoxin GO:0000009 alpha-1,6-mannosyltransferase activity GO:0000010 trans-hexaprenyltranstransferase activity GO:0000011 vacuole inheritance GO:0000012 single strand break repair ENSMUSG00000061404 Olfr936 GO:0001584 GO:0016020 GO:0007600 GO:0007166 GO:0004930 GO:0031224 GO:0003674 GO:0005623 GO:0050896 GO:0016021 GO:0004888 GO:0004871 GO:0050877 GO:0007582 GO:0005575 GO:0007186 GO:0007608 GO:0007165 GO:0004872 GO:0007154 GO:0044464 GO:0044425 GO:0004984 GO:0007606 GO:0050874 GO:0009987 GO:0051869 GO:0008150 ENSMUSG00000030105Arl8b GO:0016043 GO:0007046 GO:0051233 GO:0005737 GO:0016817 GO:0044424 GO:0048487 GO:0005515 GO:0016787 GO:0043014 GO:0005623 GO:0007028 GO:0044422 GO:0044237 GO:0007242 GO:0043228 GO:0005856 GO:0007582 GO:0008152 GO:0007165 GO:0015630 GO:0008092 GO:0019003 GO:0016462 GO:0005622 GO:0044464 GO:0007154 GO:0003824 GO:0006139 GO:0006364 GO:0005488 GO:0003924 GO:0043170 GO:0016818 GO:0019001 GO:0009987 GO:0005525 GO:0008150 GO:0017076 GO:0043229 GO:0006396 GO:0016072 GO:0007059 GO:0043232 GO:0050875 GO:0044430 GO:0043283 GO:0044446 GO:0030496 GO:0015631 GO:0003674 GO:0042254 GO:0007264 GO:0000166 GO:0005819 GO:0017111 GO:0044238 GO:0043226 GO:0016070 GO:0005575 GO:0006996 ENSMUSG00000042428Mgat3 GO:0016020 GO:0008375 GO:0043413 GO:0005615 GO:0044421 GO:0005737 GO:0031224 GO:0044267 GO:0044424 GO:0008194 GO:0009058 GO:0005623 GO:0044422 GO:0044237 GO:0007582 GO:0008152 GO:0044425 GO:0005622 GO:0044464 GO:0003824 GO:0044431 GO:0003830 GO:0043227 GO:0043170 GO:0019538 GO:0006487 GO:0009059 GO:0006412 GO:0009987 GO:0016740 GO:0008150 GO:0043229 GO:0006486 GO:0009101 GO:0050875 GO:0016758 GO:0043283 GO:0044446 GO:0005795 GO:0003674 GO:0009100 GO:0016021 GO:0005576 GO:0044238 GO:0044249 GO:0043226 GO:0043231 GO:0005575 GO:0044260 GO:0016757 GO:0006464 GO:0005794 GO:0043412GO:0044444
Testing for GO association • Set of genes G is classified into two groups eg by sex • A given GO annotation term classifies the genes into two groups (present, absent) • The data are a 2x2 contingency table classified by sex and GO, and the test of GO/sex association can be done either by a chi-squared test or by Fisher’s Exact Test FET, or a generalised linear model with Poisson link function. • The most popular methods use the FET, which can be calculated quickly using the hypergeometric distribution, and is exact even when the counts of data are small
Testing for GO association • Read in a file of GO terms associated with each Ensembl Mouse gene (this set has been reduced to include only those GO terms present in more than 1% of genes) go1 <- read.delim("GO.Ensembl.01.txt") > dim(go1) [1] 19988 387 • Find the common transcripts between liver.subset and the annotations, and those transcripts with sex p-values < 0.01 > intersect <- colnames(liver.subset)[match(go1$transcript, colnames(liver.subset), nomatch = 0)] > intersect <- unique(sort(intersect))
Testing for GO association > liver.subset.intersect <- liver.subset[, match(intersect, colnames(liver.subset))] > dim( liver.subset.intersect) [1] 275 1650 > go.intersect <- go1[match(intersect,go1$transcript),] > dim(go.intersect) [1] 1650 388 > sex.ids <- colnames(liver.subset)[sex.pvalue<0.01] > sex.intersect <- sex.ids[match(sex.ids,intersect,nomatch=0)] > length(sex.intersect) [1] 174 > sex.idx <- go.intersect$transcript %in% sex.ids
Testing for GO Association using apply() and fisher.test() • fisher.func <- function( X, sex.idx) { X <- as.factor(X) ; if ( nlevels(X) == 2 ) {f <- fisher.test(X, sex.idx); return (f$p.value)} else return(1) } • > fish <- apply( go.intersect[,4:ncol(go.intersect)], 2, fisher.func, sex.idx ) • > length(fish) • [1] 385 • > fish[fish < 0.01] • GO.0000267 GO.0002376 GO.0003735 GO.0005624 GO.0005783 GO.0005840 • 5.255498e-03 6.142841e-04 9.096193e-03 4.108839e-04 1.153113e-03 9.125263e-03 • GO.0006412 GO.0006955 GO.0009058 GO.0009059 GO.0016740 GO.0016788 • 9.852476e-05 4.726468e-05 7.243732e-03 4.532035e-05 3.915276e-03 4.224464e-03 • GO.0030529 GO.0043170 GO.0043234 GO.0044249 GO.0044422 GO.0044446 • 2.250219e-03 2.157644e-03 5.039780e-04 2.347306e-04 2.360906e-03 2.360906e-03 • <length(fish[fish < 0.01]) • [1] 18
Significant GO terms > data.frame( pvalue=fish[fish<0.01], desc=as.character(go2name$desc[go2name$go %in% names(fish[fish<0.01])])) pvaluedesc GO.0000267 5.255498e-03 cell fraction GO.0002376 6.142841e-04 immune system process GO.0003735 9.096193e-03 structural constituent of ribosome GO.0005624 4.108839e-04 membrane fraction GO.0005783 1.153113e-03 endoplasmic reticulum GO.0005840 9.125263e-03 ribosome GO.0006412 9.852476e-05 protein biosynthesis GO.0006955 4.726468e-05 immune response GO.0009058 7.243732e-03 biosynthesis GO.0009059 4.532035e-05 macromolecule biosynthesis GO.0016740 3.915276e-03 transferase activity GO.0016788 4.224464e-03 hydrolase activity, acting on ester bonds GO.0030529 2.250219e-03 ribonucleoprotein complex GO.0043170 2.157644e-03 macromolecule metabolism GO.0043234 5.039780e-04 protein complex GO.0044249 2.347306e-04 cellular biosynthesis GO.0044422 2.360906e-03 organelle part GO.0044446 2.360906e-03 intracellular organelle part
Comparing gene expression across experments • We sometimes want to compare expression levels between experiments • In different tissues in the same individuals • At different time points or under different experimental conditions with genetically identical individuals • Inbred lines • Cell lines • Comparisons may be done • At the level of the individual • Across the population
Comparing gene expression across tissues • A common set of individuals are used for two tissues (eg liver, lung) • Look for transcripts whose expression levels across samples between the tissues are correlated samples Lung transcripts Liver transcripts
An efficient way to do the computation in R Liver transcripts Process each column in the combined matrix using apply() samples Lung transcripts
Comparing gene expression across tissues > load(“lung.liver.exp”) # CONTAINS lung and liver stacked vertically > lung.liver <- c(rep( TRUE, 262), rep(FALSE, 262) > lung.liver.cor.pvalue <- apply( lung.liver.exp, 2, function( X, by ) { f <- cor.test(X[by], X[!by]); return f$pvalue }, by=lung.liver ) > hist(-log10(lung.liver.cor.pvalue),breaks=50) > lung.liver.cor.logP <- -log10(lung.liver.cor.pvalue) > sum( lung.liver.cor.logP> 2)/47429 [1] 0.0837884 > sum( lung.liver.cor.logP> 3)/47429 [1] 0.04374960 > sum( lung.liver.cor.logP> 4)/47429 [1] 0.02791541 > sum( lung.liver.cor.logP> 5)/47429 [1] 0.01906007 >
GO associations of transcripts with correlated expression between liver and lung • General-purpose function for testing GO associations • genes is a vector of the transcript names under consideration • classification is a boolean vector the same length as genes, indicating which transcripts are in the classification • go is a matrix where go[transcript,Goterm] = TRUE if Goterm is attached to transcript • go2name is a data frame with the descriptions of the Go terms > GO.analysis <- function( genes, classification, go, go2name ) { intersect <- unique(sort(genes[match(go$transcript,genes,nomatch=0)])) go.intersect <- go[match(intersect,go$transcript),] classification.intersect <- classification[match(classification,intersect,nomatch=0)] class.idx <- go.intersect$transcript %in% genes[classification] fish <- apply( go.intersect[,4:ncol(go.intersect)], 2, fisher.func, class.idx) fish <- fish[names(fish) %in% go2name$go] r <- order(fish) return( data.frame( p.value=fish, desc=go2name$desc[match(go2name$go, names(fish2[r]), nomatch=0)])) }
Many very significant GO terms > fish <- GO.analysis( colnames(lung.liver.exp), lung.liver.cor.logP> 4, go1, go2name ) > head(fish$pvalue,n=20) GO.0001584 GO.0004930 GO.0004888 GO.0004984 GO.0007186 GO.0043231 2.577931e-18 3.011990e-17 3.477225e-14 2.396701e-13 1.138140e-12 1.838885e-12 GO.0043227 GO.0044424 GO.0005622 GO.0007166 GO.0043229 GO.0043226 2.572202e-12 1.000009e-11 2.866695e-11 6.100367e-10 6.792908e-10 6.806115e-10 GO.0005737 GO.0004872 GO.0004871 GO.0044444 GO.0007582 GO.0043170 2.648800e-08 3.289317e-08 5.339634e-08 7.805342e-08 9.355738e-08 1.049470e-07 GO.0005634 GO.0050875 4.469984e-07 4.844296e-07
Biological Processes coordinated between liver and lung • GO.0001584 2.577931e-18 • GO.0004930 3.011990e-17 • GO.0004888 3.477225e-14 • GO.0004984 2.396701e-13 • GO.0007186 1.138140e-12 • GO.0043231 1.838885e-12 • GO.0043227 2.572202e-12 • GO.0044424 1.000009e-11 • GO.0005622 2.866695e-11 • GO.0007166 6.100367e-10 • GO.0043229 6.792908e-10 • GO.0043226 6.806115e-10 • GO.0005737 2.648800e-08 • GO.0004872 3.289317e-08 • GO.0004871 5.339634e-08 GO.0001584 bud site selection GO.0004930 activation of MAPKK activity during cell wall biogenesis GO.0004888 C-8 sterol isomerase activity GO.0004984 protein import into nucleus, translocation GO.0007186 shmoo orientation GO.0043231 nuclear interphase chromosome GO.0043227 isoleucine/valine:sodium symporter activity GO.0044424 cytoplasmic interphase chromosome GO.0005622 spliceosomal catalysis GO.0007166 inactivation of MAPK (pseudohyphal growth) GO.0043229 second spliceosomal transesterification activity GO.0043226 mitochondrion inheritance GO.0005737 re-entry into mitotic cell cycle GO.0004872 sulfite transport GO.0004871 organellar small ribosomal subunit >
Mapping expression Quantitative Trait Loci (eQTL) • eQTL are Genetic loci at which genotype variation is associated with variation in a transcript • cis eQTL co-localise with the correaponding gene’s position • trans eQTL map to other locations in the genome • Many transcripts have cis eQTL as well as trans eQTL • hubs are loci that contain many trans eQTL, indicating sets of genes under the same control • Basic principle of mapping any quantitative trait is to determine the association between the phenotype and each genotyped SNP • anova(lm( transcript ~ genotype))
A simple eQTL mapping programme Data: transcript is a matrix of transcript levels (columns), genotypes is a matrix of genotypes (columns) The rows are the subjects, which must be identical across the two matrices >load(“g19.RData”) >load(“liver.19.exp.RData”) > map.eqtl <- function( transcript, genotypes ) { logP = -log10(apply( genotypes, 2, function( X, transcript ) { X <- as.factor(X) ; if ( nlevels(X) > 1 ) { a <- anova(lm( transcript ~ X )); return(a[1,5])} else return(1)}, transcript)) return(logP) } > map.eqtls <- function( genotypes, transcripts ) { genos <- data.frame(genotypes[,2:ncol(genotypes)]) logP <- apply( transcripts, 2, map.eqtl, genos ) rownames(logP) <- colnames(genos) colnames(logP) <- colnames(transcripts) return(logP) } logP <- map.eqtls( g19, liver.19.exp[,c(20346,29095)]) # map transcripts 29095 = "LIVER.express.scl074170.1_145.S" 20346 = "LIVER.express.scl0023972.1_63.S"
Example chromosome scans LIVER.express.scl074170.1_145.S LIVER.express.scl0023972.1_63.S
Different Types of Association Analysis • SNP genotypes G take three possible values AA, AB, BB • Under an additive genetic model, the phenotypic effect of a genotype is proportional to the number of A alleles (or equivalently B alleles) • we recode the genotype as a number X <- additive(G) • BB = 0, • AB = 1 • AA = 2 • Under a dominant genetic model, the phenotypic effect is zero unless an A allele is present (or vice-versa) • we recode the genotype as a number X <- dominance(G) • BB = 0, • AB = 1 • AA = 1 • Under a full genetic mode, the phenotypic effect of each genotype is arbitrary • Note that a full model is the sum of the additive and dominance models • phenotype ~ G • phenotype ~ additive(G) + dominance(G)
R functions for converting full genotypes to submodels additive <- function( G ) { G <- as.factor(G); G <- reorder( G, sort(levels(G)) return(as.numeric(G) } dominance <- function(G) { a <- additive(G) return(ifelse(a>0,1,0)) }