Download
1 / 3
30 likes | 59 Views
Semalt, semalt SEO, Semalt SEO Tips, Semalt Agency, Semalt SEO Agency, Semalt SEO services, web design, web development, site promotion, analytics, SMM, Digital marketing

E N D
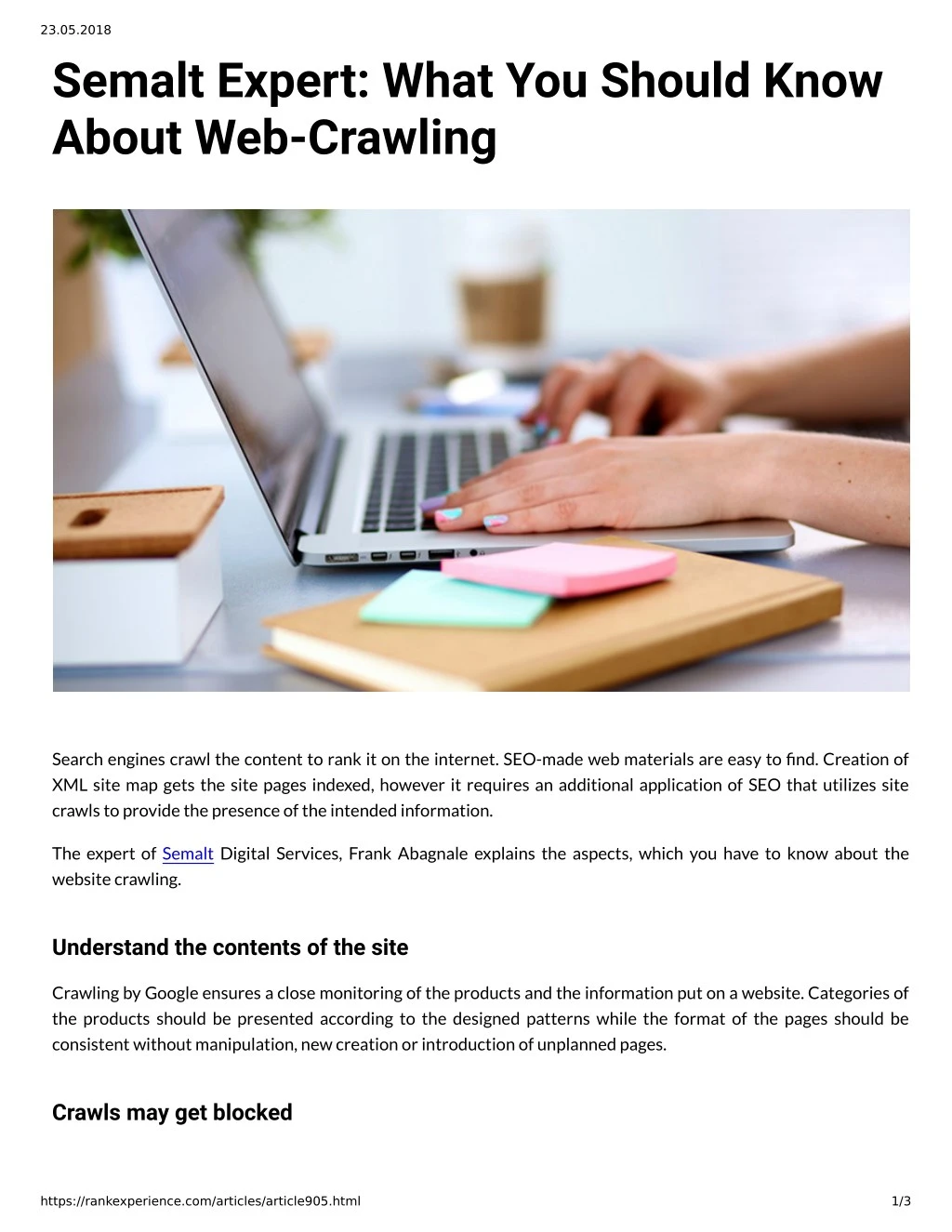
23.05.2018 Semalt Expert: What You Should Know About Web-Crawling Search engines crawl the content to rank it on the internet. SEO-made web materials are easy to ?nd. Creation of XML site map gets the site pages indexed, however it requires an additional application of SEO that utilizes site crawls to provide the presence of the intended information. The expert of Semalt Digital Services, Frank Abagnale explains the aspects, which you have to know about the website crawling. Understand the contents of the site Crawling by Google ensures a close monitoring of the products and the information put on a website. Categories of the products should be presented according to the designed patterns while the format of the pages should be consistent without manipulation, new creation or introduction of unplanned pages. Crawls may get blocked https://rankexperience.com/articles/article905.html 1/3
23.05.2018 Standard errors that result in missing of some parts of information in a particular search may happen due to the inability of the crawler to complete the access. Some SEO issues may result in distortion of format or altered URL title and missing size ?lter of the searched page. A check in the robots.txt or Noindex global can help to resolve the crawl blocking. Understanding commonly disallowed URLs Despite the correct SEO, some URLs may be rejected due to robots.txt. Learning what sites can experience makes it possible to distinguish mistaken and intentional blocks of the crawler. Know the 404 errors Returning a 404 error may occur due to having not enough information for the search engines to fetch or the site is unindexed because of discontinued. A client with an objective of increasing their online performance through the SEO should observe and understand the reason behind the error message if they must ?nd a resolution. Find out redirections Understanding the crawler and how it identi?es redirects is important to reduce the number of redirects before the search engine ?nds a real page needed. Conversion of 302 redirects to 301 enables the leaking out of about 15 percent of the transfers to the end page. Identify weak meta data Crawlers are excellent tools for identi?cation of poorly presented information on the website. They analyze if pages are duplicate or they contain incorrect meta data which deny the ranking of the pages even with SEO due to action by robots Noindex. Analysis of canonical tags The Recent introduction of canonical tags can be a subject of duplicating content, when applied incorrectly. Analysis of the relevant content for tagging through the use of crawlers ensures removal of duplicated content. Find custom data Applying RegEx or XPath in addition to the crawlers can provide identi?cation of expressions and the XML parts of the document by the search engine. This part of the SEO mechanism tells the crawler to grab fundamental elements of the pages such as prices, data structure, and graphics of the content. https://rankexperience.com/articles/article905.html 2/3
23.05.2018 Use the analytics A lot of crawlers utilize Google Search Console and Google Analytic tools to provide information for all crawled pages. This facilitates optimization of searched pages and provision of the required data to put the required information on the search map. The best outcome from crawlers and SEO mechanisms depends on the type of websites, and the content presented. Identi?cation of the proper crawling tools is a ?rst step to achieving an online presence that has a guaranteed success. Finding the particular reason for the unveiled information through analysis ensures a possible way of ?xing the problem. https://rankexperience.com/articles/article905.html 3/3