Download

1 / 26
260 likes | 269 Views
FastVDO Unified 16-Bit Framework. Pankaj Topiwala FastVDO LLC Columbia, MD 21046 USA pnt@fastvdo.com JVT-B103. In the Beginning (April 01). April 01 – FastVDO showed how H.26L can be made fully 16-bit with no loss of performance (M16). At SB 4 other proposals also supported 16-bits

E N D
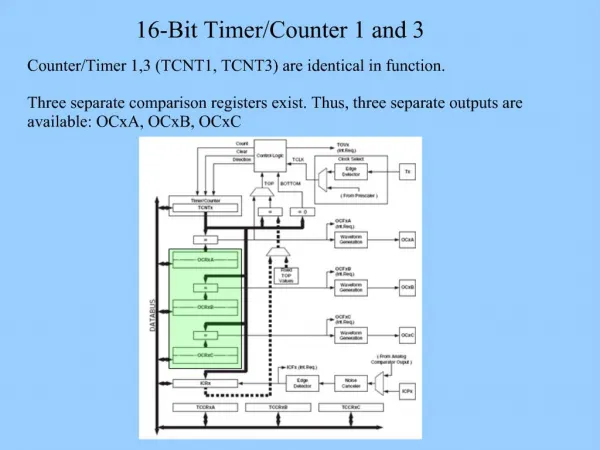
FastVDO Unified 16-Bit Framework Pankaj Topiwala FastVDO LLC Columbia, MD 21046 USA pnt@fastvdo.com JVT-B103
In the Beginning (April 01) • April 01 – FastVDO showed how H.26L can be made fully 16-bit with no loss of performance (M16). • At SB 4 other proposals also supported 16-bits • Key lessons learned • Negligible performance or complexity difference • Quantization is very flexible! TI/Sharp showed that it can be manipulated to make even the tml transform into 16-bits • Quant. memory rqmts can be minimized by periodicity • Proper focus – the transform – which can limit applications • Quantization can be safely decoupled
Rapid Growth of Applications • But the application space of H.26L is growing: • low-rate wireless conversational (28 kb/s – 256 kb/s), • mid-rate streaming, VOD (64 kb/s – 1 Mb/s) • high-rate TV broadcasting (1- 4 Mb/s) • high-rate storage for future DVD (5-30 Mb/s) • Multirate digital cinema (mid-rate, visually lossless distribution, and lossless archive: 30 Mb/s, 200 Mb/s, and low Gb/s) • ultra-high rate HDTV (30 Mb/s – low Gb/s) • lossless medical (similar) • Entertainment applications poised to dominate.
Desire • One framework that fits all applications • Reduce fragmentation of standard • Limit proliferation of inconsistent technologies • Improve interoperability between profiles • Significantly improve content reuse • FastVDO introduced such a framework • Still inadequately understood • Will now explain concretely
Motivation • Similar coding performance as the DCT • Supporting a 16-bit (or less) architecture • Low complexity, multiplierless implementation (adds, right shifts) • Invertible integer-to-integer mapping • In-place computation
DCT • Coding gain: 7.57 dB; Complexity: 8 adds, 6 mults in floating point • Integer approximation:
Generic 4-Pt Lifting Transform e f b c d Note: If a – u are dyadic rationals, then this - is exactly invertible! - has a mult-free def, multiple ways, and - is very stingy in bit expansion!
e f b c d Example 1: FastVDO X1 - Hadamard a=u=1/2; b=c=d=e=f=p=1. Three equivalent implementations - matrix multiply - mult-free direct (8 adds, 0 scalings) - lifting (also mult-free: 8a 2s)
e f b c d Example 2: FastVDO X2 a=1/2; b=c=d=e=f=1, u=p=-1. Three equivalent implementations - matrix multiply - mult-free direct (8 adds, 1 scalings) - lifting (also mult-free: 8a 1s)
e f b c d Example 3: FastVDO X3 a=1/2; b=c=d=e=f=1, p=-2,u=2/5. W.K.Cham, 1989. X3 proposed by MS, Nokia. Non-dyadic numbers mean Non-invertible transform. Three equivalent implementations - matrix multiply - mult-free direct (8 adds, 2 scales) - lifting (but with mults!! – or approx. u)
e f b c d Example 4: FastVDO X4 a=p=u=1/2; b=c=d=e=f=1. Note: High Coding Gain CG(X4) = 7.55 dB CG(DCT) = 7.57 dB Three equivalent implementations - matrix multiply - mult-free direct (9 adds, 2 scalings) - lifting (also mult-free: 8a 3s)
e f b c d Example 5: FastVDO X5 a=1/2; b=c=d=e=f=1, p=7/16, u=3/8. Note: High Coding Gain CG(X5) = 7.57 dB CG(TML) = 7.57 dB CG(DCT) = 7.57 dB Three equivalent implementations - matrix multiply - mult-free direct (9 adds, 7 scales) - lifting (also mult-free: 10a 5s)
x[0] Y[0] >>1 x[1] Y[2] x[2] Y[3] >>1 >>3 >>1 >>4 x[3] Y[1] Detailed Implementation of X5
1 2 3 4 Previous Integer DCT p 7/16 3/8 1/2 1/2 - - u 3/8 3/8 3/8 1/2 - - # adds 10 10 9 8 8 (16) 8 # shifts 5 5 4 3 0 (8) 0 # mults 0 0 0 0 6 (0) 6 CG in dB 7.57 7.56 7.55 7.55 7.57 7.57 Performance-Complexity
8 x 8 BinDCT Coding gain: 8.77 to 8.82 dB for AR(1) process with p=0.95
16 x 16 BinDCT Coding gain: 9.4499 dB for AR(1) process with p=0.95
Lessons Learned • All transforms considered fall under our rubric (other than tml) • No new transforms introduced in 9 months • Growing app. list needs transform innovation • Quantization is very flexible • Innovations have in fact been made in quantization • Sharp/TI showed that even tml can be made 16-bits • Quantization can be adapted to transform
Lessons Learned (2) - TML • TML transform • OK for low-complexity, wireless app. using fixed hard-wired architectures that need matrix multiply • But unfriendly integers not good for ASIC • Not optimized for bit preservation, high-rate apps. • Not invertible • Not generalizable to larger transforms • Satisfies one transform method only – direct matrix multiply
Lessons Learned (3) - Cham • OK for matrix and mult-free applications • Notionally adds 6 bits in forward transform • Needs truncation for higher-bit data • Likely penalty for high-rate, high-bit sources • Testing on high-bit data critical • Is not invertible (lifting not dyadic rational) • Does not generalize to higher transforms • Satisfies 2 (of 3) transform methods
Relative Merits • General Comparisons • All contenders match current 32-bit performance • All offer reduced, nearly identical complexity • Unique Advantages • General framework to address broad range of needs • Very tight bit control • Demonstrated 16-bits output for 12-bit input, no truncation • Suitable for higher-bit data, and high rates • Related designs for higher sizes (8-pt, 16-pt) • Advantages of lifting improve further with size
Currently No Concensus • First address the low-complexity, low-rate problem • Consider high-rate problem later, probably with a different transform • If lossless is needed, probably a 3rd transform • Energy misdirected to date • Some proponents backed single transforms, assumed original • Tests for performance, complexity metrics – inconclusive • Missing the bigger picture – support a wide variety of apps • Our vision – use a single framework if possible • Going forward – focus on our individual strengths
Recommendations • Transform and Quantization can be decoupled • Adopt the framework • Prefer downloadable filters • Innovate in the transforms, goal of 3 transform methods • Finalize in the reflector, adopt in May • Tailor transform to wide variety of applications • Transform Activity can work directly in conjunction with other groups (e.g., Trans. Size, ABT, Interlace, Quantization, …) • Quant can focus on transform adaptation, finer quantization, periodicity, etc.
Recommendations (2) • Focus transforms on high-quality, high-rate • Low-complexity case well understood • High-rate apps just emerging in JVT • Streaming, VOD • Broadcast (interlaced) • Film • Storage (DVD) • Higher block sizes • Review ABT options • Digital Cinema -- we have data • Look for synergies with low-complexity case