Download
1 / 1
20 likes | 164 Views
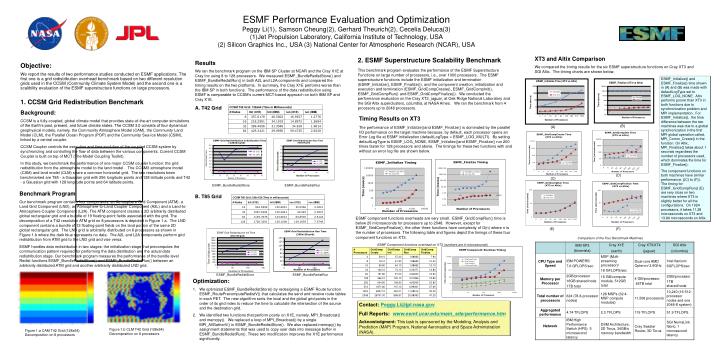
ESMF_Initialize Time (XT3 vs Altix). ESMF Grid Redistribution Run Time. ESMF Grid Redistribution Initialization Time. ESMF Grid Redistribution Init Time. ESMF_Finalize (XT3 vs Altix). (128x64 grid). (128x64 grid). (256x128 grid). 450. 10000. 70. 10000.00. 2000. 400. 1800. 60.

E N D
ESMF_Initialize Time (XT3 vs Altix) ESMF Grid Redistribution Run Time ESMF Grid Redistribution Initialization Time ESMF Grid Redistribution Init Time ESMF_Finalize (XT3 vs Altix) (128x64 grid) (128x64 grid) (256x128 grid) 450 10000 70 10000.00 2000 400 1800 60 1000.00 350 Columbia Init (X1E) 1600 1000 50 300 Init (IBM) Cray XT3 1400 100.00 40 250 1200 Columbia Time (milliseconds) Time (msecs) 30 100 Cray XT3 1000 200 Time (msecs) Time (milliseconds) run (X1E) Init (X1E) 10.00 Time (milliseconds) 800 20 run (IBM) 150 Init (IBM) 600 1.00 100 10 10 400 4 16 32 64 128 256 512 1024 8 50 0 200 0.10 0 20 40 60 80 0 0 1 Number of Processors 0 10 20 30 50 60 70 40 4 8 16 32 64 128 256 512 1024 0.01 0 50 100 150 Number of Processors Number of Processors Number ofProcessors Number of Processors ESMF Performance Evaluation and Optimization Peggy Li(1), Samson Cheung(2), Gerhard Theurich(2), Cecelia Deluca(3) Jet Propulsion Laboratory, California Institute of Technology, USA Silicon Graphics Inc., USA (3) National Center for Atmospheric Research (NCAR), USA XT3 and Altix Comparison We compared the timing results for the six ESMF superstructure functions on Cray XT3 and SGI Altix. The timing charts are shown below. 2. ESMF Superstructure Scalability Benchmark This benchmark program evaluates the performance of the ESMF Superstructure Functions on large number of processors, i.e., over 1000 processors. The ESMF superstructure functions include the ESMF initialization and termination (ESMF_Initialize(), ESMF_Finalize()), and the component creation, initialization and execution and termination (ESMF_GridCompCreate(), ESMF_GridCompInit(), ESMF_GridCompRun() and ESMF_GridCompFinalize()). We conducted the performance evaluation on the Cray XT3, jaguar, at Oak Ridge National Laboratory and the SGI Altix superclusters, columbia, at NASA Ames. We ran the benchmark from 4 procesors up to 2048 processors. Results We ran the benchmark program on the IBM SP Cluster at NCAR and the Cray X1E at Cray Inc using 8 to 128 processors. We measured ESMF_BundleRedistStore() and ESMF_BundleRedistRun() in both A2L and L2A components and compared the timing results on the two platforms. In summary, the Cray X1E performs worse than the IBM SP in both functions. The performance of the data redistribution using ESMF is comparable to CCSM’s current MCT-based approach on both IBM SP and Cray X1E. A. T42 Grid Objective: We report the results of two performance studies conducted on ESMF applications. The first one is a grid redistribution overhead benchmark based on two different-resolution grids used in the CCSM (Community Climate System Model) and the second one is a scalibility evaluation of the ESMF superstructure functions on large processors. ESMF_Initialize() and ESMF_Finalize() time shown in (A) and (B) was made with defaultLogType set to ESMF_LOG_NONE. Altix performs poorer than XT3 in both functions due to synchronization problem and MPI implementation. For ESMF_Initialize(), the time difference between the two machines was due to a global synchronization in the first MPI global operation called, MPI_Comm_Create() in the function. On Altix, MPI_Finalize() takes about 1 seconds regardless the number of processors used, which dominates the time for ESMF_Finalize(). The component functions on both machines have similar performance. ((C) to (F)). The timing for ESMF_GridCompRun() (E) are very close on two machines where XT3 is slightly better for all the configurations. On 1024 processors, it takes 11.28 microseconds on XT3 and 13.84 microseconds on Altix. 1. CCSM Grid Redistribution Benchmark Background: CCSM is a fully-coupled, global climate model that provides state-of-the-art computer simulations of the Earth’s past, present, and future climate states. The CCSM 3.0 consists of four dynamical geophysical models, namely, the Community Atmosphere Model (CAM), the Community Land Model (CLM), the Parallel Ocean Program (POP) and the Community Sea-Ice Model (CSIM), linked by a central coupler. CCSM Coupler controls the execution and time evolution of the coupled CCSM system by synchronizing and controlling the flow of data between the various components. Current CCSM Coupler is built on top of MCT (The Model Coupling Toolkit). In this study, we benchmark the performance of one major CCSM coupler function: the grid redistribution from the atmosphere model to the land model . The CCSM3 atmosphere model (CAM) and land model (CLM) share a common horizontal grid. The two resolutions been benchmarked are T85 - a Gaussian grid with 256 longitude points and 128 latitude points and T42 - a Gaussian grid with 128 longitude points and 64 latitude points. Timing Results on XT3 The performance of ESMF_Initialize()and ESMF_Finalize() is dominated by the parallel I/O performance on the target machine because, by default, each processor opens an Error Log file at ESMF initialization (defaultLogType = ESMF_LOG_MULTI). By setting defaultLogType to ESMF_LOG_NONE, ESMF_Initialize()and ESMF_Finalize() run 200 times faster for 128 processors and above. The timings for these two functions with and without an error log file are shown below. (B) (A) (D) (C) ESMF_BundleRedistStore ESMF_BundleRedistRun Benchmark Program Our benchmark program contains four components: an Atmosphere Grid Component (ATM), a Land Grid Component (LND), an Atmosphere-to-Land Coupler Component (A2L) and a Land-to-Atmosphere Coupler Component (L2A). The ATM component creates a 2D arbitrarily distributed global rectangular grid and a bundle of 19 floating-point fields associated with the grid. The decomposition of a T42 resolution ATM grid on 8 processors is depicted in Figure 1.a. The LND component contains a bundle of 13 floating-point fields on the land portion of the same 2D global rectangular grid. The LND grid is arbitrarily distributed on 8 processors as shown in Figure 1.b where the dark blue represents no data. The A2L and L2A components perform grid redistribution from ATM grid to the LND grid and vise versa. ESMF handles data redistribution in two stages: the initialization stage that precomputes the communication pattern required for performing the data distribution and the actual data redistribution stage. Our benchmark program measures the performance of the bundle level Redist functions ESMF_BundleRedistStore() and ESMF_BundleRedistRun() between an arbitrarily distributed ATM grid and another arbitrarily distributed LND grid. B. T85 Grid ESMF component functions overheads are very small. ESMF_GridCompRun() time is below 20 microseconds for processors up to 2048. However, except for ESMF_GridCompFinalize(), the other three functions have complexity of O(n) where n is the number of processors. The following table and figures depict the timings of these four component functions on XT3. (E) (F) Comparison of the Four Benchmark Machines ESMF Component functions overhead on XT3 (numbers are in microseconds) ESMF_BundleRedistStore ESMF_BundleRedistRun • Optimization: • We optimized ESMF_BundleRedistStore() by redesigning a ESMF Route function ESMF_RoutePrecomputeRedistV() that calculates the send and receive route tables in each PET. The new algorithm sorts the local and the global grid points in the order of its grid index to reduce the time to calculate the intersection of the source and the destination grid. • We identified two functions that perform poorly on X1E, namely, MPI_Broadcast() and memcpy(). We replaced a loop of MPI_Broadcast() by a single MPI_AllGatherV() in ESMF_BundleRedistStore(). We also replaced memcpy() by assignment statements that was used to copy user data into message buffer in ESMF_BundleRedistRun(). These two modification improves the X1E performance significantly. Contact: Peggy.Li@jpl.nasa.gov Full Reports: www.esmf.ucar.edu/main_site/performance.htm Acknowledgment:This task is sponsored by the Modeling, Analysis and Prediction (MAP) Program, National Aeronautics and Space Administration (NASA). Figure 1.b CLM T42 Grid (128x64) Decomposition on 8 processors Figure 1.a CAM T42 Grid (128x64) Decomposition on 8 processors






















