Download

1 / 48
480 likes | 504 Views
Explore the deep phylogeny problem using simple models to estimate trees from faintly relevant signals. Learn about the historical interest in animal relationships, from Ernst Haeckel to modern molecular phylogenetics. Discover the implications of mitochondrial DNA genome sequencing on phylogenetic analysis and the importance of tailoring models to account for structural and functional constraints.

E N D
The deep phylogeny problem Using simple models to estimate trees from sparse data sets with faintly relevant signals.
Long history of interest in the relationships among major groups of animals.
Bateson, W., 1886, The ancestry of the Chordata: Quarterly Journal of Microscopical Science, v. 26, p. 535-571. Cope, E. D., 1887, The Origin of the Fittest: New York, Appleton & Company.
Strong resurgent interest in late 20th Century with the advent of Molecular Phylogenetics First influential paper: 1988 Molecular phylogeny of the animal kingdom. Field et al. Science 239: 748-753 Most early analyses were based on 18S rRNA.
Limitations of Metazoan 18S rRNA Sequence Data: Implications for Reconstructing a Phylogeny of the Animal Kingdom and Inferring the Reality of the Cambrian Explosion. Abouheif, Zardoya & Meyer. 1998 Early enthusiasm suggested 18s sequence comparisons were going to solve all of our problems. But within 10 years:
Obviously, it was claimed, we just didn’t have enough data… At about the same time (mid 1990’s) there was an emerging interest in estimating animal phylogenies from whole MtDNA genome sequences. The choice was appealing: • Large amount of sequence (16-18kb). • Reasonably easy to collect (no introns) • Mode of inheritance was well understood. • Almost no problems associated with paralogous comparisons. But even with large amounts of data some quite controversial groupings emerged - and different mitochondrial genes would often suggest conflicting relationships.
fruit fly fruit fly mosquito mosquito snail snail nematode 1 nematode 1 nematode 2 nematode 2 opossum sea urchin1 sea urchin1 sea urchin2 mouse sea urchin2 rat lamprey cow chicken blue whale frog fin-back whale carp carp trout trout opossum mouse rat Obtained cow blue whale fin-back whale In 1998, I published a study with Wes Brown in which we explored the phylogenetic signal in the mitochondrial genome of a group of vertebrates whose phylogenetic relationships were “uncontroversial.” lancelet lancelet lamprey frog chicken
The unexpected placement of Lancelet outside(vertebrates + echinoderms) and the grouping of (frog+ chicken+fishes) results from parsimony analyses with strong bootstrap support at all levels of analysis (nucleotides, transversions and amino acids).
Jukes Cantor Kimura 2P HKY 85 GTR Equal rates 1 = 190018.6565 2 = 189706.5707 p< 0.0001 1 = 189228.2482 2 = 188966.6047 p< 0.0001 1 = 186023.7146 2 = 185874.1456 p= 0.0004 1 = 184936.447 2 = 184809.982 p= 0.0020 I 1 = 184834.253 2 = 184611.3826 p< 0.0001 1 = 183988.9626 2 = 183811.3409 p< 0.0001 1 = 180474.2233 2 = 180403.5445 p = 0.31 1 = 179573.3547 2 = 179525.1419 p = 0.1265 G 1 = 181487.388 2 = 18134.7965 p< 0.0001 1 = 180223.3956 2 = 180146.4203 p = 0.012 1 = 175238.975 2 = 175252.093 p = 0.6165 1 = 174980.1973 2 = 175003.3906 p = 0.3796 I+G 1 = 181340.654 2 = 181204.7859 p< 0.0001 1 = 180109.353 2 = 180030.772 p = 0.0089 1 = 175160.793 2 = 175175.196 p = 0.5739 1 = 174879.9709 2 = 174903.3324 p = 0.3642 • Expected Tree = 1 • MPT = 2 Naylor and Brown 1998 Likelihood analysis of the nucleotide data under the 16 canonical models (JC, K2P, HKY, GTR + I +) all failed to yield the expected tree, placing cephalochordates outside (vertebrates+ echinoderms)
Expected tree Naylor and Brown 1998 Assuming the results to be misleading, we evaluated which kind of sites might be responsible for the misleading patterns by testing the fit of different classes of characters to the expected tree.
We were able to retrieve the expected tree only when we restricted our analyses to the subset of nucleotide sites modally coding for the amino acids P, C, N, M and Q. Hydrophobic residues I, L and V were found to be especially misleading. We concluded (in 1998) that simply sequencing large amounts of sequence wasn’t enough to ensure an accurate estimate of phylogeny. We argued that it was more important to tailor models to accommodate structural and functional constraints. (NB. At that time we were not able to conduct amino acid likelihood analyses due to computational constraints) Naylor and Brown 1998
MTREV + F + MTREV + F fruit fly fruit fly 100 100 mosquito mosquito 100 100 snail snail 70 100 nematode 1 nematode 1 100 100 nematode 2 nematode 2 sea urchin 1 sea urchin 1 100 100 sea urchin 2 sea urchin 2 100 100 lancelet lancelet lamprey 97 lamprey 89 frog carp 100 100 100 94 carp trout 100 100 trout frog 100 77 chicken chicken opossum 82 97 opossum mouse mouse 100 100 100 100 rat rat 100 100 cow cow 100 100 blue whale blue whale 100 100 fin-back whale fin-back whale Yields tree wherein lancelet is sister to Vertebrata - but frog still groups w/fishes Yields expected tree -with strong support More recently (2007) Dave Swofford has implemented AA likelihood models into PAUP. We applied the MtREV model in PAUP* to the Naylor and Brown (1998) data set to see if it yielded a different tree than that seen at the nucleotide level.
Results corroborate prior suspicions that modelling the substitution process appropriately is critically important That we get strong support at all of the nodes for an incorrect topology (frog+fishes) when we donot include underscores that bootstrap support reflects the sampling variance of the signal inducedfrom the interaction between data and model. This need not be a reflection of phylogenetic accuracy. For the inference to be accurate, the model must be unbiased wrt the substitution process that gave rise to the data.
Increasing sequence length Can think of this as a landscape for a given combination of taxa and sequences. As sequence length increases the topography of the peaks and valleys remains roughly the same but becomes exaggerated - resulting in a more decisive landscape (little sampling variance). As model parameters are changed, the underlying pattern of peaks and valleys of the landscape will shift to a different configuration of optima.
Take home message: The details of the model are important. Especially when applied to long sequences and a sparse sample of highly divergent taxa. In such cases there is little help from the data to estimate the pattern of changes. Most of the estimate comes from the model.
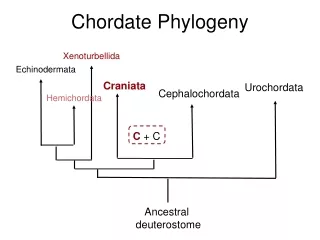
Feb 2006. Delsuc et al using a “phylogenomic” approach assembled a data set of 146 EST derived genes for 38 composite taxa representing metazoan diversity (Fungi [2], Choanoflagelata[3], Cnidaria[4], Protostomia [15], Echinodermata[1] , Cephalochordata[1], Tunicata [4] and Vertebrata [8]. “Tunicates and not cephalochordates are the closest living relatives of vertebrates” Delsuc et al 2006 (and cephalochordates form a clade with echinoderms)
ML methods placed Tunicates as sister to Vertebrates and Amphioxus (Branchiostoma) in a clade with echinoderms Delsuc et al 2006 They used MP, ML (WAG+F+), a Bayesian covarion model, partitioned likelihood (for each of the 146 genes)
However they cautioned: “A definitive conclusion will only be achieved through the phylogenetic analysis of more genes combined with an increased taxon sampling including the enigmatic Xenoturbellidans, the hemichordates and a greater diversity of echinoderms” Delsuc et al. showed that alternative topologies for the relationships among cephalochordates, echinoderms, tunicates and vertebrates had poorer fits to the data Under WAG+F+
“Deuterostome Phylogeny reveals monophyletic chordates and the new phylum Xenoturbellida” Bourlat et al 2006 November 2006. Seemingly following the advice of Delsuc et al. 2006, Bourlat et al. added EST sequences for Xenoturbella, a hemichordate and a starfish to the data set of Delsuc et al. and augmented it for a total of 170 genes. (>35,000AA sites)
Without Xenoturbella, hemichordate and starfish cf Delsuc et al. With Xenoturbella, hemichordate and starfish Bourlat et al 2006 They were able to reproduce Delsuc et al’s tree when they removed Xenoturbella, hemichordate and starfish. This lead Bourlat et al. to conclude that Delsuc et al’s inference was an artifact of sparse taxon-sampling / model mis-specification. (They used a concatenated analysis WAG+F+)
Poor Models? The fact that the data are so sensitive to taxon sampling suggests the models are inadequate. If a model describes the process well inferences should not vary as taxa are added or deleted. Clemens Lakner reanalyzed the data set: Used a partitioned Bayesian AA model under WAG + with independent rates for each of the 170 gene partitions. Same result as Bourlat et al. So…. if it’s a model problem, it’s not one that can be fixed with a simple rate multiplier tailored to each gene.
A A B B X X X X X X X X X X X X X X X X X X X X X X X X orthologous non-orthologous Non-orthologous gene comparisons? Orthology can be a problem with ESTs because putative othologs in different taxa are ultimately identified by sequence similarity, not phylogenetic analysis. Typically orthologs are identified by bi-directional Blast hits. However there are situations in which pairs of strings meeting this criterion for “orthology” will not be true orthologs (rapid evolution of an ortholog in one species can render it more dissimilar to its true ortholog in another species than it is to a paralog in that same species)
In order to evaluate paralogy as a possible source of error, we computed MP bootstrap trees for each of the 170 genes in the Bourlat et al. data set. We filtered the resulting topologies into those that were consistent with 3 positive controls: Monophyletic: (1) vertebrates, (2) insects (3) echinoderms. Only 16 of the 170 genes met the criteria.(?!!) We contrasted the signal in the original set of 170 trees with that of the filtered set of 16 genes meeting the +ve control criteria using consensus networks implemented in Splits Trees 4. (Huson and Bryant, 2006)
tunicates Interesting… Network consensus of 16 trees that meeting +ve control criteria Network consensus of 170 bootstrap parsimony trees RESULTS
But amino acid likelihood of 16 gene subset yields tree with Cephalochordates + Echinoderms and other strange groupings.
Apparently no “quick fix” for these issues Something is awry. Back to first principals…
alignment energetics What are the observed patterns of change in molecules? Both multiple alignment and protein structural energetics suggest that AAs are restricted in what they can change to over the course of evolution.
A C D E F G H I K L M N P Q R S T V W Y Rate Matrix 180 pairwise relative rates (JTT, WAG, MtREV) 20 stationary equilibrium frequencies (avg. from alignment) But current models average AA frequency over entire alignment. Q X =
Consider this site A C D E F G H I K L M N P Q R S T V W Y 20 stationary probabilities equilibrium frequencies averaged over alignment 0.1 0.09 0.08 0.07 0.06 0.05 0.04 0.03 0.02 0.01 0 A C D E F G H I K L M N P Q R S T V W Y Site specific vector of 20 probabilities Better Poor description of reality (for this site).
Not possible to have a separate model tailored to each site (too many parameters) - but possible to assign sites to “categories” with comparable evolutionary freedom to vary. Can have a model tailored to each category and implement a “mixture” of models . Lartillot (2007) proposed such a mixture model to allow categories of sites associated with different biochemical roles to have different AA equilibrium frequencies. (He has implemented this in his Phylobayes software)
1) 2) AA Equil.Freq.profiles Categories (models) 2 3 ….. K Site specific vector of 20 probailities 0.1 0.09 0.08 0.07 0.06 0.05 0.04 0.03 0.02 3) 0.01 0 A C D E F G H I K L M N P Q R S T V W Y Multiply each distribution by rate matrix (WAG, JTT, MtREV etc) Lartillot CAT (mixture) Model Yields a mixture of distributions that better capture the allowable state-space From Lartillot 2007
CAT model can ameliorate model mis-specification for some data sets. We applied it to the Bourlat et al. data set. Resulted in inferences that still show sensitivity to taxon sampling, suggesting model is not adequate.
What’s going on? • Get taxon-sampling dependent inferences for WAG, and CAT. • Suggests models are inadequate. • What else might be going on?
We know amino acid sequences code for structures. Beta-barrel (porins) Alpha -helical bundle (rhodopsin)
We know that structures show limited variation among lineages BUT they do show a little. Superimposed backbones of 28 Hurudinin structes (PDB_ID 4H1R)
We also know that patterns of substitution vary across both sites and taxa. Rate variation across cytB (courtesy Jun Inoue)
With consequences for phylogenetic branch lengths. Rate variation among lineages based on whole MtDNA (Courtesy Jun Inoue)
It is possible (likely?) that minor conformational changes in some non-critical parts of structures affect the local freedom to vary of sites in lineage specific ways? Primates Fishes Sites showing differences in freedom to vary between primates and fishes
If true, such changes in freedom to vary over a tree would require that amino acid frequencies of mixture models should be allowed to change over the tree. (mixture model : covarion hybrid) OUTLOOK Potential (practical) strategies: Ensure that input data meet some minimum criteria that ensures orthology. (2) Minimize among lineage heterogeneity by excluding genes and/or sites that exhibit non-stationary dynamics. (Housekeeping genes deeply embedded in the genetic architecture with similar constraints across taxa) (3) Optimize parameters on a (structurally informed) gene-by-gene basis to accommodate context dependent evolutionary change.
Collecting more and more ESTs about which we know little does not look promising(to me).
SUMMARY • As data sets include more characters, sampling variance decreases and we are no longer shielded from the effects of model mis-specification • Accurate estimates are likely to come from a better appreciation of the transformational tendencies associated with individual sites. (Biochemically motivated process models) • Until then we will have to prop up our inadequate models with thoughtful taxon sampling. • Phylogenomics as currently practised is close to the worst case scenario (Long sequences, Ambiguous orthology, Divergent taxa, Sparse taxon-sampling).
Acknowledgements: Clemens Lakner Mark Holder
classical vertebrate Phylogeny! Lartillot Brinkmann & Phillippe (2007) published a paper advocating use of the CAT model. Results they present are at odds with their paper the previous year (Delsuc et al. 2006) but consistent with classical vertebrate phylogeny they had overturned in 2006. Posterior consensus CAT+F+
Traditional phylogeny based on morphology and embryology (after Hyman) New molecule-based phylogeny (18s) Summarized by Adoutte et al 2000.
What are ESTs anyway? ESTs are fragments of expressed genes cloned from a cDNA library. They are produced by single-pass sequencing from one end of a cDNA clone. They are generally of poor quality. Many are short (<200bp). But bioinformatic pipelines have been constructed to sort and filter them. EST fragments deemed usable are “blasted” against reference data bases. Sequence similarity is used to ascertain “identity” and by transitivity “function” of sequences EST projects are underway for several organisms. Milions of bases pour in to data bases every day, providing potentiallyuseful comparative data. Many phylogenetic researchers have seized the opportunity to assemble data sets of what they consider to be orthologous ESTs in different taxa.