Download

1 / 32
320 likes | 341 Views
Comparing software and hardware approaches for FPGA parallelism, designing soft processors, customizing architecture, utilizing data-level parallelism, vector processors, achieving faster, smaller, and lower-power designs. Evaluating the gap between soft vector processors and custom hardware, measuring performance using EEMBC benchmarks, analyzing VESPA architecture, instruction sets, memory hierarchy, and evaluation infrastructure. Measuring performance gap reduction through enhancements like reducing loop overhead, pipeline decoupling, cache optimization, and data prefetching. Results show soft vector processors closing the performance gap with 3x better silicon usage compared to scalar processors.

E N D
Data Parallel FPGA Workloads: Software Versus Hardware Peter Yiannacouras J. Gregory Steffan Jonathan Rose FPL 2009
FPGA Systems and Soft Processors Simplify FPGA design: Customize soft processor architecture Target: Data level parallelism → vector processors Digital System computation Weeks Months Software + Compiler HDL + CAD Soft Processor Custom HW Used in 25% of designs [source: Altera, 2009] Faster Smaller Less Power Easier COMPETE ?Configurable
Vector Processing Primer vadd // C code for(i=0;i<16; i++) c[i]=a[i]+b[i] // Vectorized code set vl,16 vload vr0,a vload vr1,b vadd vr2,vr0,vr1 vstore vr2,c vr2[15]=vr0[15]+vr1[15] vr2[14]=vr0[14]+vr1[14] vr2[13]=vr0[13]+vr1[13] vr2[12]=vr0[12]+vr1[12] vr2[11]=vr0[11]+vr1[11] vr2[10]=vr0[10]+vr1[10] vr2[9]= vr0[9]+vr1[9] vr2[8]= vr0[8]+vr1[8] vr2[7]= vr0[7]+vr1[7] vr2[6]= vr0[6]+vr1[6] vr2[5]= vr0[5]+vr1[5] vr2[4]= vr0[4]+vr1[4] Each vector instruction holds many units of independent operations vr2[3]= vr0[3]+vr1[3] vr2[2]= vr0[2]+vr1[2] vr2[1]= vr0[1]+vr1[1] vr2[0]= vr0[0]+vr1[0] 1 Vector Lane
Vector Processing Primer 16x speedup vadd // C code for(i=0;i<16; i++) c[i]=a[i]+b[i] // Vectorized code set vl,16 vload vr0,a vload vr1,b vadd vr2,vr0,vr1 vstore vr2,c 16 Vector Lanes vr2[15]=vr0[15]+vr1[15] vr2[14]=vr0[14]+vr1[14] vr2[13]=vr0[13]+vr1[13] • Previous Work (on Soft Vector Processors): • Scalability • Flexibility • Portability vr2[12]=vr0[12]+vr1[12] vr2[11]=vr0[11]+vr1[11] vr2[10]=vr0[10]+vr1[10] vr2[9]= vr0[9]+vr1[9] vr2[8]= vr0[8]+vr1[8] vr2[7]= vr0[7]+vr1[7] vr2[6]= vr0[6]+vr1[6] vr2[5]= vr0[5]+vr1[5] vr2[4]= vr0[4]+vr1[4] Each vector instruction holds many units of independent operations vr2[3]= vr0[3]+vr1[3] vr2[2]= vr0[2]+vr1[2] vr2[1]= vr0[1]+vr1[1] vr2[0]= vr0[0]+vr1[0]
Soft Vector Processors vs HW What is the soft vector processor vs FPGA custom HW gap? (also vs scalar soft processor) Weeks Soft Vector Processor Months Software + Compiler HDL + CAD + Vectorizer Custom HW Lane 1 Lane 2 Lane 3 Lane 4 Lane 5 Lane 6 Lane 7 Lane 8 …16 Scalable Fine-tunable Customizable Vector Lanes How much? Faster Smaller Less Power Easier
Measuring the Gap EEMBC Benchmarks Soft Vector Processor Scalar Soft Processor HW Circuits Evaluation Evaluation Evaluation Compare Compare Speed Area Speed Area Speed Area Conclusions
VESPA Architecture Design(Vector Extended Soft Processor Architecture) Icache Dcache Legend Pipe stage Logic Storage M U X WB Decode RF A L U Scalar Pipeline 3-stage VC RF VC WB Supports integer and fixed-point operations [VIRAM] Vector Control Pipeline 3-stage Logic Shared Dcache Decode VS RF VS WB Decode Repli- cate Hazard check VR RF VR WB Vector Pipeline 6-stage VR RF Lane 1 ALU,Mem Unit VR WB Lane 2 ALU, Mem, Mul 32-bit Lanes
VESPA Parameters Compute Architecture Instruction Set Architecture Memory Hierarchy
VESPA Evaluation Infrastructure VC RF VC WB Logic VS RF VS WB Mem Unit Decode Repli- cate Hazard check VR RF VR RF VR WB VR WB Satu- rate Satu- rate M U X M U X A L U A L U Realistic and detailed evaluation x & satur. Rshift x & satur. Rshift SOFTWARE HARDWARE Verilog EEMBC C Benchmarks GCC ld scalar μP ELF Binary + Vectorized assembly subroutines GNU as vpu TM4 Instruction Set Simulation RTL Simulation Altera Quartus II v 8.1 area, clock frequency cycles verification verification
Measuring the Gap EEMBC Benchmarks Soft Vector Processor Scalar Soft Processor HW Circuits VESPA Evaluation Evaluation Evaluation Compare Compare Speed Area Speed Area Speed Area Conclusions
Designing HW Circuits(with simplifying assumptions) Optimistic HW implementations vs real processors HW cycle count (modelled) Assume fed at full DDR bandwidth Calculate execution time from data size Memory Request Idealized Altera Quartus II v 8.1 Control area, clock frequency DDR Core Datapath
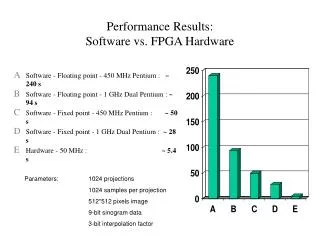
Benchmarks Converted to HW HW advantage: 3x faster clock frequency Stratix III 3S200C2 EEMBC VIRAM HW Clock: 275-475 MHz VESPA Clock: 120-140 MHz
Performance/Area Space (vs HW) Soft vector processors can significantlyclose performance gap Scalar – 432x slower, 7x larger HW Speed Advantage Slowdown vs HW HW Area Advantage Area vs HW fastest VESPA 17x slower, 64x larger HW (1,1) optimistic
Area-Delay Product • Commonly used to measure efficiency in silicon • Considers both performance and area • Inverse of performance-per-area • Calculated using: (Area) × (Wall Clock Execution Time)
Area-Delay Space (vs HW) VESPA up to 3 times better silicon usage than Scalar Area-Delay vs HW 2900x HW Area-Delay Advantage 900x HW Area Advantage
Reducing the Performance Gap These enhancements were key parts of reducing gap, combined 3x performance improvement • Previously: VESPA was 50x slower than HW • Reducing loop overhead • VESPA: Decoupled pipelines (+7% speed) • Improving data delivery • VESPA: Parameterized cache (2x speed, 2x area) • VESPA: Data Prefetching (+42% speed)
Wider Cache Line Size … vld.w (load 16 sequential 32-bit words) VESPA 16 lanes Scalar Vector Coproc Lane 0 Lane 0 Lane 0 Lane 4 Lane 0 Lane 0 Lane 0 Lane 8 Lane 0 Lane 0 Lane 0 Lane 12 Lane 4 Lane 4 Lane 15 Lane 16 Vector Memory Crossbar Dcache 4KB, 16B line
Wider Cache Line Size … 2x speed, 2x area (reduced cache accesses + some prefetching) vld.w (load 16 sequential 32-bit words) VESPA 16 lanes Scalar Vector Coproc Lane 0 Lane 0 Lane 0 Lane 4 Lane 0 Lane 0 Lane 0 Lane 8 Lane 0 Lane 0 Lane 0 Lane 12 Lane 4 Lane 4 Lane 15 Lane 16 Vector Memory Crossbar 4x Dcache 16KB, 64B line 4x
Hardware Prefetching Example … … 42% speed improvement from reduced miss cycles No Prefetching Prefetching 3 blocks vld.w vld.w vld.w vld.w MISS MISS MISS HIT Dcache Dcache 10 cycle penalty 10 cycle penalty DDR DDR
Reducing the Area Gap (by Customizing the Instruction Set) • FPGAs can be reconfigured between applications • Observations: Not all applications • Operate on 32-bit data types • Use the entire vector instruction set • Eliminate unused hardware
VESPA Parameters Reduce width Subset instruction set
Customized VESPA vs HW Up to 45% area saved with width reduction & subsetting HW Speed Advantage Slowdown vs HW Area vs HW HW Area Advantage 45%
Summary Enable software implementation for non-critical data-parallel computation • VESPA more competitive with HW design • Fastest VESPA only 17x slower than HW • Scalar soft processor was 432x slower than HW • Attacking loop overhead and data delivery was key • Decoupled pipelines, cache tuning, data prefetching • Further enhancements can reduce the gap more • VESPA improves efficiency of silicon usage • 900x worse area-delay than HW • Scalar soft processor 2900x worse area-delay than HW • Subsetting/width reduction can further reduce to 561x
Thank You! • Stay tuned for public release: • GNU assembler ported for VIRAM (integer only) • VESPA hardware design (DE3 ready)
Breaking Down Performance • Components of performance Iteration-level parallelism Loop: <work> goto Loop … Loop: <work> goto Loop b) Loop: <work> goto Loop Cycles per iteration × Clock period c) a) Measure the HW advantage in each of these components
Breakdown of Performance Loss(16 lane VESPA vs HW) Was previously worse, recently improved Total 17x Largest factor
1-Lane VESPA vs Scalar • Efficient pipeline execution • Large vector register file for storage • Amortization of loop control instructions. • More powerful ISA (VIRAM vs MIPS): • Support for fixed-point operations • Predication • Built-in min/max/absolute instructions • Execution in both scalar and vector co-processor • Manual vectorization in assembly versus scalar GCC
Measuring the Gap C EEMBC C Benchmarks Scalar: MIPS soft processor VESPA: VIRAM soft vector processor HW: Custom circuit for each benchmark (complete & real) COMPARE assembly (complete & real) COMPARE Verilog (simplified & idealized)
Reporting Comparison Results 1. Scalar (C) vs HW (Verilog) • Performance (wall clock time) • Area (actual silicon area) vs HW (Verilog) 2. VESPA (Vector assembly) 3. HW (Verilog) Execution Time of Processor HW Speed Advantage= Execution Time of Hardware Area of Processor HW Area Advantage= Area of Hardware
Cache Design Space – Performance (Wall Clock Time) Best cache design almost doubles performance of original VESPA More pipelining/retiming could reduce clock frequency penalty Cache line more important than cache depth (lots of streaming) 122MHz 123MHz 126MHz 129MHz
Vector Length Prefetching - Performance 1*VL prefetching provides good speedup without tuning, 8*VL best Peak 29% Not receptive 21% 2.2x no cache pollution
Overall Memory System Performance Wider line + prefetching reduces memory unit stall cycles significantly Wider line + prefetching eliminates all but4% of miss cycles 16 lanes 67% 48% 31% 4% (4KB) (16KB) 15