Download

1 / 34
360 likes | 651 Views
Learning Process. CS/CMPE 537 – Neural Networks. Learning. Learning…? Learning is a process by which the free parameters of a neural network are adapted through a continuing process of stimulation by the environment in which the network is embedded

E N D
Learning Process CS/CMPE 537 – Neural Networks
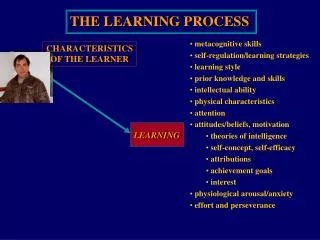
Learning Learning…? • Learning is a process by which the free parameters of a neural network are adapted through a continuing process of stimulation by the environment in which the network is embedded • The type of learning is determined by the manner in which the parameter changes take place • Types of learning • Error-correction, memory-based, Hebbian, competitive, Boltzmann • Supervised, reinforced, unsupervised CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Learning Process • Adapting the synaptic weight wkj(n + 1) = wkj(n) + Δwkj(n) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Learning Algorithms • Learning algorithm: a prescribed set of well-defined rules for the solution of a learning problem • In the context of synaptic weight updating, the learning algorithm prescribes rules for Δw • Learning rules • Error-correction • Memory based • Boltzmann • Hebbian • Competitive • Learning paradigms • Supervised • Reinforced • Self-organizing (unsupervised) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Error-Correction Learning (1) ek(n) = dk(n) – yk(n) • The goal of error-correction learning is to minimize a cost function based on the error function • Least-mean-square error as cost function J = E[0.5Σkek2(n)] E = expectation operator • Minimizing J with respect to the network parameters is the method of gradient descent CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Error-Correction Learning (2) • How do we find the expectation of the process? • We avoid its computation, and use an instantaneous value of the sum of squared errors as the error function (as an approximation) ξ(n) = 0.5Σkek2(n) • Error correction learning rule (or delta rule) Δwkj(n) = ηek(n)xj(n) η = learning rate • A plot of error function and weights is called an error surface. The minimization process tries to find the minimum point on the surface through an iterative procedure. CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Memory-based Learning (1) • All (or most) of the past experiences are stored explicitly in memory of correctly classified input-output examples: {(xi, di)}i = 1, N • Given a test vector xtest , the algorithm retrieves the classification of the xi ‘closest’ to xtest in the training examples (and memory) • Ingredients • Definition of what is ‘closest’ or ‘local neighborhood’ • Learning rule applied to the training examples in the local neigborhood CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Memory-based Learning (2) • Nearest neigbor rule • K-nearest neighbor rule • Radial-basis function rule (network) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Hebbian Learning (1) • Hebb, a neuropsychologist, proposed a model of neural activation in 1949. Its idealization is used as a learning rule in neural network learning. • Hebb’s postulate (1949) • If the axon of cell A is near enough to excite cell B and repeatedly or perseistently takes part in firing it, some growth process or metabolic change occurs in one or both cells such that A’s efficiency as one of the cells firing B is increased. CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Hebbian Learning (2) • Hebbian learning (model of Hebbian synapse) • If two neurons on either side of a synapse are activated simultaneously, then the strength of that synapse is selectively increased • If two neurons on either side of synapse are activated asynchronously, then that synapse is selectively weakened or eliminated • Properties of Hebbian synapse • Time-dependent mechanism • Local mechanism • Interactive mechanism • Correlational mechanism CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Mathematical Models of Hebbian Learning (1) • General form of Hebbian rule Δwkj(n) = F[yk(n), xj(n)] F is a function of pre-synaptic and post-synaptic activities. • A specific Hebbian rule (activity product rule) Δwkj(n) = ηyk(n)xj(n) η = learning rate • Is there a problem with the above rule? • No bounds on increase (or decrease) of wkj CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Mathematical Models of Hebbian Learning (2) • Generalized activity product rule Δwkj(n) = ηyk(n)xj(n) – αyk(n)wkj(n) Or Δwkj(n) = αyk(n)[cxk(n) - wkj(n)] where c = η/ α and α = positive constant CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Mathematical Models of Hebbian Learning (3) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Mathematical Models of Hebbian Learning (4) • Activity covariance rule Δwkj(n) = η cov[yk(n), xj(n)] = η E[(yk(n) – y’)(xj(n) – x’)] where η = proportionality constant and x’ and y’ are respective means After simplification Δwkj(n) = η {E[yk(n)xj(n)] – x’y’} CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Competitive Learning (1) • The output neurons of a neural network (or a group of output neurons) compete among themselves for being the one to be active (fired) • At any given time, only one neuron in the group is active • This behavior naturally leads to identifying features in input data (feature detection) • Neurobiological basis • Competitive behavior was observed and studied in the 1970s • Early self-organizing and topographic map neural networks were also proposed in the 1970s (e.g. cognitron by Fukushima) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Competitive Learning (2) • Elements of competitive learning • A set of neurons • A limit on the strength of each neuron • A mechanism that permits the neurons to compete for the right to respond to a given input, such that only one neuron is active at a time CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Competitive Learning (3) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Competitive Learning (4) • Standard competitive learning rule Δwji = η(xi – wji) if neuron j wins the competition 0 otherwise • Each neuron is allotted a fixed amount of synaptic weight which is distributed among its input nodes Σi wji = 1 for all j CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Competitive Learning (5) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Boltzmann Learning • Stochastic learning algorithm based on information-theoretic and thermodynamic principles • The state of the network is captured by an energy function, E E = -1/2 ΣkΣj wkjsisk where sj = state of neuron j [0, 1] (i.e. binary state) • Learning process • At each step, choose a neuron at random (say kj) and flip its state sk (to - sk ) by the following probability w(sk -> -sk) = (1 + exp(-ΔEk/T)]-1 • The state evolves until thermal equilibrium is achieved CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Credit-Assignment Problem • How to assign credit and blame for a neural network’s output to its internal (free) parameters ? • This is basically the credit-assignment problem • The learning system (rule) must distribute credit or blame in such a way that the network evolves to the correct outcomes • Temporal credit-assignment problem • Determining which actions, among a sequence of actions, are responsible for certain outcomes of the network • Structural credit-assignment problem • Determining which internal component’s behavior should be modified and by how much CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Supervised Learning (1) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Supervised Learning (2) • Conceptually, supervised learning involves a teacher who has knowledge of the environment and guides the training of the network • In practice, knowledge of the environment is in the form of input-output examples • When viewed as a intelligent agent, this knowledge is current knowledge obtained from sensors • How is supervised learning applied? • Error-correction learning • Examples of supervised learning algorithms • LMS algorithm • Back-propagation algorithm CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Reinforcement Learning (1) • Reinforcement learing is supervised learning in which limited information of the desired outputs is known • Complete knowledge of the environment is not available; only basic benefit or reward information • In other words, a critic rather than a teacher guides the learning process • Reinforcement learning has roots in experimental studies of animal learning • Training a dog by positive (“good dog”, something to eat) and negative (“bad dog”, nothing to eat) reinforcement CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Reinforcement Learning (2) • Reinforcement learning is the online learning of an input-output mapping through a process of trail and error designed to maximize a scalar performance index called reinforcement signal • Types of reinforcement learning • Non-associative: selecting one action instead of associating actions with stimuli. The only input received from the environment is reinforcement information. Examples include genetic algorithms and simulated annealing. • Associative: associating action and stimuli. In other words, developing a action-stimuli mapping from reinforcement information received from the environment. This type is more closely related to neural network learning. CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Supervised Vs Reinforcement Learning CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Unsupervised Learning (1) • There is no teacher or critic in unsupervised learning • No specific example of the function/model to be learned • A task-independent measure is used to guide the internal representation of knowledge • The free parameters of the network are optimized with respect to this measure CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Unsupervised Learning (2) • Also known as self-organizing when used in the context of neural networks • The neural network develops an internal representation of the inputs without any specific information • Once it is trained it can identify features in the input, based on the task-independent (or general) criterion CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Supervised Vs Unsupervised Learning CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Learning Tasks • Pattern association • Pattern recognition • Function approximation • Control • Filtering • Beamforming CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Adaptation and Learning (1) • Learning, as we know it in biological systems, is a spatiotemporal process • Space and time dimensions are equally significant • Is supervised error-correcting learning spatiotemporal? • Yes and no (trick question ) • Stationary environment • Learning – one time procedure in which environment knowledge is built-in (memory) and later recalled for use • Non-stationary environment • Adaptation – continually update the free parameters to reflect the changing environment CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Adaptation and Learning (2) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Adaptation and Learning (3) e(n) = x(n) - x’(n) where e = error; x = actual input; x’ = model output • Adaptation needed when e not equal to zero • This means that the knowledge encoded in the neural network has become outdated requiring modification to reflect the new environment • How to perform adaptation? • As an adaptive control system • As an adaptive filter (adaptive error-correcting supervised learning) CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS
Statistical Nature of Learning • Learning can be viewed as a stochastic process • Stochastic process? – when there is some element of randomness (e.g. neural network encoding is not unique for the same environment that is temporal) • Also, in general, neural network represent just one form of representation. Other representation forms are also possible. • Regression model d = g(x) + ε where g(x) = actual model; ε = statistical estimate of error CS/CMPE 537 - Neural Networks (Sp 2004/2005) - Asim Karim @ LUMS