Download

1 / 25
250 likes | 282 Views
This research paper introduces a novel network flow approach called FlowPlace for timing-driven incremental placement in ASIC designs. The methodology focuses on improving timing incrementally on critical paths while minimizing impact on other metrics. Prior work, motivations, benchmarks, and experimental results are discussed to showcase the efficiency of this approach. The study addresses the challenge of fast timing closure and the need to meet various performance metrics simultaneously. By leveraging network flow-based detailed placement techniques, the method aims to enhance accuracy and convergence in initial placement, making it suitable for high-performance applications and ECO scenarios.

E N D
A NetworkFlow Approach to TimingDriven IncrementalPlacement for ASICs Shantanu Dutt, Huan Ren, Fenghua Yuan and Vishal Suthar Dept. of Electrical and Computer Engineering University of IllinoisChicago
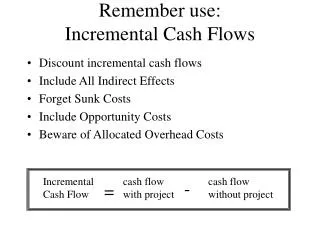
Outline • Motivation & prior work • General methodology of FlowPlace • Net delay model • TD analytical global placement • TD network flow based detailed placer • Benchmarks • Experimental results • Conclusions
Placement in high performance designs Has large effect on performance metrics, e.g., timing, power Fast timing closure is a major but often hard-to-realize goal Need to meet several metrics at the same time Incremental timing-driven placement Initial placement improve timing incrementally on crit. paths More accurate timing information can be acquired from the initial placement Minimize the affect to other metrics in initial placement—convergence is a byproduct Also important for ECO applications Motivation
Prior Work • Existing timing driven placement • Path-based: minimize the critical paths directly • Pros: timing is essentially path-based • Cons: excessive number of paths. • Net-based: transform timing into net-weights or net-budgets • Pros: low complexity, flexible • Cons: often ignores path information; has a convergence problem • Net-based approach is the most common method • Kahng et al. (ISPD’02) • Minimize the max weighted net delay using LP with net weight based on the max path delay violation through the net. All paths meet constraints simultaneously. • Can fit into a standard WL-driven top-down design flow • Yang et al. (ICCAD’02) • New slack allocation approach which assigns more slack to nets with larger estimated WL and fanout • Minimizing total net delay violation using simulated annealing • Achieves a more efficient slack usage in final placement
Prior Work (cont.) Incremental TD placement • Wonjoon et al. (ICCAD’03) • Path based constraints for every violated path pj (has maximum path # limit) • Simple bisection method to remove overlap, no control of delay change • Luo et al. (DAC’06) • Consider both cells in the critical path and cells that are logically adjacent to the critical path to control timing perturbation • Delay model with delay/slew propagation • Both algorithms use LP for replacement, which doesn’t address the quadratic part of the delay accurately N/w flow based detailed placement • Brenner et al. (ISPD’04), Doll et al. (ICCAD’94) • Try to send flow from congested area or cells that haven’t been placed to vacant area with minimum cost • Allow temporary small illegality (e.g., overlap or out of boundary) caused by movement according to the flow • WL driven, and the deterioration is small from global placement results
Initial placed circuit STA & Determine critical node set (moveC) TD analytical global placement (TAN) on moveC TD n/w-flow based detailed placement (TIF) On moveC New placement w/ improved performance Our Goals & Methodology • Goals: • Accurate pre-route delay est. • Targeted global & detailed TD re-placement of critical & near-critical paths • Minimal effect on the rest of the circuit • Fast
up (xp, yp) ud (xd, yd) uq (xq, yq) ui (xi, yi) centroid C(xc, yc) Star graph model WL and Pre-Route Delay Model • WL calculation We use a star graph model to calculate WL Driver node driving load capacitance • Pre-route delay model Self interconnect delay ui (xi, yi) (1-g) of Ctotal ld, i Self interconnect seeing other interconnect & load capacitance up (xp, yp) ud (xd, yd) ld, i/2 g of Ctotal uq (xq, yq) Delay model Best results for g = 1 Fidelity of our model. The future model is still under development, which modeling nets with multiple star structures
Net w/ 2 critical paths through it TD Analytical Global Placement (TAN) • A TD extension of a combination of Gordian and Gordian-L • Essentially a quadratic programming approach • Use an iterative approach to model the linear terms of delay in objective function • Critical delay cost of a net • Need to focus only on the sinks on the critical paths. • Formulation: • A net with more critical paths through it is more important to optimize—can achieve min. on all those paths w/ one opt. step
3 3 3 4 4 4 3 3 After optimization one is longer than the other 2 2 2 3 3 After optimization both paths have approx. the same delay TD Analytical Global Placement (contd.) • Allocated slack of a net • A weight measure for determining TD WL reduction of a net • Two factor needs to be considered: minimum path slack through the net and # of nets in that path. • Therefore we uniformly allocate path slack to each net, the allocated slack of a net is: Equi-delay paths Net slack= Path slack: Observaton: Nets with the same weight in TAN tend to have the same length after optimization 6 6 Net delay Before optimization two paths have the same delay Thus we can get:
Quadratic terms. Can be solved by normal quadratic programming technique Linear part. The linear terms here is approximated by a quadratic terms as following In the formulation, the coordinates in the denominator is the current value We do several iterations until the results convergent The linear terms of y is dealt in the same way TD Analytical Global Placement (contd.) • Final objective function to solve min-max via min-sum • The delay cost of a net • The objective function The delay cost part is divided into quadratic and linear part
TD N/W-Flow Based Detailed Placement (TIF) C21 C11 C12 C13 C14 A1 C22 C24 W2 Cell placement after cells are moved in the flow direction • General Purpose • Solves the overlap problem form global placer • Minimizes the deterioration of delay improvement obtd. from global placer • Legalizes the placement satisfying WS constraints General n/w-flow graph C11 C12 C13 C14 W1 Row1 Source Row2 C21 C22 W21 C24 W2 T S Sink A1 A2 • Arc cost = TD cost; linear & step funct. • Arc capacity: • hor: how much a cell can move • (accuracy issues) • vert: width of head cell • S moved cell: width(cell) • row T: WS of row C31 C32 C33 W3 Row3 Flow to legalize A1 position
u’i Dld,i ui (1-g) of C’total l’d,i up ud If ui is the critical sink or driver g of C’total uq Delay model Otherwise: Arc Cost in TIF • Sensitivity based cost • We define delay of a net to be the delay from its driver cell to its most critical sink cell. Consider the net delay change when a cell is moved: • Arc cost formulation • For a cell, we find the most critical nets (belong to path with smallest slack) connected to it, the unit flow cost of the arcs from the cell is: From experiments, k=2 gives best results
w(v)=7 overlap disp(v)=2 v u v f1=2 (5, c1) disp(u)=5 v disp(w)=3 (7, c3) (7, c2) u disp(w)=5 w x w x f2=3 w(v)=5 Non-discrete flow Tackling Illegalities in TIF • The incremental detailed placement problem is a DOP. Thus, certain illegalities are introduced in it by using a continuous optimization method. There are two major problems • Discrete flow requirement in vertical arcs • The vertical arc represents vertical cell movement by a discrete amount (dist to nearest row). • flow on it should be either full capacity (cell width) or 0. • N/w-flow solution may not meet this requirement • Resulting placement problems: u v u w x Resulting Placement. The full cost of movement is not incurred in n/w-flow. Cell moved up has larger area than the n/w flow modeled Initial placement
Tackling Illegalities in TIF (contd.) • Our flow discretizing soln for vertical arc: The 3 step process: • Step1: Initially, vertical arc cap=1, cost=full cost • Step2: After the first 1 unit flow is passed, cap=original cap-1, cost=0 • Step3: After all flow is passed. The cost and capacity of the adjacent horizontal arc are updated to 0 w(v)=7 w(v)=7 w(v)=7 disp(v)=5 v v v u v f2=4 f2=4 f1=1 f1=1 f1=1 (1, full-cost) (4,0) (4,0) disp(u)=5 (7, c3) (7, c2) (7, c3) (7, c2) (inf,0) (inf,0) w x u u u w x w x w x w(v)=5 w(v)=5 w(v)=5 disp(w)=5 Step2 Step3 Step1 Full cost is incurred Final placement Horiz arc cost updated Encourage flow to keep going through arc
Tackling illegalities in TIF (contd.) • Split flows This occurs when there are flows on both upward and downward arcs. C21 C22 f2=3 (5,c1) (5,c2) f1=2 C31 C32 • Two heuristics to solve the problem • The two split flow will go through the tree structure to the sink. There are two heuristic. • Max flow: We choose the branch tree with larger flow 2. Min cost: We choose the branch tree with smaller flow cost looking at the first k levels Tree1 C12 ……. C21 C22 C23 f1 A1 ….. f2 Tree2 C31 C32 C33 Our experiment shows Max flow heuristic does better.
Satisfying White Space Constraints • Due to the discrete nature of the detailed placement problem, the white space constraint: max row width does not exceed a pre-specified limit can’t be ensured by the n/w-flow process. • Two methods are used to deal with this problem • Dynamic row size constraint monitoring • Push-violation arcs in the next iteration w(v)=7 WS=3 v WS=-2 u v f1=2 (5, c1) disp(u)=5 (7, c3) (7, c2) u disp(w)=5 w x w f2=3 w(v)=5 WS violation Non-discrete flow
Violated row S Satisfying WS Constraints (contd.) • Dynamic WS constraint monitoring • Monitor total cell width in each row after every –ve cycle-based iter. improv. of n/w flow: Initial flow on vertical arc: the total cell width is moved to target row Fully reverse flow: the total cell width is moved back to orig. row • To facilitate cell movement we allow temporary white space violation in a row for each direction of the flow • Once a viol in a direction occurs no further are allowed unless it goes to 0. Monitored by top and bottom viol guards Gb and Gt • If violation remains in the row then: • Push violation arc in the next iteration. Thrashing prevented by disallowing reverse movement Min-cost flow W=4 Full row Gt = 0 -5 Otherwise W=3 W=9 Gb = 0 4 4 Net viol = 0 -1 W=7 Min-cost flow
Physical flow interpretation Global n/w flow Detailed n/w flow (on induced network) No All new cells placed & all viol fixed? Yes End TIF’s High-level Flow Global Network Flow • Global flow network gives a global view of generally how flows will go. • With the global flow, we can eliminate detailed-flow arcs that are not likely to have flow on it • This can greatly reduce the cycles in the detailed n/w-flow, thus reducing time without obvious improvement deterioration Ci+1 is probabilistic average of all left-to-right detailed horizontal arc costs in the row Ci+1,I is the weighted average of the detailed vertical arc costs between two rows Row i-1 A2 (w(A2),0) violated row (violi,0) Row i Sink (w(R), Ci+1,i)) A1 (w(Wi+1), Ci+1) Row i+1 65 % runtime reduction at the cost of 1-2 timing deterioration
Benchmarks • There are three set of benchmarks Ibm, Faraday and TD-Dragon • The Ibm and Faraday are originally not timing benchmarks; we generate synthetic timing characteristics for them • The Ibm circuits don’t identify FFs. We determine FFs in cycles, and break all cycles with minimum # of FFs. The average percentage of FFs is 13% • Both suites don’t have information of resistance and capacities of cells and interconnects. We choose the typical value of .18 microns technique for these parameters. • Benchmark Characteristics
Efficacy of TD Arc Costs • Global place (TAN) Detailed place (TD cost): deterioration 4.3% • Detailed place (unit cost): deterioration 7.8% • Detailed place (0 cost): deterioration 10.7% • 45% deterioration reduction of global place results by going from unit-cost TD-cost
Final Results 24.2% 19.7% 4.5% Delay improvement for ibm benchmarks—initial placement WL-driven (Dragon) 24.3% 20.6% 3.7% Delay improvement for Faraday benchmarks—initial placement WL-driven (Dragon)
Final Results (contd.) 12.0% 8.2% 24.1% 3.8% 19.6% 4.5% Delay improv. for TD-Dragon benchmarks placed by Dragon (cell delay) Delay improv for TD-Dragon benchmarks placed by Dragon (no cell delay) 10.2% 4.0% 6.2% Delay improvement on TD-Dragon placement for different WS constraints. • [Wonjoon & Bazargan, ICCAD’03]achieves an avg of 2.8% improv. with 5% WS • For 5% WS, our improvement is 4.2% (50% relative improvement)
Empirical Asymptotic Time Complexity • Runtime is 18% of Dragon and 12% of TD-Dragon • Obtains a soln for a 210K cct ibm18 w/ 34% improv in 24 mins Linear curve best fits data Linear curve best fits data
Conclusions • Proposed a TD incremental placement flow FlowPlace • Global and detailed incremental placer • New accurate pre-route net delay models • Can opt. both quadratic and the linear delay terms in global placer • TD n/w flow to solve detailed TD placement: • sensitivity-based TD arc costs; constraint satisfaction (e.g., WS); discretization of illegal continuous solns; global n/w flow graph • Promising results • Delay improv up to 34%--for a 210K-cell WL-opt. layout in 24 mins • Delay improv up to 10%--for a 26K-cell TD-opt. layout in just above 5 mins • The average delay improvement is18.34% • The WL deterioration is an average of 8% • The average run time is only 12-18% of original placement runtime • TD-IBM benchmarks and placed outputs avail at the FlowPlace page:www.ece.uic.edu/~dutt/benchmarks-etc/FlowPlace/flow.html • Concepts can be extended to timing and power optimization with constraints and physical re-synthesis
Satisfying white space constraints • Dynamic WS constraint monitoring • We monitor total cell width in each row after every –ve cycle-based iter. improv. of n/w flow: initial flow on vertical arc: the total cell width is moved target row fully reverse flow: the total cell width is moved back to orig. row • To facilitate cell movement we allow temporary white space violation under constraints W=5 W=5 vio_top=3 x u WS=-3 vio_top=0 vio_bot=0 W=7 WS=2 WS=-2 v Sink Viol_max=max cell width Violation from above and bellow are calculated separately vio_top=3 W=5 vio_top=0 u WS=-5 v WS=0 v vio_bot=0 vio_bot=2 WS=5 WS=0 u Because the flow allowed in step two due to separate violation limit for flow from above and below, we can finally legalize the placement.