Download

1 / 19
190 likes | 321 Views
Runahead Execution. A review of “Improving Data Cache Performance by Pre-executing Instructions Under a Cache Miss” Ming Lu Oct 31 , 2006. Outline. Why How Conclusions Problems. Why?. The Memory Latency Bottleneck.

E N D
Runahead Execution A review of “Improving Data Cache Performance by Pre-executing Instructions Under a Cache Miss” Ming Lu Oct 31 , 2006
Outline • Why • How • Conclusions • Problems
Why? The Memory Latency Bottleneck Computer Architecture, A quantitative Approach. Third Edition Hennessy, Patterson
Solutions: • Cache • A safe place for hiding or storing things -Webster’s New World Dictionary of the American Language (1976) • Reduce average memory latency by caching data in a small, fast RAM • Data Pre-fetching • Parallelism
A New Problem Arise • Cache misses are the main reason of processor stall in modern superscalars, especially for L2, each miss can take hundreds cycles to complete.
Runahead: A Solution for Cache Missing Runahead history
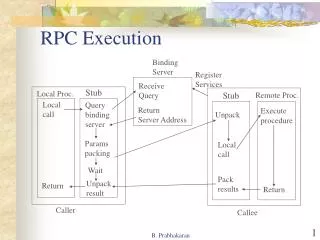
How? Initiated on an instruction or data cache miss Restart at the initiating instruction once the miss is serviced Adapted from Dundas
Hardware Support Required for Runahead • We need to be able to compute load/store addresses, branch conditions, and jump targets • Must be able to speculatively update registers during runahead • Register set contents must be checkpointed • Shadow each RF RAM cell, these cells form the BRF • Copy RF to BRF when entering runahead • Copy BRF to RF when resuming normal operation • Pre-processed stores cannot modify the contents of memory • Fetch logic must save the PC of the Runahead-initiating instruction RF : Register File BRF : Backup Register File Adapted from Dundas
Entering and Exiting Runahead • Entering runahead • Save the contents of the RF in the BRF • Save the PC of the runahead-initiating instruction • Restart instruction fetch at the first instruction in the next sequential line if runahead is initiated on an instruction cache miss • Exiting runahead • Set all of the RF and L1 data cache runahead-valid bits to the VALID state • Restore the RF from the BRF • Restart instruction fetch at the PC of the instruction that initiated runahead Adapted from Dundas
Instructions • Register-to-register • Mark their destination register INV if any of their source registers are INV • Can replace an INV value in their destination register if all sources are valid • Load • Mark their destination register INV if: • the base register used to form the effective address is marked INV, or • a cache miss occurs, or • the target word in the L1 data cache is marked INV due to a preceding store • Can replace an INV value in their destination register if none of the above apply Adapted from Dundas
Instructions (cont.) • Store • Pre-processed stores do not modify the contents of memory • Stores mark their destination L1 data cache word INV if: • the base register used to form the effective address is not INV, and • a cache miss does not occur • Values are only INV with respect to subsequent loads during the same runahead episode • Conditional branch • Branches are resolved normally if their operands are valid • If a branch condition is marked INV, then the outcome is determined via branch prediction • If an indirect branch target register is marked INV, then the pipeline stalls until normal operation resume Adapted from Dundas
Instructions (cont.) • jump register indirect • assume that the return stack contains the address of the next instruction Adapted from Dundas
Two Runahead Branch Policies When a conditional branch or jump is pre-executed that is dependent on an invalid register, • Conservative: halt runahead until the miss is ready. • Aggressive: keep going but assumes that the branch prediction or subroutine call return stack performance is good enough to accurately resolve the branch or jump
An Example IRV : Invalid Register Vector 0: Invalid 1: Valid
Benefit • Early execution of memory operations which are potential cache misses • Re-execution of these instructions will most probably be cache hits It allows further instructions to be execute. But these instructions are executed again after exit from runahead mode.
Conclusions • Pre-process instructions while cache misses are serviced • Don’t stall for instructions that are dependent upon invalid or missing data • Loads and stores that miss in the cache can become data prefetches • Instruction cache misses become instruction prefetches • Conditional branch outcomes are saved for use during normal operation • All pre-processed instruction results are discarded • Only interested in generating prefetches and branch outcomes • Runahead is a form of very aggressive, yet inexpensive, speculation Adapted from Dundas
Problems • Increases the number of executed instructions • Pre-executed instructions consume energy • What if a short-time runahead happen
Reference [1]J. Dundas and T. Mudge. Improving data cache performance by pre-executing instructions under a cache miss. In ICS-11, 1997. [2] J. D. Dundas. Improving Processor performance by Dynamically Pre-Processing the Instruction Stream. PhD thesis, Univ. of Michigan, 1998. [3] O. Mutlu, J. Stark, C.Wilkerson, and Y. N. Patt. Runahead execution: An alternative to very large instruction windows for out-of-order processors. In HPCA-9, pages 129–140, 2003. [4] H. Akkary, R. Rajwar, and S. T. Srinivasan. Checkpoint processing and recovery: Towards scalable large instruction window processors. In MICRO-36, pages 423–434, 2003. [5] L.Ceze, K.Strauss, J.Tuck, J. Renau and J.Torrellas CAVA: Hiding L2 Misses with Checkpoint-Assisted Value Pridiction, In Computer Architecture Letters, 2006