Download
1 / 6
60 likes | 66 Views
The core model introduces TVI and TDS, where all TDSs associated with a TVI are considered alternative representations of the same time-based information. Similarity Clusters allow for more precision in identifying suitable TDS alternatives. Ancestry relationships between TDSs can also be identified. Explore the various scenarios and relationships within the model.

E N D
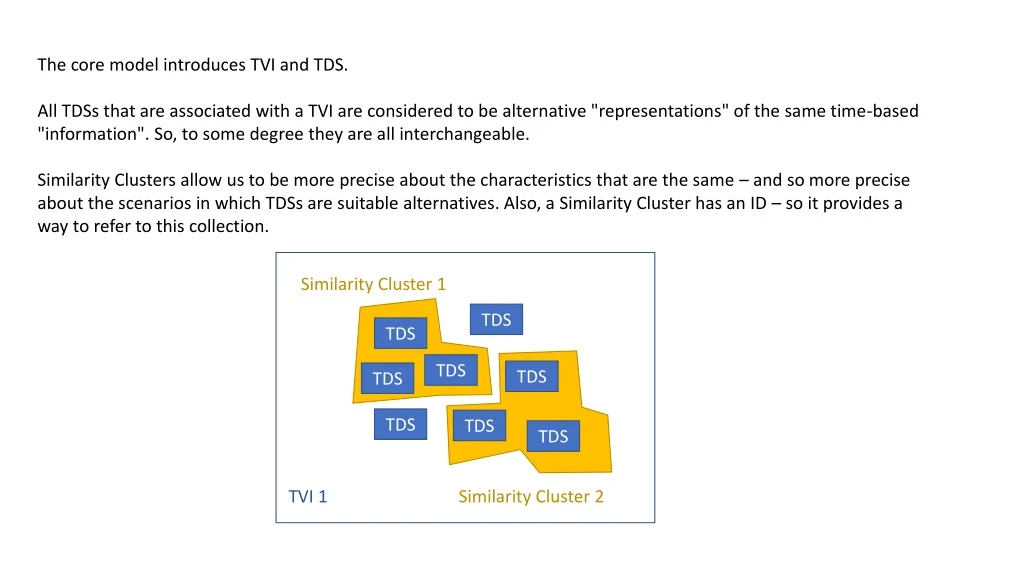
The core model introduces TVI and TDS. All TDSs that are associated with a TVI are considered to be alternative "representations" of the same time-based "information". So, to some degree they are all interchangeable. Similarity Clusters allow us to be more precise about the characteristics that are the same – and so more precise about the scenarios in which TDSs are suitable alternatives. Also, a Similarity Cluster has an ID – so it provides a way to refer to this collection. Similarity Cluster 1 TDS TDS TDS TDS TDS TDS TDS TDS TVI 1 Similarity Cluster 2
There are also other reasons to group things together… Similarity Cluster 1 Similarity Cluster 3 TDS TDS AND TDS TDS TDS TDS TVI 1 TVI 2 Group 1 … for example, grouping together the audio and video from a camera because we want a convenient way to refer to both of these together (a group with an ID) …
…or maybe grouping together alternative pieces of content that fulfil the same purpose, such as subtitles in English (in various formats) and subtitles in French (in various formats). Similarity Cluster 5 Similarity Cluster 7 TDS TDS TDS OR TDS TDS TDS TVI 3 TVI 4 Group 2 Again, here we have a group with an ID – so this collection can be referred to easily.
Similarity Cluster C Similarity Cluster A TDS Format XYZ TDS TDS TDS Format XYZ TDS TDS TVI 2 TVI 1 Similarity Cluster B TDS TDS TDS Format XYZ TVI 5 It may also be useful to be able to identify a collection that is similar in some other way. For example, here three TDSs have been identified as using a particular format (maybe a particular video codec profile with particular settings). This format might be identified with an ID. For example, it might then be easy to refer to the collection of TDSs that can be handled by a particular decoder.
Another kind of useful relationship is ancestry. Similarity Cluster 9 TDS TDS TDS TDS TDS operation TDS TDS TDS TVI 5 Similarity Cluster 10 For example, two TDSs may have an ancestry relationship – maybe one TDS was transcoded to produce the other TDS.
Similarity Cluster 11 operation TDS TDS TDS TDS TDS TDS Similarity Cluster 10 TVI 5 TVI 6 Maybe an ancestry relationship is expressed between two Similarity Clusters associated with different TVIs. This might express that the content on the left was time-shifted to generate the content on the right, but was otherwise unchanged (so new Time Values were produced for the new TDSs but nothing else changed). In this case, ancestral relationships are also implied between the TDSs, as shown.