Download

1 / 11
110 likes | 208 Views
The Scientific Method. Probability and Inferential Statistics. Lecture 6: Probaility and Inferential Statistics. Probability and Inferential Statistics.

E N D
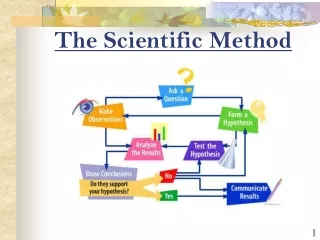
The Scientific Method Probability and Inferential Statistics
Lecture 6: Probaility and Inferential Statistics Probability and Inferential Statistics Scientific investigations sample values of a variable to make inferences(or predictions) about all of its possible values in the population BUT! There is always some doubt as to whether observed values = population values eg Jersey cow serum iron concentrations • Inferential statisticsquantify the doubt – • What are the chances of conclusions based on a sample of the population holding true for the population as a whole ? • are the conclusions safe ? – will the prediction happen in most observed situations? Probability is defined as a relative frequency or proportion – the chanceof something happening out of a defined number of opportunities
Lecture 6: Probaility and Inferential Statistics For example: subjectively as a % expectation of an event – a cow has a 60% chance of calving tonight (based on experience, but subject to individual opinions) a priori probability – based on the theoretical model defining the set of all probabilities of an outcome. eg when a coin is tossed, the probability of obtaining a head is ½ or 0.5 defined probability– the proportion of times an event will occur in a very large number of trials (or experiments) performed under similar conditions. e.g. the proportion of times a guinea pig will have a litter of greater than three, based upon the observed frequency of this event All of these approaches are related mathematically Probabilities can be expressed as a percentage (23%), a fraction / proportion (23/100) or a decimal (0.23) as parts of a whole (= parts of a unitised number of opportunities)
Lecture 6: Probaility and Inferential Statistics Two rules govern probabilities Addition rule – when two events are mutually exclusive (they can’t occur at the same time) the probabilities of eitherof them occurring is the sum of the probabilities of each event eg 1/5 + 1/5 = 2/5 or 0.4 for two particular biscuits out of 5 types Multiplication rule- when two events are independent, the probability of both events occurring = the product of their individual probabilities e.g. a Friesian cow inseminated on a particular day has a probability of calving 278 days later (the mean gestation period) of 0.5 (she either calves or she doesn’t!) If two Friesian cows are inseminated on the same day, then the probability of both of them calving on the same day 278 days later is (0.5 x 0.5 ) = 0.25 Probability distributions can derive from discreteor continuous data a discrete random variable with only two possible values (e.g. male/female)is called a binary variable
The binomial distribution portrays the frequency distribution of data relating to an “all or none” event – whether an animal displays or doesn’t display a characteristic eg pregnant / not pregnant, number of spots on ladybirds (either 3,5,7,9,11,15,18, 21 etc!) eg number of spots on ladybirds in a sample For a continuous variable, the probability that its value lies within a particular interval is given by the relevant area under the curve of the probability density function Lecture 6: Probaility and Inferential Statistics The NORMAL ( or Gaussian )DISTRIBUTION is a theoretical distribution of a continuous random variable (x) whose properties can be described mathematically by the mean () and standard deviation (σ)
Lecture 6: Probaility and Inferential Statistics the proportion of the values of x lying between + and – 1x (times!), 1.96x and 2.58x the standard deviation on either side of the mean. It means 100% of the data values are included within 3 sd units either side of the mean In a perfectly symmetricalnormal distribution,MEAN, MEDIAN and MODE have the same value Normal distributions with the same value of the standard deviation (σ) but different values of the mean ()
Lecture 6: Probaility and Inferential Statistics It is possible to make predictions about the likelihood of the mean value of a variable differing from another mean value – whether the difference is likely or unlikely to be due to chance alone This is the basis of significance testing - if the distribution of observed values approximates to the normal distribution, it becomes possible to compare means of variables with the theoretical distribution and estimate whether their observed differences are significantly differentfrom the expected values of each variable if they are truly normally distributed eg Student’s t Test We carry out an experiment on guinea pigs to test the hypothesis that dietary lipid sources rich in ω3 polyunsaturated fatty acids improve coat condition We compare the breaking strength of hairs from two groups of 10 guinea pigs fed a normal mix compared with a diet supplemented with cod liver oil, recording the max. weight their hair will support as tensile strength in g. We want to decide whether the mean strength of hairs from the control and experimental groups differ significantly at the end of the trial
First we must calculate the sample mean, variance and standard deviation for each data set (control and test) If the data for the control mean are referred to as a and the test mean as b, then the t statistic is calculated as: Lecture 6: Probaility and Inferential Statistics Calculating the t statistic The steps for doing this manually are best set out in a table
Hair Tensile Strength GP Control Group a (g) Hair Tensile Strength GP Test Group b (g) Xa – Xa (Xa – Xa)2 Xb – Xb (Xb– Xb )2 6.6 7.9 0.26 0.067 0.42 0.176 5.9 8.4 -0.44 0.193 0.92 0.846 7.0 8.0 0.66 0.436 0.52 0.270 6.1 6.7 -0.24 0.058 -0.78 0.608 6.3 8.8 -0.04 0.002 1.32 1.742 6.0 6.5 -0.34 0.116 -0.98 0.960 6.8 7.2 0.46 0.212 -0.28 0.078 5.6 6.8 -0.74 0.548 -0.68 0.462 6.7 6.4 0.36 0.130 -1.08 1.166 6.4 8.1 0.06 0.004 0.62 0.384 ∑ = 63.4 ∑ = 74 .8 ∑ = 1.77 ∑ = 6.69 Xa = 6.34 Xb = 7.48 Lecture 6: Probaility and Inferential Statistics Calculating the t statistic na= 10 nb = 10
Calculating the variance: and the standard deviation and finally the t statistic! We can ignore the –ve sign! Degrees of Freedom of the data set Lecture 6: Probaility and Inferential Statistics Calculating the t statistic We then compare our calculated value of t with those in the table of critical values for the value of t
Lecture 6: Probaility and Inferential Statistics Significance and confidence These are the significance levels for the t statistic at 10%, 5%, 1% and 0.1%, (from left to right) If our value for t (2.78) exceeds any of the tabulated values of t for 18 df, which it does forp = 0.05, but not for p = 0.01, we can say “the means are different at the 5% level of significance and we can rejectH0” (the null hypothesis of no difference between the two treatments) The confidence level is simply 100 – (significance level) So, alternatively, we could say: “ we can be 95% confident that there is asignificant difference between the two means”