Download

1 / 47
470 likes | 616 Views
Optimización Global Usando Ensamblaje de Modelos. Universidad del Zulia Facultad de Ingeniería Instituto de Cálculo Aplicado. Prof. Daniel Ernesto Finol González. Maracaibo, 5 de Noviembre de 2007.

E N D
Optimización Global Usando Ensamblaje de Modelos Universidad del Zulia Facultad de Ingeniería Instituto de Cálculo Aplicado Prof. Daniel Ernesto Finol González Maracaibo, 5 de Noviembre de 2007
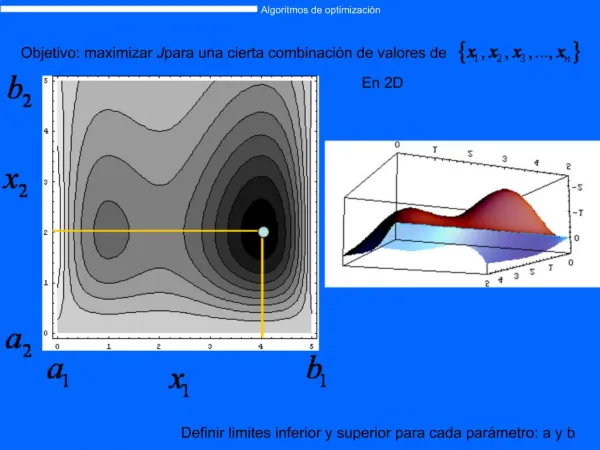
En distintas industrias es frecuente la necesidad de optimizar funciones de las cuales sólo se conoce (o puede conocerse) una cantidad limitada de evaluaciones. El proceso de optimización requiere muchas evaluaciones. Justificación del Estudio
Se debe construir un modelo que aproxime la función a partir de unas pocas evaluaciones. Crear el modelo es un problema inverso: Existen muchos modelos que se ajustan bien a los datos sin parecerse a la función original. Justificación del Estudio
Objetivo Objetivo • Evaluar el desempeño relativo de una metodología de optimización global de funciones costosas basada en el uso de múltiples modelos sustitutos.
Se seleccionaron seis casos de estudio. Éstos se distinguen por tres características: Alta o baja no–linealidad. Alta o baja dimensionalidad. Ruido aleatorio presente o no. Casos de Estudio
Caso de Estudio 1 (P1) Dimens: 10 No–Lin: Alta
Caso de Estudio 2 (P5) Dimens: 16 No–Lin: Baja
Caso de Estudio 3 (P6) Dimens: 2 No–Lin: Alta
Caso de Estudio 4 (P7) Dimens: 2 No–Lin: Alta
Caso de Estudio 5 (P12) Dimens: 2 No–Lin: Baja
Caso de Estudio 6 (P13) Dimens: 2 No–Lin: Baja Con Ruido
Diseño del Experimento y Muestreo (Hipercubo latino) ==> Conjunto de datos iniciales. Ajuste RBF; PRE y KRI ==> 3 Modelos Base. Obtener medidas de incertidumbre para cada modelo ==> Medidas de Incertidumbre. Realizar “Ensamblaje de modelos” (Suma Ponderada) ==> Cuarto Modelo. Optimizar c/u de los 4 modelos (Direct) ==> 4 soluciones. Comparar y analizar resultados. Metodología
Modelos Sustitutos • Los modelos usados fueron: • Kriging (KRI). • Regresión Polinómica (PRE). • Funciones de Base Radial (RBF). • Cada uno de ellos es un caso especial de:
En nuestra versión de Kriging p = 1 y f(x) = 1. Lo cual hace β = μ. Y el modelo queda: μ + ε(x) con donde ; Y es el valor de la función en cada punto de la muestra. R es la matriz de correlación entre los puntos de la muestra y r(x) es el vector de correlación entre cada punto de la muestra y x. Kriging
R y r(x) se estiman mediante modelos de la forma: Donde cada Cjes una función parametrizada decreciente de la distancia entre los puntos. Los Cj usados fueron: exponencial generalizada, gaussiana, spline y esférica. Kriging
Regresión Polinómica • Este es una caso especial de la regresión lineal. • ε(x) se asume que es cero. • Cada fi(x) es una de las siguientes: • La constante 1. • La función identidad de una de las variables. • El producto de dos variables. • El cuadrado de alguna variable.
Funciones de Base Radial • En este caso también se asume ε(x) como cero. • Las fi(x) son funciones gausianas o multicuádricas con centro en algún punto de la muestra. • Además una fi(x) puede ser constante. • Potencialmente a todo punto de la muestre le puede corresponder una función; pero se seleccionan con el método de forward selection. • El radio de cada función se escoge entre distintas opciones según una medida de error.
Kriging: PRE y RBF: RBF: Medidas de Incertidumbre
Resumen de Resultados R–Cuadrado
Resumen de Resultados Razón VEP / SSEP
Resumen de Resultados Optimización
La primera conclusión es que sí es eficaz usar más de un modelo para aproximar una función a partir de una muestra. Esta conclusión está basada en cuatro razones: Conclusiones
1ra: No hubo ningún modelo que fuera siembre, o la mayoría de las veces, el mejor. De hecho cada modelo fue el mejor en por lo menos dos casos. Conclusiones
2da: El modelo Suma Ponderada obtuvo el mejor R2 promedio con la muestra “Pequeña”, y el segundo mejor promedio con la muestra “Escasa”, siendo la diferencia con el mejor promedio, en este último caso, muy pequeña. Conclusiones
3ra: Cuando el modelo Suma Ponderada no tiene el mejor R2 tiene el segundo mejor, con una excepción (P13, “Escasa”). Conclusiones
4ta: También se observó queel modelo Suma Ponderada, tiene la varianza de R2 más baja o segunda más baja. Esto indica que la calidad de sus resultados es consistente. Conclusiones
Sin embargo la pregunta más importante que esta investigación trata de contestar es si vale la pena calcular más de un modelo desde el punto de vista de la optimización. Conclusiones
Aunque en algunos problemas la diferencia entre los óptimos encontrados con los distintos modelos no es muy grande, sí es frecuente que haya uno mucho peor que los demás; y, aunque suele ser el modelo de “Regresión Polinómica” quien presenta ese problema, no es poco frecuente que sea algún otro el peor. Conclusiones
De modo que sigue siendo válido el primero de los argumentos esgrimidos con respecto al modelado: como no hay un modelo que obtenga el mejor óptimo en todos los casos, y ni siquiera uno que sea siempre uno de los dos mejores (aparte del modelo Suma Ponderada), es necesario construir más de un modelo para obtener un óptimo confiable. Conclusiones
Otras observaciones y conclusiones son: El estimador estándar de la varianza del error de RBF, usando el método de Forward Selection, está significativamente sesgado hacia abajo. El estimador de la de Kriging en teoría es sesgado hacia abajo; pero esto no se notó. Conclusiones
Otras observaciones y conclusiones son: Los modelos RBF tuvieron, en promedio, más parámetros que la mitad del tamaño de la muestra (> 57%). Los coeficientes del modelo Suma Ponderada asumen que no hay correlación entre las predicciones de los modelos. Esto no es cierto. Conclusiones
Otras observaciones y conclusiones son: La estimación de la varianza del modelo Suma Ponderada estuvo significativamente sesgada hacia abajo. Conclusiones
Mejorar el modelo Suma Ponderada con información acerca de la correlación de las predicciones de los modelos. Implementar EGO sustituyendo Suma Ponderada por Kriging (o RBF); pero hay que tener en cuenta el sesgo en la estimación de la varianza de Suma Ponderada. Recomendaciones
Encontrar un buen estimador de la varianza de RBF que no sea tan ad–hoc. Los modelos RBF y PRE podrían integrarse como la parte determinística de un modelo de Kriging. (En vez de usar Suma Ponderada). Recomendaciones