Download

1 / 35
350 likes | 359 Views
This project involves reading and critically appraising a recent research paper from SIGIR or WWW conferences that is relevant to the student's project. The student must summarize the paper, compare it to other work, and discuss interesting issues or research directions that arise.

E N D
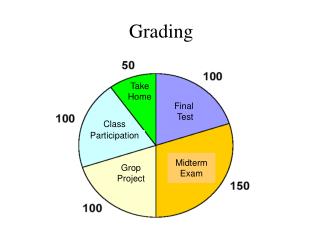
Course grading • Project: 65% • Broken into several incremental deliverables • Paper appraisal/evaluation in earlier May: 15% • One open-book exam on May 23: 20%
Paper appraisal • You are to read and critically appraise a recent research paper in SIGIR or WWW conferences which is relevant to your project • Students work by themselves, not in groups • By April 24, you must obtain instructor confirmation on the paper you will read • Propose a paper no later than April 17 • By May 12 you must turn in a 3-4 page report on the paper: • Summarize the paper • Compare it to other work in the area • Discuss some interesting issue or some research directions that arise • I.e., not just a summary: there should be some value-add
Project • Opportunity to devote time to a substantial research project • Typically a substantive programming project • Work in teams of 2 students
Project • Due April 14: Project group and project idea • Decision on project group • Brief description of project area/topic • We’ll provide initial feedback • Due April 21: Project proposal • Should break project execution into three phases – Block 1, Block 2 and Block 3 • Each phase should have a tangible deliverable • Block 1 delivery due May 5 • Block 2 due May 19 • Block 3 (final project report) due June 9th • June 6/9: Student project presentations
Project - breakdown • 10% for initial project proposal • Scope, timeline, cleanliness of measurements • Writeup should state problem being solved, related prior work, approach you propose and what you will measure. • 10% for deliveries each of Blocks 1, 2 • 30% for final delivery of Block 3 • Must turn in a writeup • Components measured will be overall scope, writeup, code quality, fit/finish. • Writeup should be ~8 pages
Project Presentations • Project presentations in class (about 10 mins per group): • Great opportunities to get feedback. • April 25/28: Students present project plans • June 6/9: Final project presentations
Plan for today • Project ideas • Project examples from stanford web search/mining course • Tools • WordNet • Google API • Amazon Web Services / Alexa • Lucene • Stanford WebBase • Next time: more datasets and tools, implementation issues
Project examples: summary • Leveraging existing theory/data/software is not only acceptable but encouraged, e.g.: • Web services • WordNet • Algorithms and concepts from research papers • Etc. • Most projects: compare performance of several options, or test a new idea against some baseline
Project Ideas • Build a static or dynamic page summarization for a web page based on a query. • Build a search engine for DMOZ and compare and improve the ranking algorithm. • Build a search engine for UCSB technical reports. Compare and improve the ranking algorithm. • Crawl pages of a particular subject and build a special database. • Classify pages based on DMOZ categories.
Lucene • http://jakarta.apache.org/lucene/docs/index.html • Easy-to-use, efficient Java library for building and querying your own text index • Could use it to build your own search engine, experiment with different strategies for determining document relevance, …
Amazon Web Services:E-Commerce Service (ECS) • http://www.amazon.com/gp/aws/landing.html • Mostly for third-party sellers, so not that appropriate for our purposes • But information on sales rank, product similarity, etc. might be useful for a project related to recommendation systems • Also could build some sort of parametric search UI on top of this
Google API • http://www.google.com/apis/ • Web service for querying Google from your software • You can use SOAP/WSDL or the custom Java library that they provide (already installed) • Limited to 1,000 queries per day per user, so get started early if you’re going to use this! • Three types of request: • Search: submit query and params, get results • Cache: get Google’s latest copy of a page • Query spell correction • Note: within search requests you can use special commands like link, related, intitle, etc.
WordNet • http://www.cogsci.princeton.edu/~wn/ • Java API available (already installed) • Useful tool for semantic analysis • Represents the English lexicon as a graph • Each node is a “synset” – a set of words with similar meanings • Nodes are connected by various relations such as hypernym/hyponym (X is a kind of Y), troponym, pertainym, etc. • Could use for query reformulation, document classification, …
Amazon Web Services:Alexa Web Information Service • Currently in beta, so use at your own risk… • Limit 10,000 requests per user per day • Access to data from Alexa’s 4 billion-page web crawl and web usage analysis • Available operations: • URL information: popularity, related sites, usage/traffic stats • Category browsing: claims to provide access to all Open Directory (www.dmoz.com) data • Web search: like a Google query • Crawl metadata • Web graph structure: e.g. get in-links and out-links for a given page
Stanford WebBase • http://www-diglib.stanford.edu/~testbed/doc2/WebBase/ • They offer various relatively small web crawls (the largest is about 100 million pages) offering cached pages and link structure data • Includes specialized crawls such as Stanford and UC-Berkeley • They provide code for accessing their data • More on this next week
Recommendation systems • Web resources (contain lots of links): • http://www.paulperry.net/notes/cf.asp • http://jamesthornton.com/cf/ • Data: • EachMovie dataset: 73,000 users, 1600 movies, 2.5 million ratings • http://www.grouplens.org/node/76 • other data? • Software: • Cofi: http://www.nongnu.org/cofi/ • CoFE: http://eecs.oregonstate.edu/iis/CoFE/
More project ideas (these slides borrowed from previous editions of the course from other schools)
MovieThing • A project for Stanford CS 276 in Fall 2003 • Web-based movie recommendation system • Implemented collaborative filtering: using the recorded preferences of a group of users to extrapolate an individual’s preferences for other items • Goals: • Demonstrate that my collaborative filtering was more effective than simple Amazon recommendations (used Amazon Web Services to perform similarity queries) • Identify aspects of users’ preference profiles that might merit additional weight in the calculations • Personal favorites and least favorites • Deviations from popular opinion (e.g. high ratings of Pauly Shore movies)
Tadpole • Mahabhashyam and Singitham, Fall 2002 • Meta-search engine (searched Google, Altavista and MSN) • How to aggregate results of individual searches into meta-search results? • Evaluation of different rank aggregation strategies, comparisons with individual search engines. • Evaluation dimensions: search time, various precision/recall metrics (based on user-supplied relevance judgments).
Using Semantic Analysis to Classify Search Engine Spam • Greene and Westbrook, Fall 2002 • Attempted semantic analysis of text within HTML to classify spam (“search engine optimized”) vs. non-spam pages • Analyzed sentence length, stop words, part of speech frequency • Fetched Altavista results for various queries, trained decision tree
Judging relevance through identification of lexical chains • Holliman and Ngai, Fall 2002 • Use WordNet to introduce a level of semantic knowledge to querying/browsing • Builds on “lexical chain” concept from other research: notion that chains of discourse run through documents, consisting of semantically-related words • Compare this approach to standard vector-space model
“Natural language” search • Present an interface that invites users to type in queries in natural language • Find a means of parsing such questions of important categories into full-text queries for the engine. • What is • Why is • How to • Evaluate the relevancy of query answering.
Meta Search Engine • Send user query to several retrieval systems and present combined results to user. • Two problems: • Translate query to query syntax of each engine • Combine results into coherent list • What is the response time/result quality trade-off? (fast methods may give bad results) • How to deal with time-out issues?
Peer-to-Peer Search • Build information retrieval system with distributed collections and query engines. • Advantages: robust (eg, against law enforcement shutdown), fewer update problems, natural for distributed information creation • Challenges • Which nodes to query? • Combination of results from different nodes • Spam / trust
Detecting index spamming • I.e., this isn’t about the junk you get in your mailbox every day! • most ranking IR systems use “frequency of use of words” to determine how good a match a document is • having lots of terms in an area makes you more likely to have the ones users use • There’s a whole industry selling tips and techniques for getting better search engine rankings from manipulating page content
Detecting index spamming • A couple of years ago, lots of “invisible” text in the background color • There is less of that now, as search engines check for it as sign of spam Questions: • Can one use term weighting strategies to make IR system more resistant to spam? • Can one detect and filter pages attempting index spamming? • E.g. a language model run over pages • [From the other direction, are there good ways to hide spam so it can’t be filtered??]
Investigating performance of term weighting functions • Researchers have explored range of families of term weighting functions • Frequently getting rather more complex than the simple version of tf.idf which we will explain in class • Investigate some different term weighting functions and how retrieval performance is affected • One thing that many methods do badly on is correctly relatively ranking documents of very different lengths • This is a ubiquitous web problem, so that might be a good focus
A “real world” term weighting function • “Okapi BM25 weights” are one of the best known weighting schemes • Robertson et al. TREC-3, TREC-4 reports • Discovered mostly through trial and error
Investigating performance of term weighting functions • Using HTML structure: • HTML pages have a good deal of structure (sometimes) – in terms of elements like titles, headings etc. • Can one incorporate HTML parsing and use of such tags to significantly improve term weighting, and hence retrieval performance? • Anchor text, titles, highlighted text, headings etc. • Eg: Google
Language identification • People commonly want to see pages in languages they can read • But sometimes words (esp. names) are the same in different languages • And knowing the language has other uses: • For allowing use of segmentation, stemming, query expansion, … • Write a system that determines the language of a web page
Language identification • Notes: • There may be a character encoding in the head of the document, but you often can’t trust it, or it may not uniquely determine the language • Character n-gram level or function-word based techniques are often effective • Pages may have content in multiple languages • Google doesn’t do this that well for some languages (see Advanced Search page) • I searched for pages containing “WWW” [many do, not really a language hint!] in Indonesian, and here’s what I got…