Download

1 / 29
310 likes | 403 Views
AT Arithmetic. Most concern has gone into creating fast implementation of (especially) FP Arith. Under the AT (area-time) rule, area is (almost) as important. So it ’ s important to know the latency, bandwidth and area that any particular algorithm requires. Integer addition.

E N D
AT Arithmetic • Most concern has gone into creating fast implementation of (especially) FP Arith. • Under the AT (area-time) rule, area is (almost) as important. • So it’s important to know the latency, bandwidth and area that any particular algorithm requires.
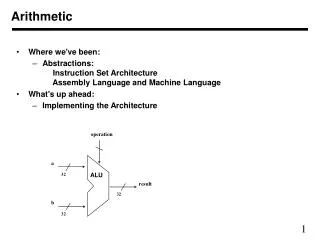
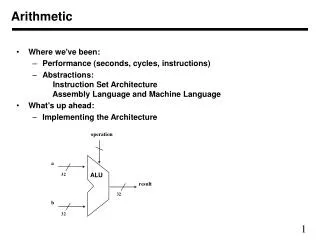
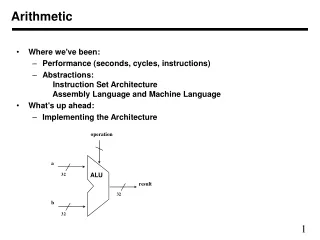
Integer addition • Adders are the fundamental building block of the processor, defining Dt. • Adder types include • carry chain, carry select (conditional sum), carry lookahead (Brent-Kung), canonic (prefix) carry skip, Ling • Most high speed 32b adders take about the same area (f normalized)…1 A to 1.5A
Integer addition • Both area and time scale as n, the adder precision. The delay, t, scales slowly (log n) • Area scale about linearly with n; so a 64b adder takes 2-3 A, but still fits into Dt…maybe by definition of a “cycle”.
FP addition • A basic FP adder has 5 steps • exponent difference, pre align, significand add, post align, and round. • Assuming that a full shifter has about the same complexity (delay and area) as an add, then 64b FP addition takes 7 - 10 A, and has about 5 Dt execution
FP addition • Advanced FP adders are faster and use more area: • 1) Two path FADD creates separate paths for operands; • a path for operands whose exponents close in value (subtract) - this is the only case when we need a full shift to renormalize the result • a path for other cases where the exponent difference is > 2 • (this is the only case that uses a full shift to prealign significands) • 2) A FADD with integrated rounding. Here the rounding step is eliminated by computing both the sum/difference and the result plus 1… this is done by using 2 adders (or a compound adder) and then MUXing out the final result.
FP adders • The two path FP adder uses an additional significand adder and exponent adder… about 3-4 A. It reduces FADD delay by one Dt • Integrated rounding adds another rounding adder plus MUX…another 3-4 A while reducing delay by another Dt
FP adders • Net area time tradeoff • Basic… Area 10 A and delay 4-5 Dt • Two path… Area 13.5 A and delay 3-4 Dt • Integrated round (with two paths)… area 17 A and delay 2-3 Dt • For pipelining add 1 A per pipe stage and use upper range on Dt
Multipliers • After add, the most important arithmetic op • Approaches • encode the multiplier bits (Booth 2, Booth 3...) • assimilate the partial products • one, two or n pass (iterated arrays or trees) • arrays (simple, double, higher level) • trees (Wallace, binary[4:2], ZD,….) • CPA to produce product
Multipliers • Integer and FP multipliers usually have about the same execution time (with same precision, n) • Booth reduces number of pp’s but adds MUXs to generate the pp’s. • Most of the area, and probably delay too, is in the pp reduction tree.
Multipliers • A full tree implementation of a 54b (FP type) with Booth 2 has tree height 28 and uses about 2500 CSAs (or about 50 A in the tree). Maybe a total of 10 A in MUXs plus 50 A in tree and 3A in the CPA, 62A total.The fastest multiplier is, maybe, 2 Dt • Using a 2 pass tree reduces the hardware considerably; height is 14 using about 700 CSAs or 14 A…total area 5 + 14 + 3 = 22A; 3-4 Dt
Multipliers • To pipeline the Multiplier we need a full tree implementation; probably 3-4 Dt. • Perhaps Booth3, followed by a full tree (h = 17) and CPA stage. • Probably area = 50 - 60A
Divide • Infrequent op, but long latency can affect IPC achieved. • Algorithms: • SRT 2 or 3 bit (32 - 36 Dt) maybe 6-10 A • NR or Binomial expansion (10- 14Dt); needs at least 6 A for table and control plus use of MPY • Bipartite tables for small n (less than 24b)
Divide SRT creates quotient 2 or 3 bits/iteration • uses divisor - partial remainder lookup table for trial quotient then subtracts • result (partial rem.) is in redundant form so no restoration is needed; also result is left as a sum and carry pair (no cpa needed) • fast iteration is possible, sometimes 2x per Dt
Divide Multiply based use either Newton Raphson or Binomial series • if f(x) = b - 1/x; root is at x = 1/b then NR iteration is xi+1 = xi (2 -bxi ) • converges is quadratic, doubles precision of result each iteration • so start with table lookup of 1/b to 8b, then 3 iterations gives 64b result then a x (1/b) is quotient
Divide • Divide is not usually pipelined, except for small n implementations. • Frequently combined with square root in the same implementation.
Sub word concurrency • Provides 8, 16, 32b concurrent ops within “existing” integer or FP hardware • In 64b integer unit can do 8x8, or 4x16, or 2x32 ops concurrently • Since FP units are designed to be faster, may be use it: 8x4, or 2x16, or 2x24.
Sub word concurrency • Usually only for add and multiply • Implementations straightforward for add; more complicated for multiply • requires reorganizing partitions of the pp tree • affects multiply area and delay marginally (maybe 10% delay and 20% area) • isa must define “saturating” arithmetic.