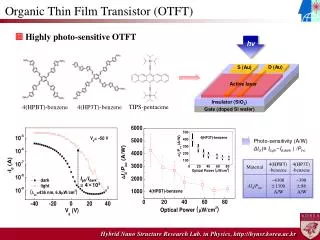
Download

1 / 18
180 likes | 385 Views
Bioinformatics and Computational Molecular Biology (Fall 2005): Representation. PatternHunter II: Highly Sensitive and Fast Homology Search. Ming Li, Bin Ma Derek Kisman, John Tromp. R94922059 林語君. Overview. Homology search Local alignment algorithms PH I PH II Multiple Spaced Seeds

E N D
Bioinformatics and Computational Molecular Biology (Fall 2005): Representation PatternHunter II: Highly Sensitive and Fast Homology Search Ming Li, Bin Ma Derek Kisman, John Tromp R94922059 林語君
Overview • Homology search • Local alignment algorithms • PH I • PH II • Multiple Spaced Seeds • Computing hit probability • Finding a good seed set • PH II Design • Performance
Local alignment • Smith-Waterman • Smith and Waterman, 1981; Waterman and Eggert, 1987 • SSearch • FastA • Wilbur and Lipman, 1983; Lipman and Pearson, 1985 • BLAST • Altschul et al., 1990; Altschul et al., 1997 • Blast Family: BLASTN, BLASTP, etc. • MEGABLAST
PatternHunter • Seed • Tradeoff: sensitivity <-> computation • Consecutive k letters • k=11 in Blastn, k=28 in MegaBlast • Nonconsecutive k letters • Spaced seed • A model of k as its weight
PatternHunter II • Genome Informatics 14 (2003) • Extend single optimized spaced seed of PH to multiple ones • Speed: BLASTN (MEGABLAST) • Sensitivity: Smith-Waterman (SSearch)
Definition • A homologous region, R • A seed hitsR • A seed set A={a1,…ak} hits R • Similarity • R has p=x% identities • Sensitivity • Hit probability • Optimal (DP) = 1
Computing Hit Probability • NP-hard on multiple seeds • DP on 1 seed • Extend DP to multiple seeds
Computing Hit Probability of Multiple Seeds • Let A={a1,…ak} be a set of k seeds and R a random region of Length L with similarity level p. • Binary string b is a suffix of R[0:i] • Answer: f ( L,Є ), Є= empty string
Finding a Good Seed Set • NP-hard for both optimal seed and multiple seeds • Greedy
Finding a Good Seed Set • Compute the 1st seed a1 which maximizes the hit probability of {a1} • Compute the 2nd seed a2 which maximizes the hit probability of {a1, a2} • Repeat until • Reach the desired number of seeds • Reach the desired hit probability
Finding a Good Seed Set • May not optimize the combined hit probability • Good enough • Optimal • 16 weight, 11 seeds, L=64, similarity=70%, first four seeds:{111010010100110111,111100110010100001011,110100001100010101111,1110111010001111} • Greedy • 16 weight, 12 seeds, L=64, similarity=70%, first four seeds:{111010010100110111,1111000100010011010111,1100110100101000110111,1110100011110010001101}
Performance of the seeds • From low to high • Solid: weight-11 k=1,2,4,8,16 seeds • Dashed: 1-seed, weight=10,9,8,7
Performance of the seeds • Reducing the weight by 1 • Increase the expected number of hits by a factor of 4 • Doubling the number of seeds • Increase the expected number of hits by a factor of 2 • Better: Multiple seeds
PH II Performance • Compare with Blast(Blastn), Smith-Waterman(SSearch) • Sensitivity of SSearch = 1 • Alignment score • BLAST methods (hash, DP) • match=1, mismatch=-1, gapopen=-5, gapextension=-1
PH II Performance • From low to high • Solid: PH II, 1, 2, 4, 8 seeds weight 11 • Dashed: Blastn, seed weight 11
Complexity Proof • Finding optimal spaced seeds • NP-hard • Finding one optimal seed • NP-hard • Computing the hit probability of multiple seeds • NP-hard